8 - 注意力机制
本文最后更新于:3 个月前
[√] 8.0 - 注意力机制与外部记忆
alec:
- 注意力机制和外部记忆是两个部件,部件的意思是能够和其它的网络架构相融合。
- transformer是RNN中序列到序列的模型的一个实现
[√] 内容
alec:
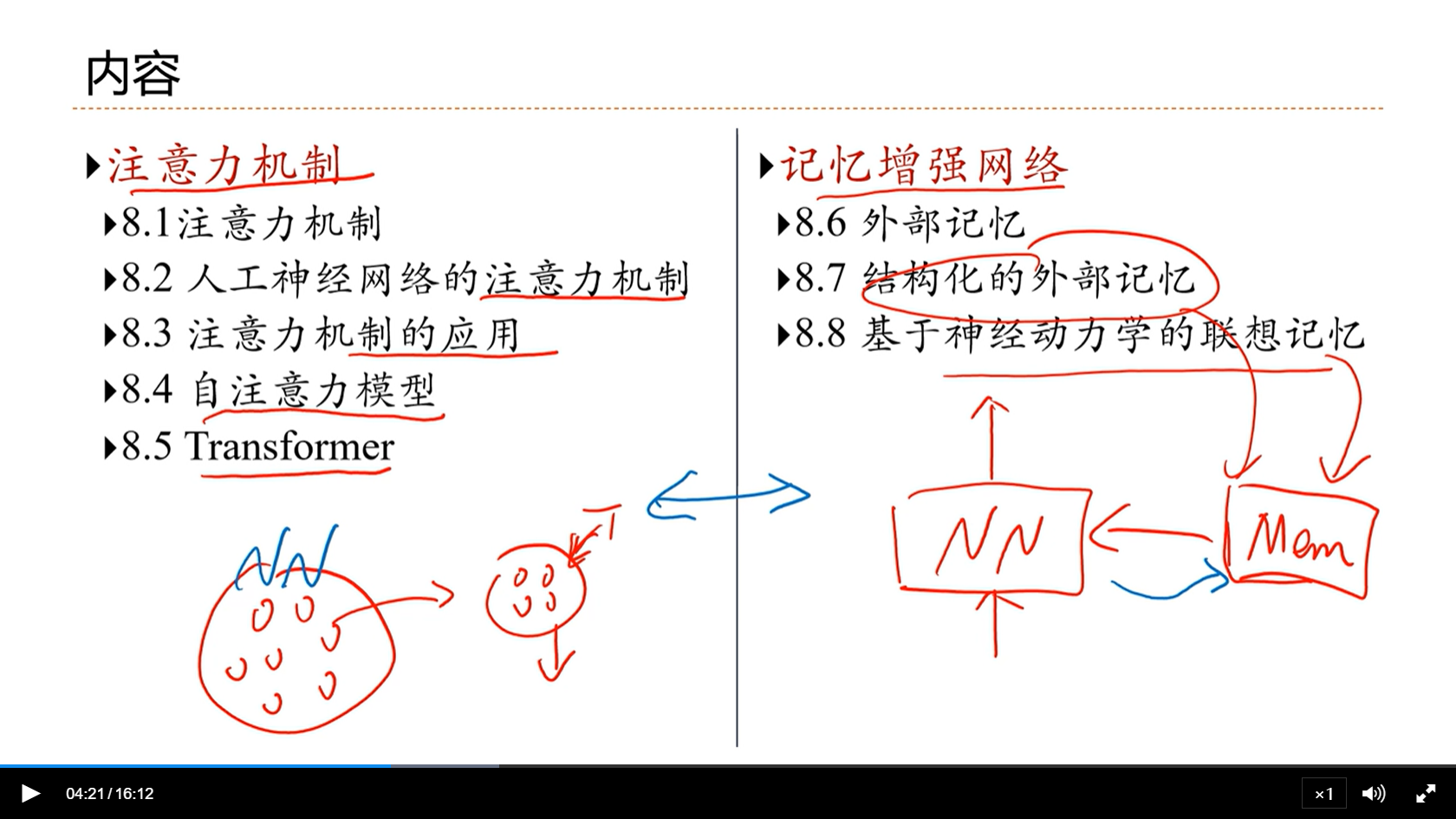
- 注意力机制能够筛选重要的信息,并且大幅的降低计算量
