9 - fluid添加看板娘 参考:link (1) 下载 张书樵大神的项目,解压到本地博客目录的 themes/fluid/source/alec_diy/ 下,修改文件夹名为 live2d-widget (2)在主题配置文件的custom_js和custom_css中加入: 12345678custom_js: # live2d的js文件(2) - /alec_diy/live2d-widget/autoloa 2023-02-05 工具笔记 > hexo > 主题 > fluid
8 - fluid添加音乐页面和音乐播放器 [√] 添加悬浮音乐播放器 在fluid的主题配置文件中,提供了自定义html的位置,因此直接在主题配置文件中添加html代码 1234567custom_html: ' <!--音乐--> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/aplayer@1.10.1/d 2023-02-05 工具笔记 > hexo > 主题 > fluid
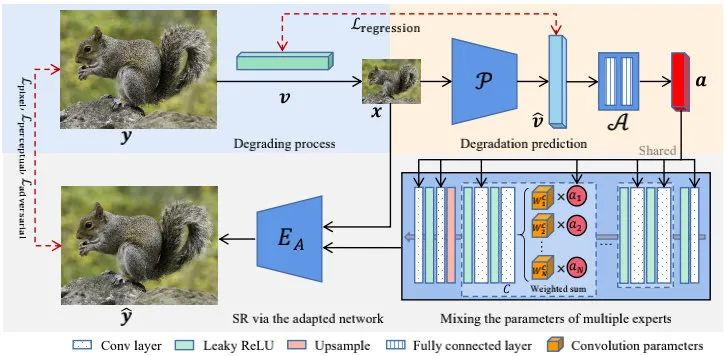
055 - 文章阅读笔记:【DASR】盲超分两大流派集成大者!- 微信公众号 - AIWalker 原文链接: DASR: 盲超分两大流派集成大者! - 微信公众号 - AIWalker 2022-03-29 22:00 ps:本文为依据个人日常阅读习惯,在原文的基础上记录阅读进度、记录个人想法和收获所写,关于原文一切内容的著作权全部归原作者所有。 【本文要点】 对每个输入图像自适应估计其退化信息 点1:退化自适应预测网络 - 采用一个很小的回归网络预测输入图像的退化参数 点2:带多专家 2023-02-04 深度学习技术栈 > 超分辨率重建 > 文章学习 #盲超分 #深度学习 #人工智能 #图像处理 #超分辨率重建
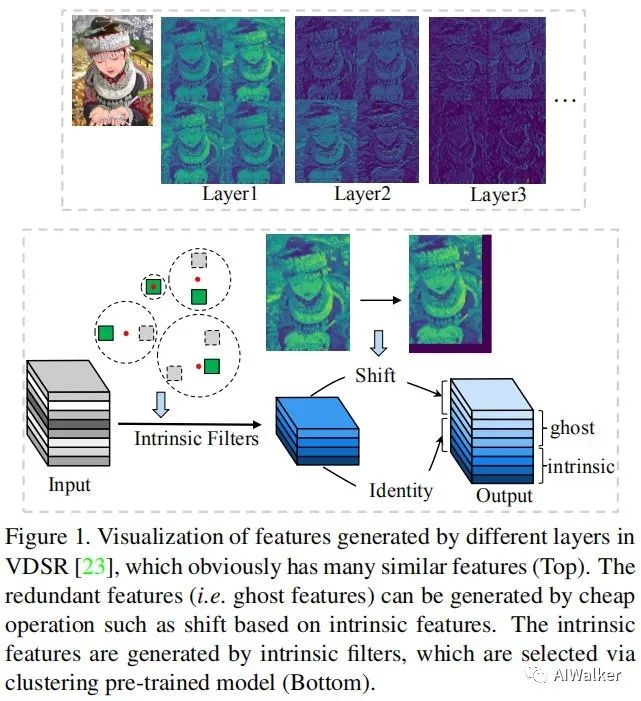
