044 - 文章阅读笔记:NAFNet:图像去噪,去模糊新SOTA!荣获NTIRE 2022 超分辨率冠军方案! - CSDN - 华为云开发者联盟
本文最后更新于:3 个月前
原文链接:
NAFNet:图像去噪,去模糊新SOTA!荣获NTIRE 2022 超分辨率冠军方案! - CSDN - 华为云开发者联盟
2022-05-30 14:00:02
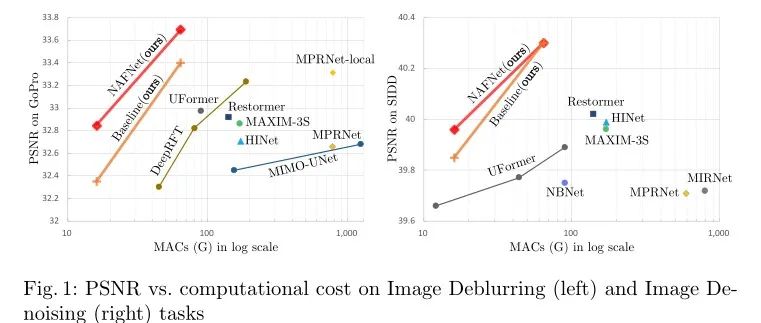
导读:2022年4月,旷视研究院发表了一种基于图像恢复任务的全新网络结构,它在SIDD和GoPro数据集上进行训练和测试,该网络结构实现了在图像去噪任务和图像去模糊任务上的新SOTA。具体计算量与实验效果如下图所示:不仅如此,基于NAFNet,旷视还提出了一种针对超分辨率的NAFNet变体结构,该网络为NAFNet-SR。NAFNet-SR在NTIRE 2022 超分辨率…
[√] 论文信息