- 自注意力模型是基于注意力机制的一个非常流行的模型
- transformer是自注意力模型的一个具体的实现
alec:
- 记忆增强网络是给神经网络增加外部记忆,使得可以增强网络的记忆能力
- 外部记忆的实现有两种方式:
- 基于机构化的外部记忆
- 基于神经动力学的联想记忆
alec:
- 注意力机制和记忆增强网络是相辅相成的
- NN想要从外部记忆中选择和当前相关的记忆,就需要注意力机制
- 很多的场景中,外部的信息也可以看做外部的记忆
[√] 网络能力
alec:
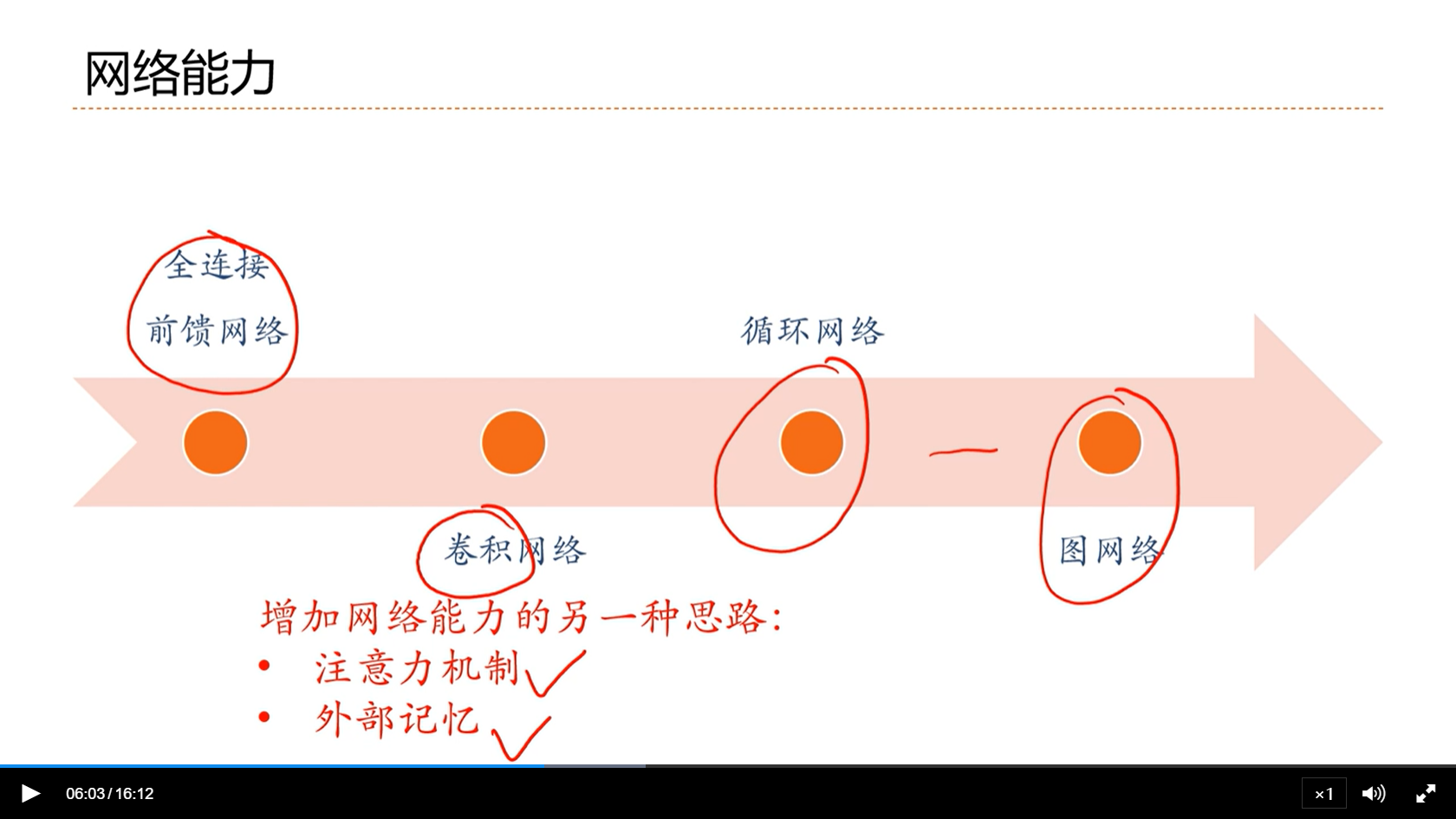
- FNN的缺点是网络密集连接,使得在少量数据上非常难学,很容易过拟合
- CNN相对FNN,更优
- RNN通过引入内部的记忆,使得网络能够处理时序相关的数据
- 扩展到图网络,进一步提升网络能力
增加网络能力的另一种思路:
- 注意力机制
- 外部记忆
[√] 例子:阅读理解

alec:
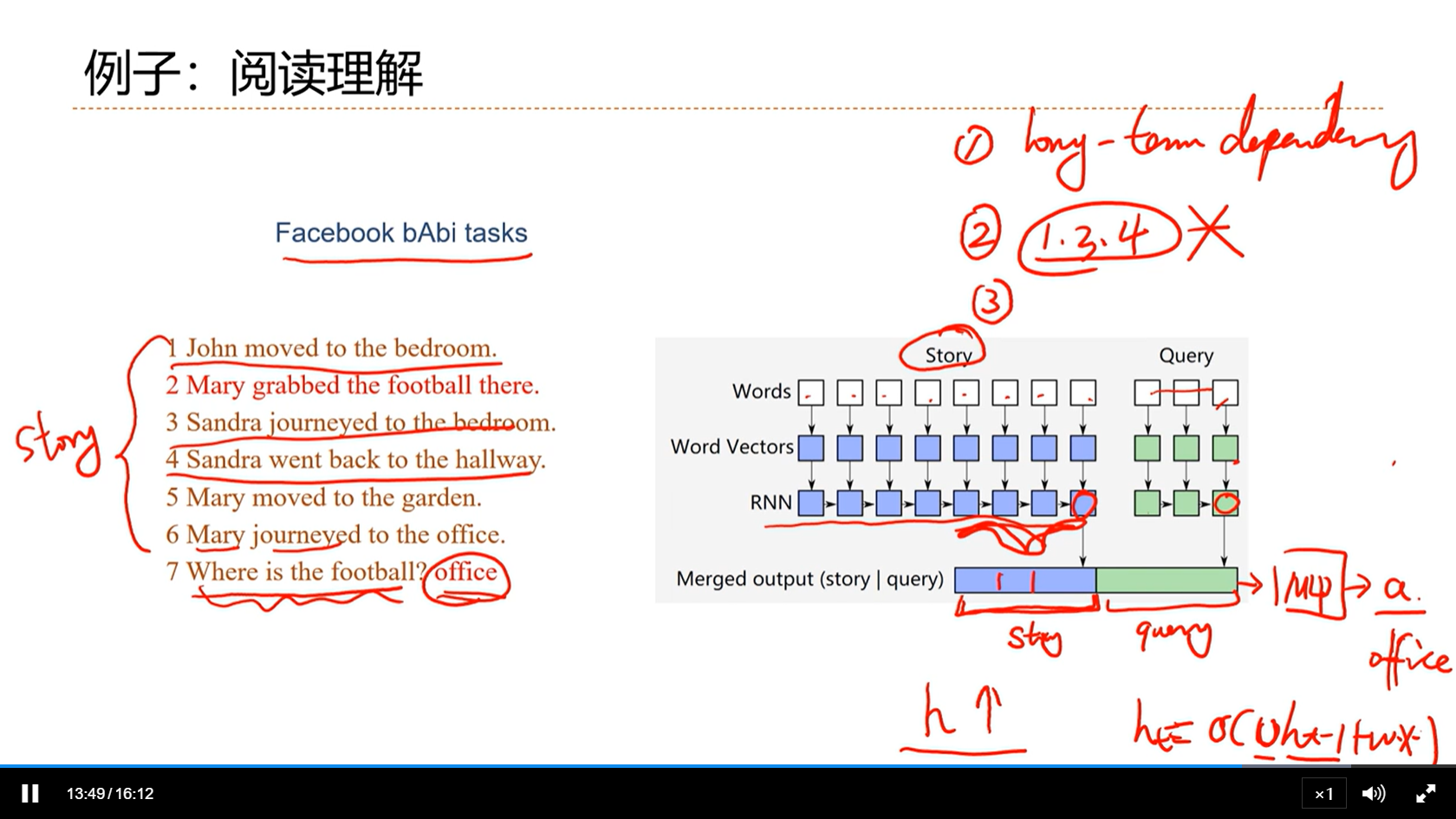
- 上图这个段落很长,全部编码不现实,严重的长程依赖问题。因此这个时候就需要找一些问题相关的句子,这里就的机制就类似于信息筛选/注意力机制。
[√] 8.1 - 注意力机制
[√] 大脑中的信息超载问题

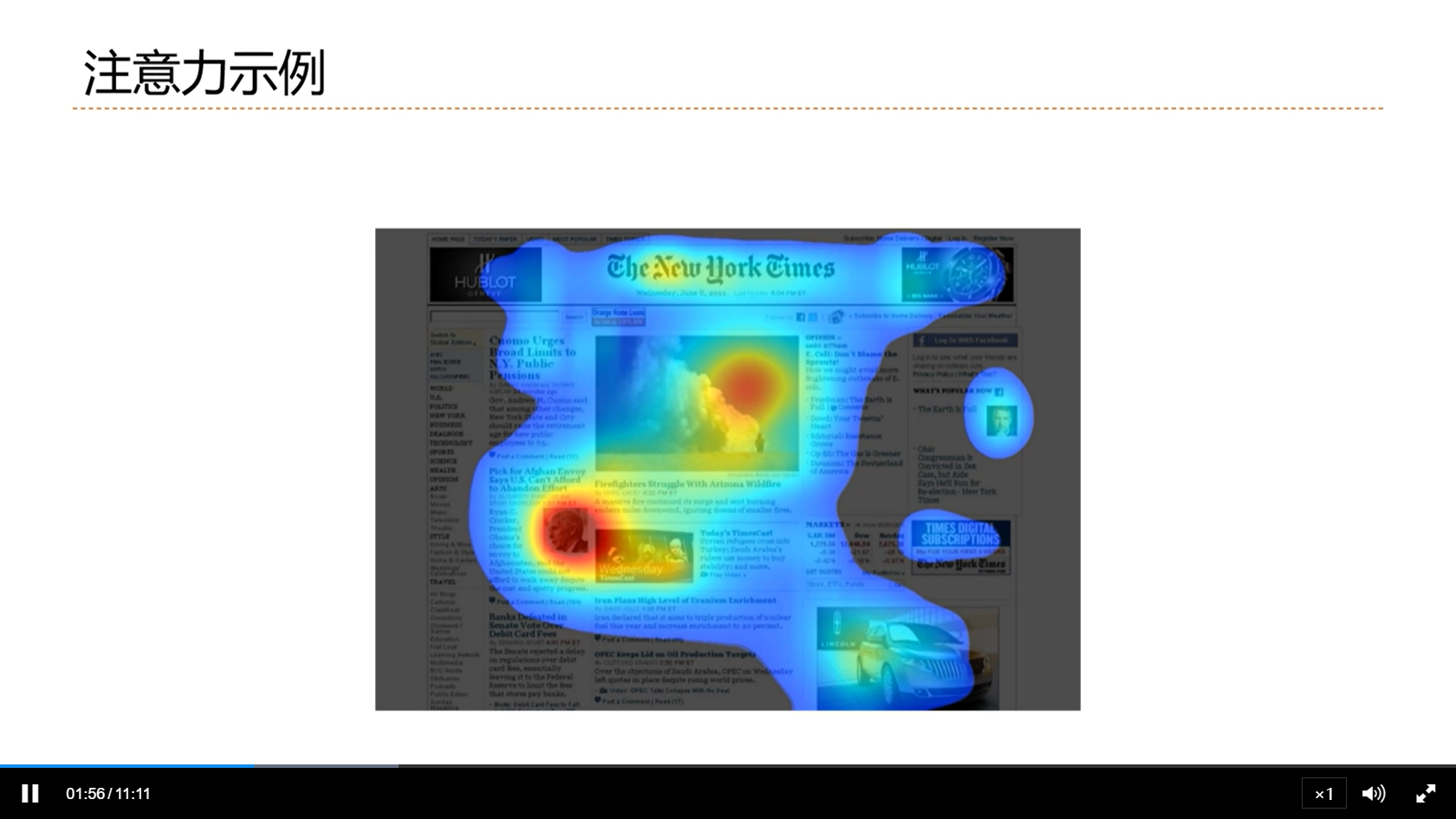
[√] 注意力示例
[√] 注意力实验

[√] 两种注意力

alec:
- 看报纸的注意力是自下而上的,不是主动的,而是被动的,这些注意力自带显著的特征,不需要主动的聚焦,就能通过神经系统得到关注
- 比如max pooling,会自动的筛选出最大的去注意
- 注意力实验中的注意力是带着问题的注意力,是自上而下的,会主动的去关注一些信息
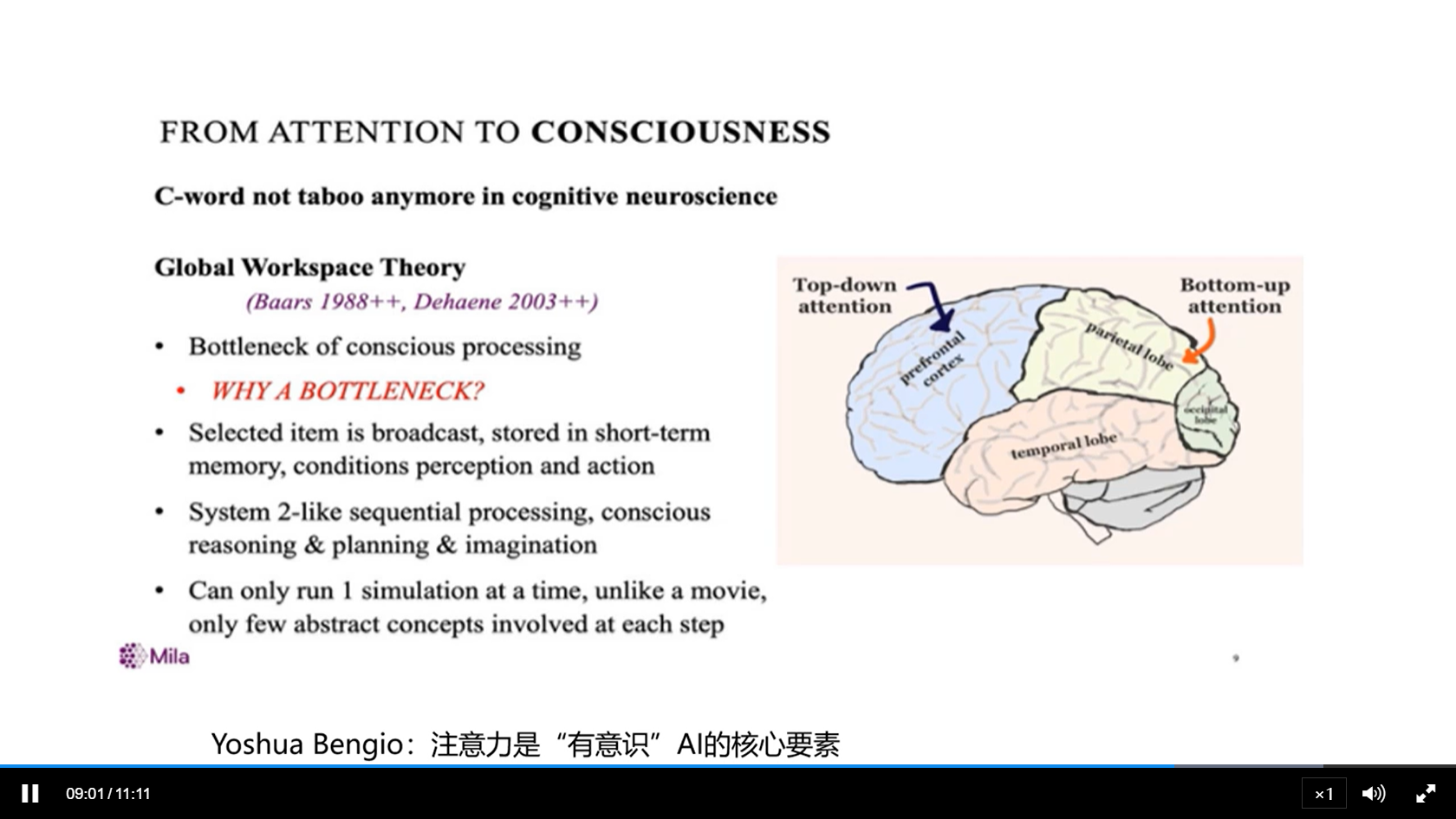
[√] 如何实现?
alec:
- 如何实现
自上而下的注意力机制呢?