054 - 文章阅读笔记:GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSRepVGG - 微信公众号 - AIWalker 原文链接: GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSRepVGG - 微信公众号 - AIWalker 2021-01-22 22:00 ps:本文为依据个人日常阅读习惯,在原文的基础上记录阅读进度、记录个人想法和收获所写,关于原文一切内容的著作权全部归原作者所有。 【要点记录】 轻量化超分方案 结合了GhostNet中的特征融合思想,同时考虑了 2023-02-04 深度学习技术栈 > 超分辨率重建 > 文章学习 #深度学习 #人工智能 #超分辨率重建
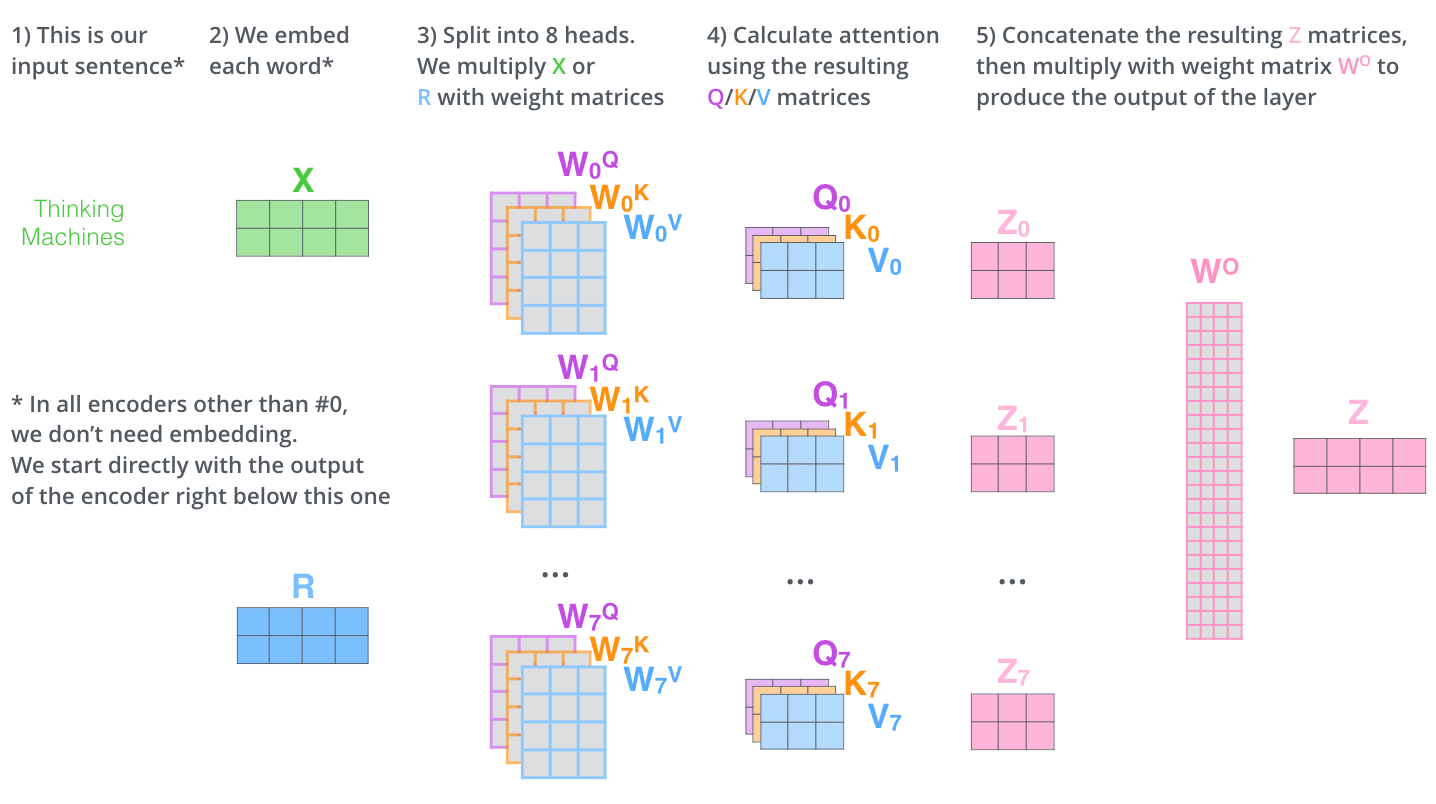
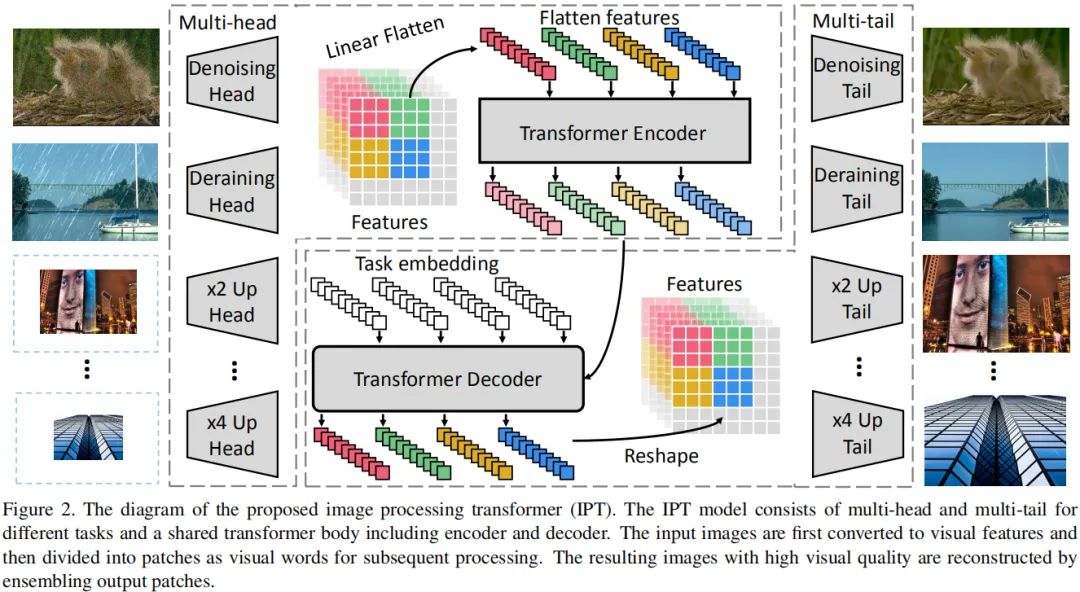
007 - 文章阅读笔记:学习Transformer:自注意力与多头自注意力的原理及实现 - CSDN - 此人姓于名叫罩百灵 原文链接: 学习Transformer:自注意力与多头自注意力的原理及实现 - CSDN - 此人姓于名叫罩百灵 2022-07-23 00:16:12 [√] 前言 自从Transformer[3]模型在NLP领域问世后,基于Transformer的深度学习模型性能逐渐在NLP和CV领域(Vision Transformer)取得了令人惊叹的提升。本文的主要目的是介绍经典Transforme 2023-02-03 深度学习技术栈 > 深度学习 > 文章学习 #深度学习 #人工智能 #计算机视觉 #注意力机制 #transformer
001 - 文章阅读笔记:什么都可以以后再说,体检为什么不可以? - 少数派 - 少数派编辑部 原文链接: 什么都可以以后再说,体检为什么不可以? - 少数派 - 少数派编辑部 2023年01 月 12 日 ps:本文为依据个人日常阅读习惯,在原文的基础上记录阅读进度、记录个人想法和收获所写,关于原文一切内容的著作权全部归原作者所有。 反向传播推导 - 简书 (jianshu.com) 2023-01-29 深度学习技术栈 > 深度学习 > 文章学习 #深度学习 #机器学习
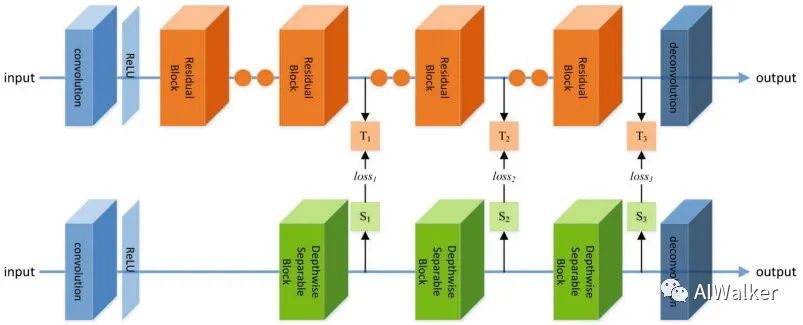