导读:2022年4月,旷视研究院发表了一种基于图像恢复任务的全新网络结构,它在SIDD和GoPro数据集上进行训练和测试,该网络结构实现了在图像去噪任务和图像去模糊任务上的新SOTA。具体计算量与实验效果如下图所示:
alec:
- MACs, MAdds: (Multiply–Accumulate Operations) 即乘加累积操作数,常常与FLOPs概念混淆,实际上1MACs包含一个乘法操作与一个加法操作,大约包含2FLOPs。通常MACs与FLOPs存在一个2倍的关系。MACs和MAdds说的是一个东西。
不仅如此,基于NAFNet,旷视还提出了一种针对超分辨率的NAFNet变体结构,该网络为NAFNet-SR。NAFNet-SR在NTIRE 2022 超分辨率比赛中荣获冠军方案。本文将从模型的组成、主要结构以及代码的训练和配置等方面进行详细介绍!
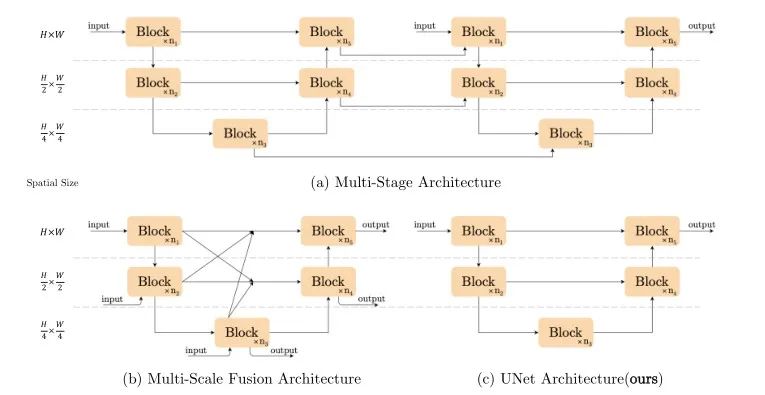
上图给出了三种主流的图像恢复主流网络架构设计方案,包含多阶段特征提取、多尺度融合架构以及经典的UNet架构。本文为了最大化减少模型每个模块间进行交互的复杂度,直接采用了含有Short Cut的UNet架构。NAFNet在网络架构上实现了最大精简原则!
项目地址:https://github.com/murufeng/FUIR
[√] 核心模块与代码
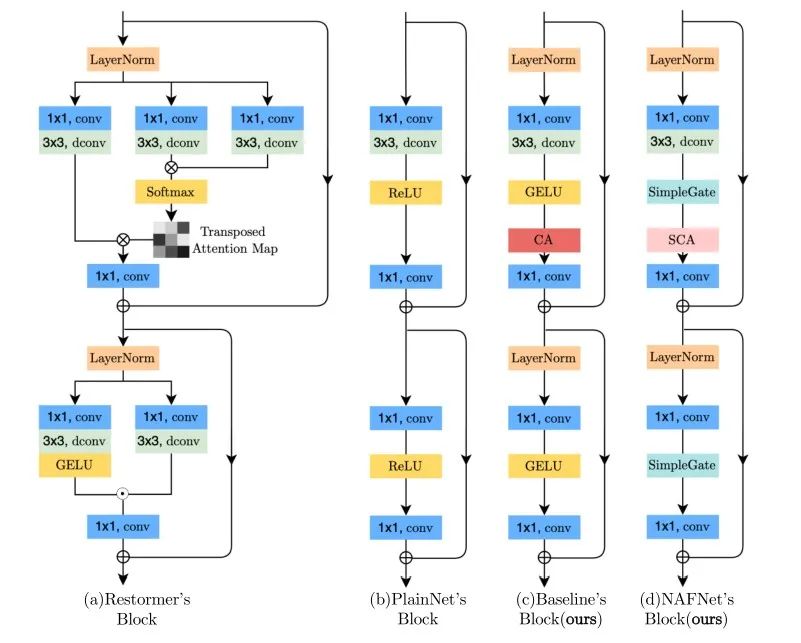
基于Restormer的模块示意图,NAFNet设计另一种最简洁的模块方案,具体体现在:
- 借鉴Trasnformer中使用LN可以使得训练更平滑。NAFNet同样引入LN操作,在图像去噪和去模糊数据集上带来了显著的性能增益。
- 在Baseline方案中使用GELU和CA联合替换ReLU,GELU可以保持降噪性能相当且大幅提升去模糊性能。
- 由于通道注意力的有效性已在多个图像复原任务中得到验证。本文提出了两种新的注意力模块组成即CA和SCA模块,具体如下所示:

alec:
- LayerNorm可以使得训练更平滑
- CA = 通道注意力,SCA = 简单通道注意力
- SCA = 将CA的注意力分支中的卷积 + 激活函数的结构替换为1x1卷积
- Simple Gate 可以替换一个激活函数,能够实现性能的提升
其中SCA(见上图b)直接利用1x1卷积操作来实现通道间的信息交换。而SimpleGate(见上图c)则直接将特征沿通道维度分成两部分并相乘。采用所提SimpleGate替换第二个模块中的GELU进行,实现了显著的性能提升。

alec:
- 对比于PlainNet,可以看出,规范化方式LN、激活函数GELU、注意力机制CA是有效的,能够提升性能
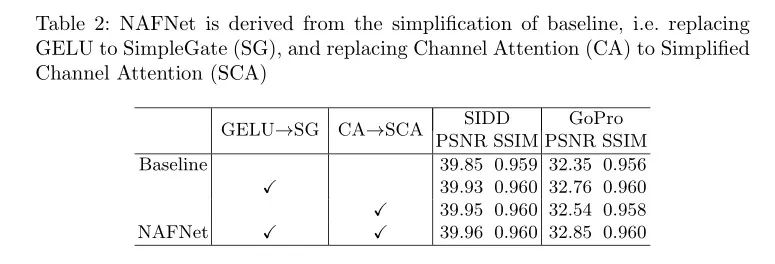
alec:
- NAFNet在baseline的基础上简化了(在模型简化的基础上还能提高性能)
- 将GELU替换为了simple gate,将CA替换为了SCA
NAFBlock构成代码如下:
1 | |
[√] 模型训练与实验结果
[√] 图像去噪任务(SIDD数据集)

[√] 图像去模糊任务(GoPRO数据集)