052 - 文章阅读笔记:图像超分中的那些知识蒸馏 - 微信公众号:AIWalker - HappyAIWalker 原文链接: 图像超分中的那些知识蒸馏 - 微信公众号:AIWalker - HappyAIWalker 2021-01-21 22:00 alec: distill = 蒸馏 dis,till(直到没了) [√] 概述 本文对三篇知识蒸馏在图像超分中的应用进行了简单的总结,主要包含: SRKD:它将最基本的知识蒸馏直接应用到图像超分中,整体思想分类网络中的蒸馏方式基本一致 2023-01-27 深度学习技术栈 > 超分辨率重建 > 文章学习 #超分辨率重建 #知识蒸馏
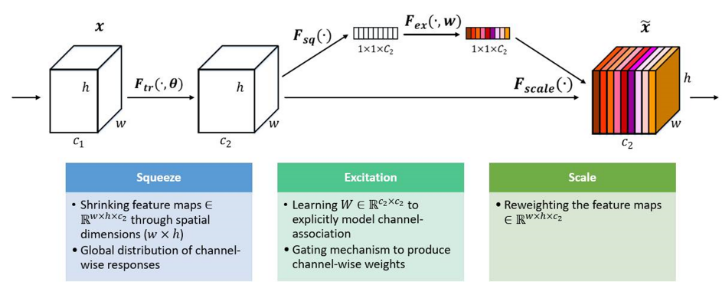
004 - 文章阅读笔记:深度学习(8)CNN中的通道注意力机制(SEnet、ECAnet),附Tensorflow完整代码 - CSDN - 立Sir 原文链接: 深度学习(8)CNN中的通道注意力机制(SEnet、ECAnet),附Tensorflow完整代码 - CSDN - 立Sir 已于 2022-06-03 16:31:58 修改 版权声明:本文为CSDN博主「立Sir」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/dgvv4/article/ 2023-01-27 深度学习技术栈 > 深度学习 > 文章学习 #深度学习 #注意力机制
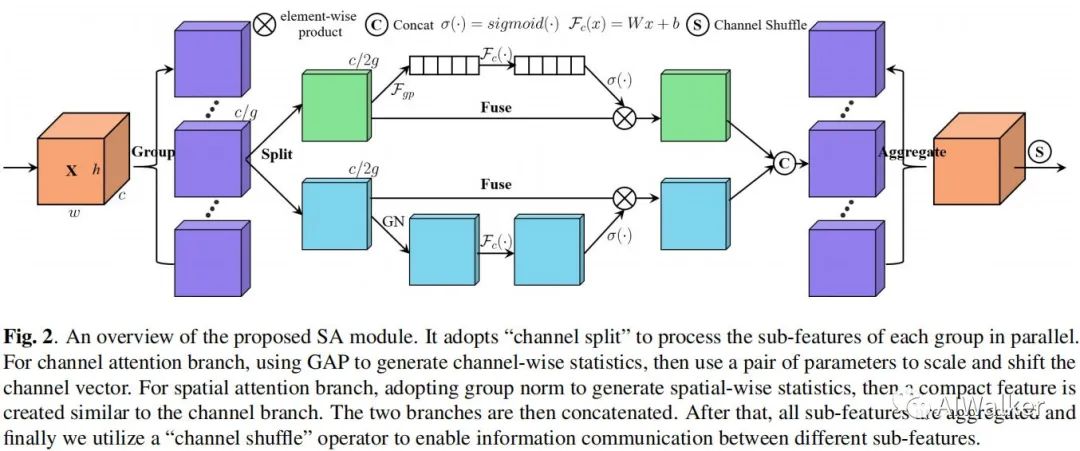
051 - 文章阅读笔记:SANet|融合空域与通道注意力,南京大学提出置换注意力机制 - AIWalker(SA-NET:SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS) - HappyAIWalker 原文链接: SANet|融合空域与通道注意力,南京大学提出置换注意力机制 - AIWalker - HappyAIWalker 2021-02-04 22:00 ==论文简介== 提出了一种新的注意力机制:置换注意力机制。它在空域注意力与通道注意力的基础上,引入了特征分组与通道置换,得到了一种超轻量型的注意力机制。 alec: shuffle,混 2023-01-27 深度学习技术栈 > 超分辨率重建 > 文章学习 #深度学习 #注意力机制
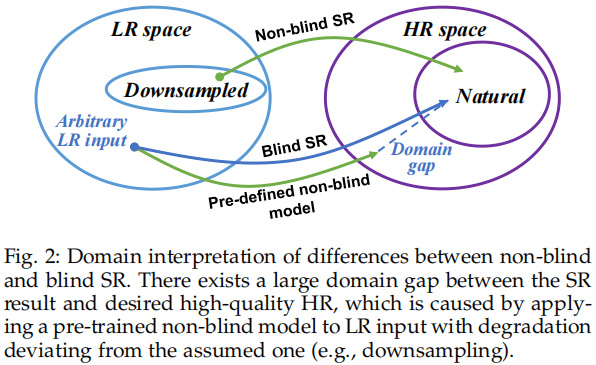
050 - 文章阅读笔记:最新!基于深度学习的盲图像超分技术一览 - 极市平台 - Happy 原文链接: 最新!基于深度学习的盲图像超分技术一览 - 极市平台 - Happy 发布于 2021-07-12 10:33 整理到思维导图 [√] 论文信息 盲图像超分旨在对未知退化类型的低分辨率图像进行超分增强,由于其对于实际应用的重要促进作用而受到越来越多的关注。近来,有许多新颖、高效方案(主要是深度学习方案)已被提出。 尽管经过学术界、工业界多年的努力,盲图像超分仍然是一个极具挑 2023-01-26 深度学习技术栈 > 超分辨率重建 > 文章学习 #盲超分 #深度学习 #图像处理 #超分辨率重建
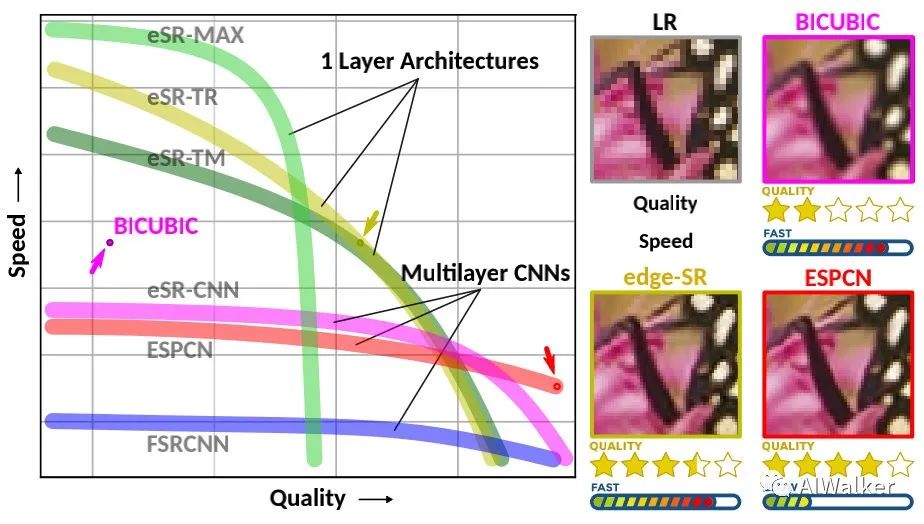
049 - 文章阅读笔记:一层卷积能做啥?BOE告诉你:一层卷积可以做超分! - 公众号:AIWalker - Happy 原文链接: 一层卷积能做啥?BOE告诉你:一层卷积可以做超分!(edge SR: SuperResolution For The Masses) - 公众号:AIWalker - Happy 2021-09-25 20:00 本文为端侧超分提出了一个极具价值的参考点 本文的几点贡献: 提出了几种一层架构以弥补经典与深度学习上采样之间的空白; 在1185中深度学习架构中进行了穷举搜索,可参考 2023-01-26 深度学习技术栈 > 超分辨率重建 > 文章学习 #深度学习 #超分辨率重建
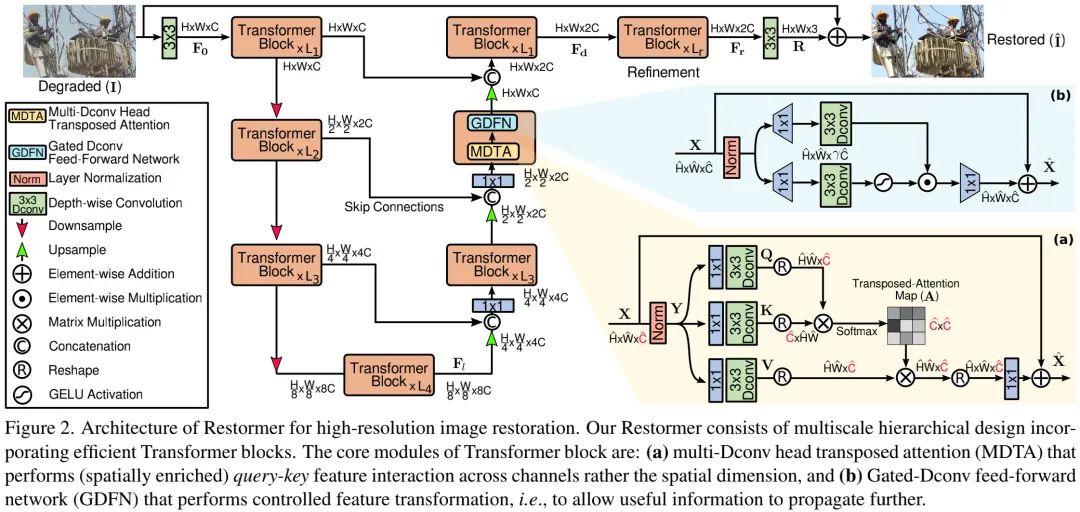
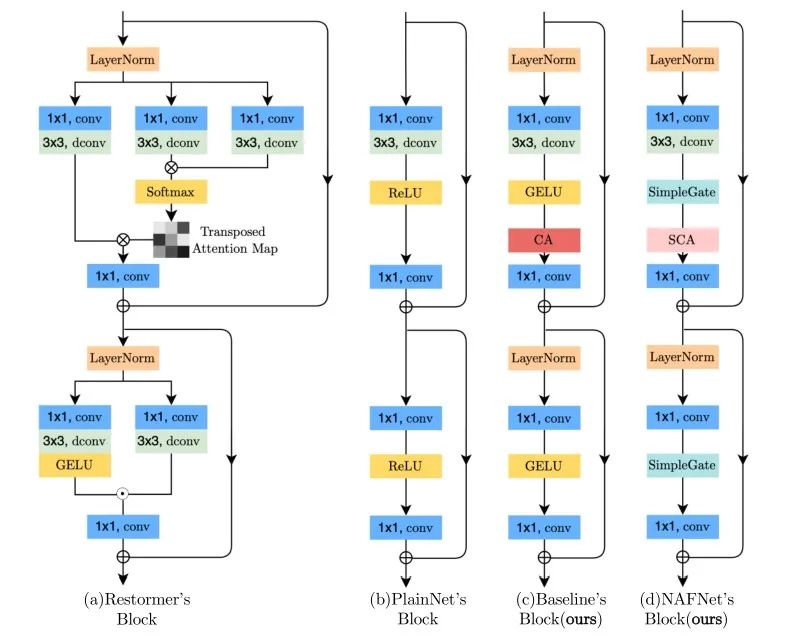
048-文章阅读笔记:CVPR2022-Restormer:刷新多个low-level任务指标-公众号:AIWalker-Happy 原文链接: CVPR2022 | Restormer: 刷新多个low-level任务指标 - 公众号:AIWalker - Happy 整理到思维导图 [√] 论文信息 arXiv:https://arXiv.org/abs/2111.09881 code:https://github.com/swz30/Restormer 本文是MPRNet与MIRNet的作者在图像复原领域的又 2023-01-25 深度学习技术栈 > 超分辨率重建 > 文章学习 #transformer #超分辨率重建
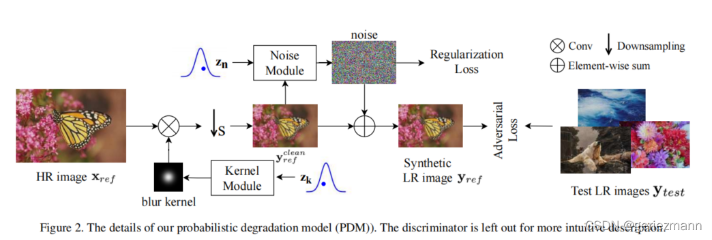
047 - 文章阅读笔记:学习盲图像超分辨率的退化分布 - CSDN - geriezmann 原文链接: 学习盲图像超分辨率的退化分布 - CSDN - geriezmann 于 2022-04-08 17:16:52 版权声明:本文为CSDN博主「geriezmann」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/adhkcnbk/article/details/124046231 学习盲图像 2023-01-23 深度学习技术栈 > 超分辨率重建 > 文章学习 #计算机视觉 #超分辨率重建
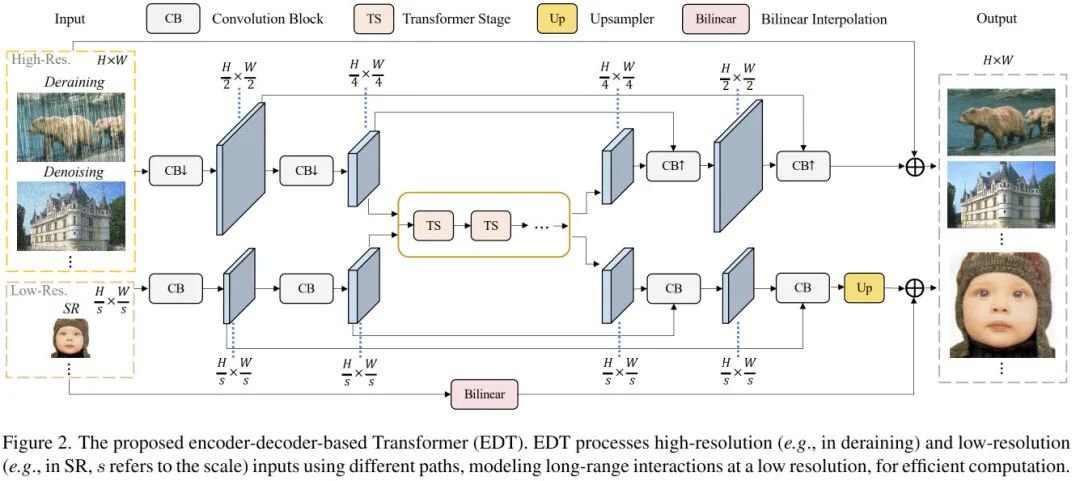
046 - 文章阅读笔记:EDT:超越SwinIR,Transformer再一次占领low-level三大任务 原文链接: EDT:超越SwinIR,Transformer再一次占领low-level三大任务 2021-12-21 22:33 [√] 论文信息 alec: “用于下游视觉任务的高效transformer和图像预训练” EDT的性能超过IPT和SwinIR 本文主要是针对图像预训练任务进行了深入研究。 在超分任务中,预训练可以为更高层引入更多局部信息,进而产生显著性能提升。 多任务预 2023-01-21 深度学习技术栈 > 超分辨率重建 > 文章学习 #注意力机制 #transformer #超分辨率重建
045 - 文章阅读笔记:XPixel团队提出混合注意力机制HAT:Transformer超分性能大涨1dB - Aminer - 数据派THU 原文链接: XPixel团队提出混合注意力机制HAT:Transformer超分性能大涨1dB - Aminer - 数据派THU 2022-06-09 12:16 关键词: 注意力,性能,窗口尺寸,像素,训练策略 [√] 论文信息 该方法结合了通道注意力,自注意力以及一种新提出的重叠交叉注意力等多种注意力机制。 本文介绍作者提出的一种基于混合注意机制的Transformer(Hybrid A 2023-01-21 深度学习技术栈 > 超分辨率重建 > 文章学习 #注意力机制 #超分辨率重建
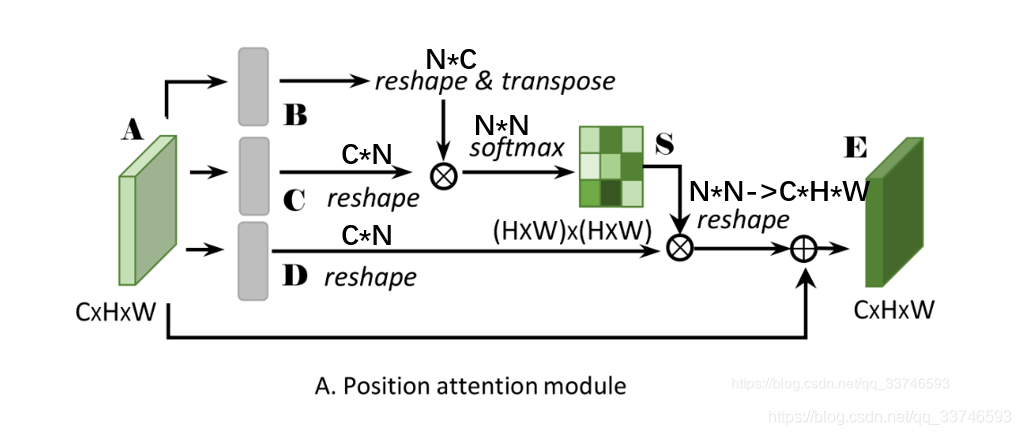
003 - 文章阅读笔记:位置注意力和通道注意力 参考:位置注意力和通道注意力机制 - CSDN - shu_0233 - 深度学习 [√] Position Attention Module 捕获特征图的任意两个位置之间的空间依赖,对于某个特定的特征,被所有位置上的特征加权和更新。权重为相应的两个位置之间的特征相似性。因此,任何两个现有相似特征的位置可以相互贡献提升,而不管它们之间的距离.。 alec: 位置注意力计算的是特征图的任意 2023-01-20 深度学习技术栈 > 深度学习 > 文章学习 #深度学习 #注意力机制
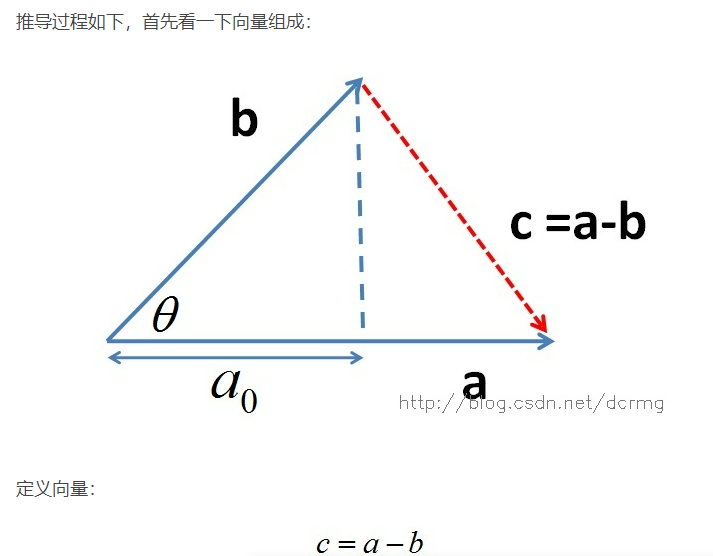
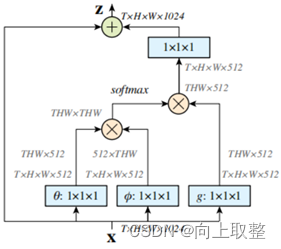
002 - 文章阅读笔记:总结部分注意力机制 - CSDN - 向上取整 - 专栏:计算机视觉 参考: 总结部分注意力机制 - CSDN - 向上取整 - 专栏:计算机视觉 于 2022-10-20 14:00:55 [√] 部分注意力机制 [√] 1 - 空间注意力 [√] 1.1 - 自注意力 alec: 自注意力机制,是通过QK相乘,然后通过softmax激活函数,得到注意力权重,然后再乘上V得到注意力加权后的数据。 自注意力计算时通常分为三步: 第一步是将query 2023-01-20 深度学习技术栈 > 深度学习 > 文章学习 #深度学习 #计算机视觉 #注意力机制
044 - 文章阅读笔记:NAFNet:图像去噪,去模糊新SOTA!荣获NTIRE 2022 超分辨率冠军方案! - CSDN - 华为云开发者联盟 原文链接: NAFNet:图像去噪,去模糊新SOTA!荣获NTIRE 2022 超分辨率冠军方案! - CSDN - 华为云开发者联盟 2022-05-30 14:00:02 导读:2022年4月,旷视研究院发表了一种基于图像恢复任务的全新网络结构,它在SIDD和GoPro数据集上进行训练和测试,该网络结构实现了在图像去噪任务和图像去模糊任务上的新SOTA。具体计算量与实验效果如下图所示:不仅 2023-01-20 深度学习技术栈 > 超分辨率重建 > 文章学习
001 - 文章阅读笔记:深度可分离卷积(Depthwise seperable convolution) - CSDN - 深度学习 - 冰雪棋书 原文链接: 深度可分离卷积(Depthwise seperable convolution) - CSDN - 深度学习 - 冰雪棋书 于 2022-08-25 15:53:15 发布 alec: 深度可分离卷积的目的是为了轻量化网络 组卷积的目的也是为了轻量化网络 [√] 一、深度可分离卷积(Depthwise separable convolution) alec: separ 2023-01-20 深度学习技术栈 > 深度学习 > 文章学习 #轻量化网络
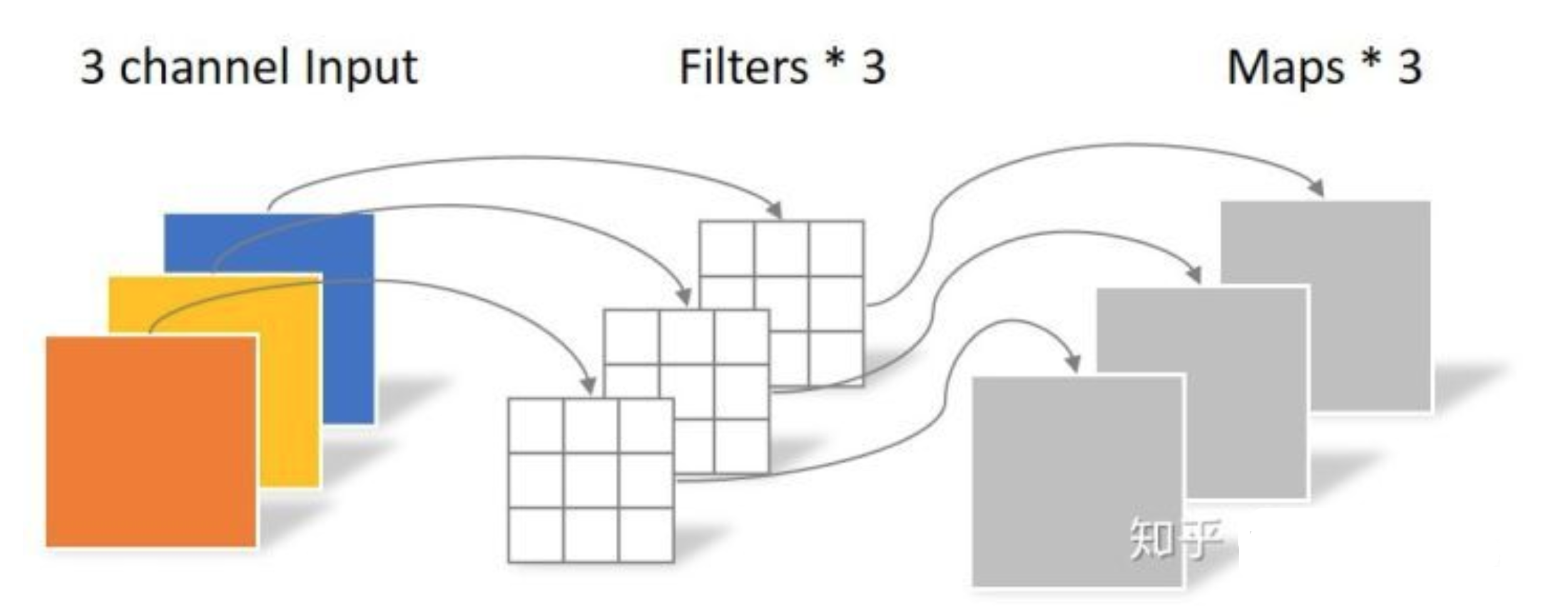
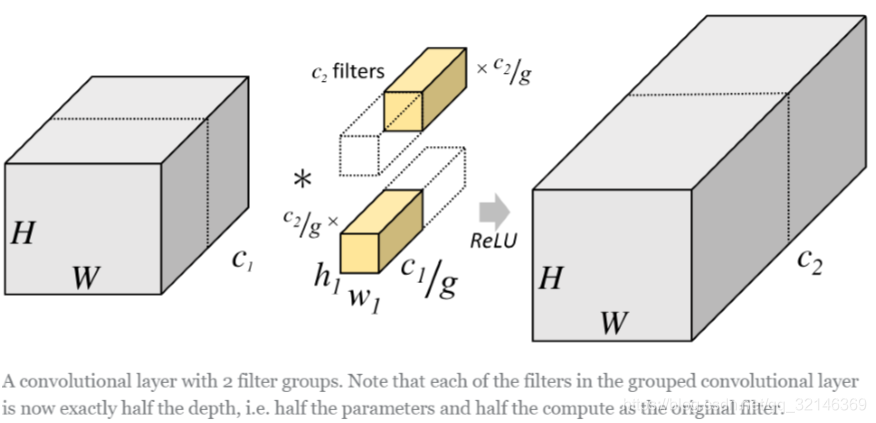
043 - 文章阅读笔记:组卷积 原文链接: 组卷积(group convolution) - CSDN - 专栏:深度学习 - 草帽-路飞 卷积中的分组卷积 - CSDN - 专栏:深度学习 - 草帽-路飞 于 2020-05-23 23:15:25 发布 说明分组卷积之前我们用一张图来体会一下一般的卷积操作。 一般的卷积会对输入数据的整体一起做卷积操作,即输入数据:H1×W1×C1;而卷积核大小为h1×w1,通道 为C1 2023-01-20 深度学习技术栈 > 超分辨率重建 > 文章学习 #CNN #卷积
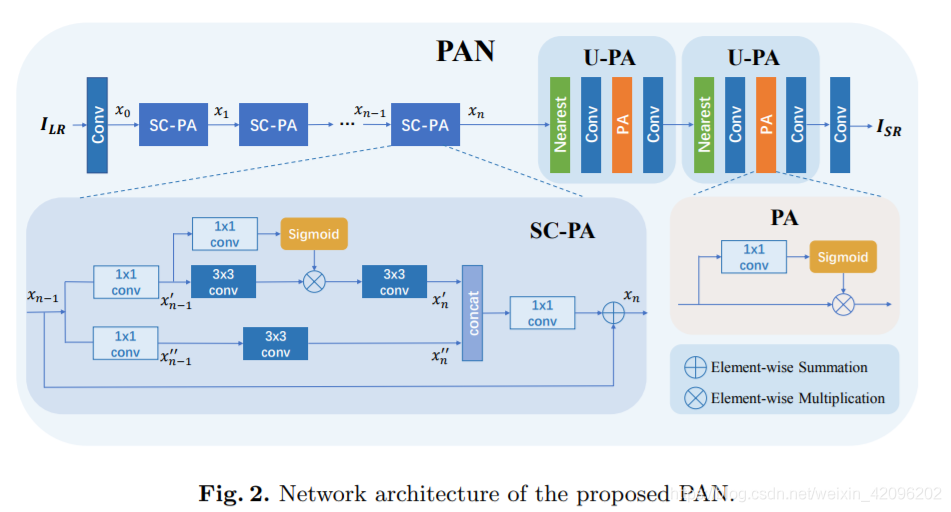
042 - 文章阅读笔记:ECCV2020 Workshop-PAN-270k参数量SISR网络 | Efficient Image Super-Resolution Using Pixel Attention - CSDN - chenzy_hust 原文链接: ECCV2020 Workshop-PAN-270k参数量SISR网络 | Efficient Image Super-Resolution Using Pixel Attention - CSDN - chenzy_hust 于 2020-10-08 12:21:53 [√] 论文信息 只说了参数量却没有比较速度,此外PA应用在大的网络中会降低性能!论文地址:https://ar 2023-01-19 深度学习技术栈 > 超分辨率重建 > 文章学习 #注意力机制 #超分辨率重建
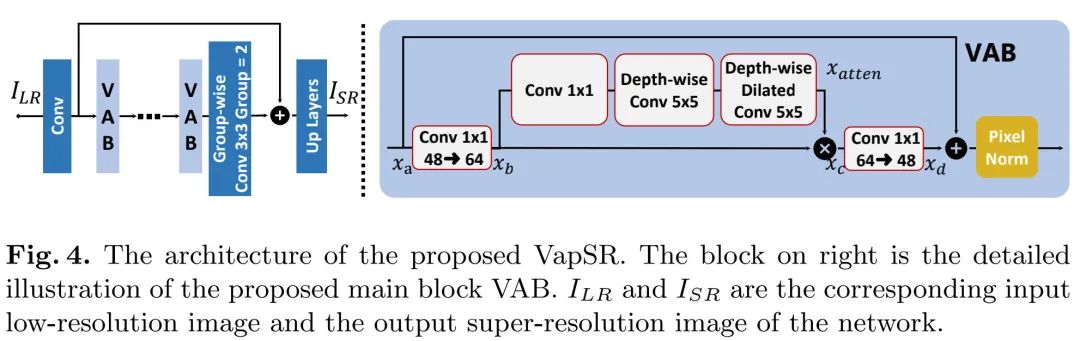
041 - 文章阅读笔记:VapSR | 手把手教你改进PAN,董超团队提出超大感受野注意力超分方案,已开源! - 2022-10-24 08:00 - AIWalker 原文链接:VapSR | 手把手教你改进PAN,董超团队提出超大感受野注意力超分方案,已开源! - 2022-10-24 08:00 - AIWalker 2022-10-24 08:00 [√] 论文信息 中文名称:使用超大感受野的注意力的高效图像超分 paper https://arxiv.org/abs/2210.05960 code https://github.com/zhoumum 2023-01-19 深度学习技术栈 > 超分辨率重建 > 文章学习 #注意力机制 #超分辨率重建
040 - 文章阅读笔记:ACNet|增强局部显著特征,哈工大左旺孟老师团队提出非对称卷积用于图像超分 - AIWalker 原文链接:ACNet|增强局部显著特征,哈工大左旺孟老师团队提出非对称卷积用于图像超分 - AIWalker 2021-04-04 21:30 [√] 文章信息 Paper:https://arxiv.org/abs/2103.13634 Code:https://github.com/hellloxiaotian/ACNet 本文是哈工大左旺孟老师团队在图像超分方面的最新工作,已被IEE 2023-01-19 深度学习技术栈 > 超分辨率重建 > 文章学习 #超分辨率重建
039 - 文章阅读笔记:AIM2020-ESR 冠军方案解读:引入注意力模块 ESA,实现高效轻量的超分网络(附代码实现) - 极市平台 - ExtremeMart AIM2020-ESR 冠军方案解读:引入注意力模块 ESA,实现高效轻量的超分网络(附代码实现) - 极市平台 - ExtremeMart 2020-09-30 [√] 文章信息 本文首发自公众号极市平台(微信公众号ID:extrememart),作者 @Happy,转载需获授权。 导读:该文是南京大学提出的一种轻量&高效图像超分网络,它获得了AIM20-ESR竞赛的冠军。它在I 2023-01-17 深度学习技术栈 > 超分辨率重建 > 文章学习 #深度学习 #超分辨率重建