alec:
- 上述例子给了我们启示:我们应该以一个较高的权重关注我们关心的内容,但是不关心的内容,也不能完全不关注,而是以一个较低的权重来关注。
[√] 8.2 - 人工神经网络中的注意力机制
[√] 问题
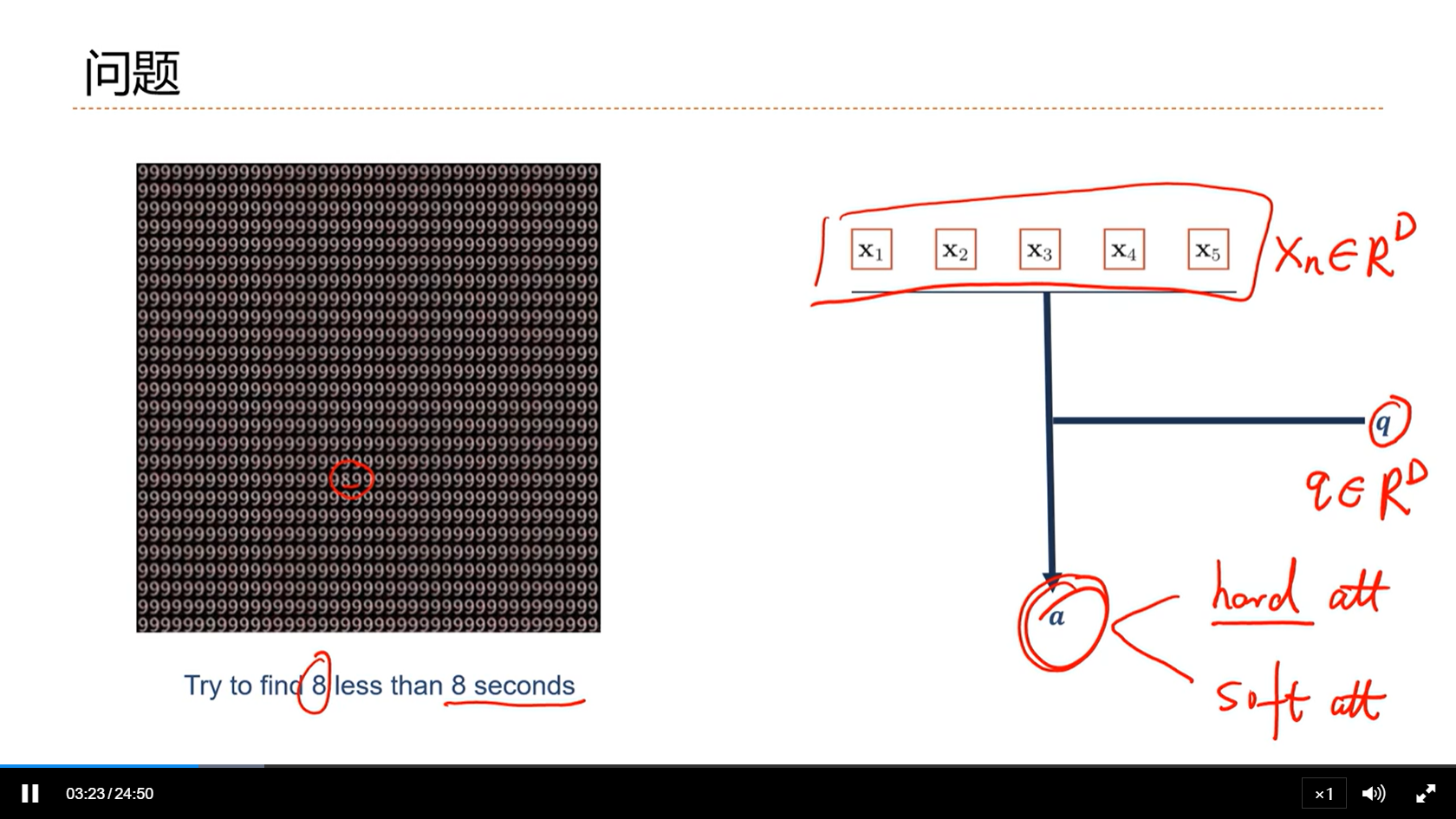
alec:
- 上图右侧,如何在x_n中找到一个和q相关的向量呢?
- 方法是拿着q一一的去和x_n作比较。然后把相关的x_n筛选出来。
- 这就是注意力机制的数学描述
- 基本有两种注意力方式:
- 硬注意力:只把最相关的找出来
- 软注意力:用每个任务向量给每个x打分,打出每个x和任务的相关度是多少
[√] 软性注意力机制(soft attention mechanism)
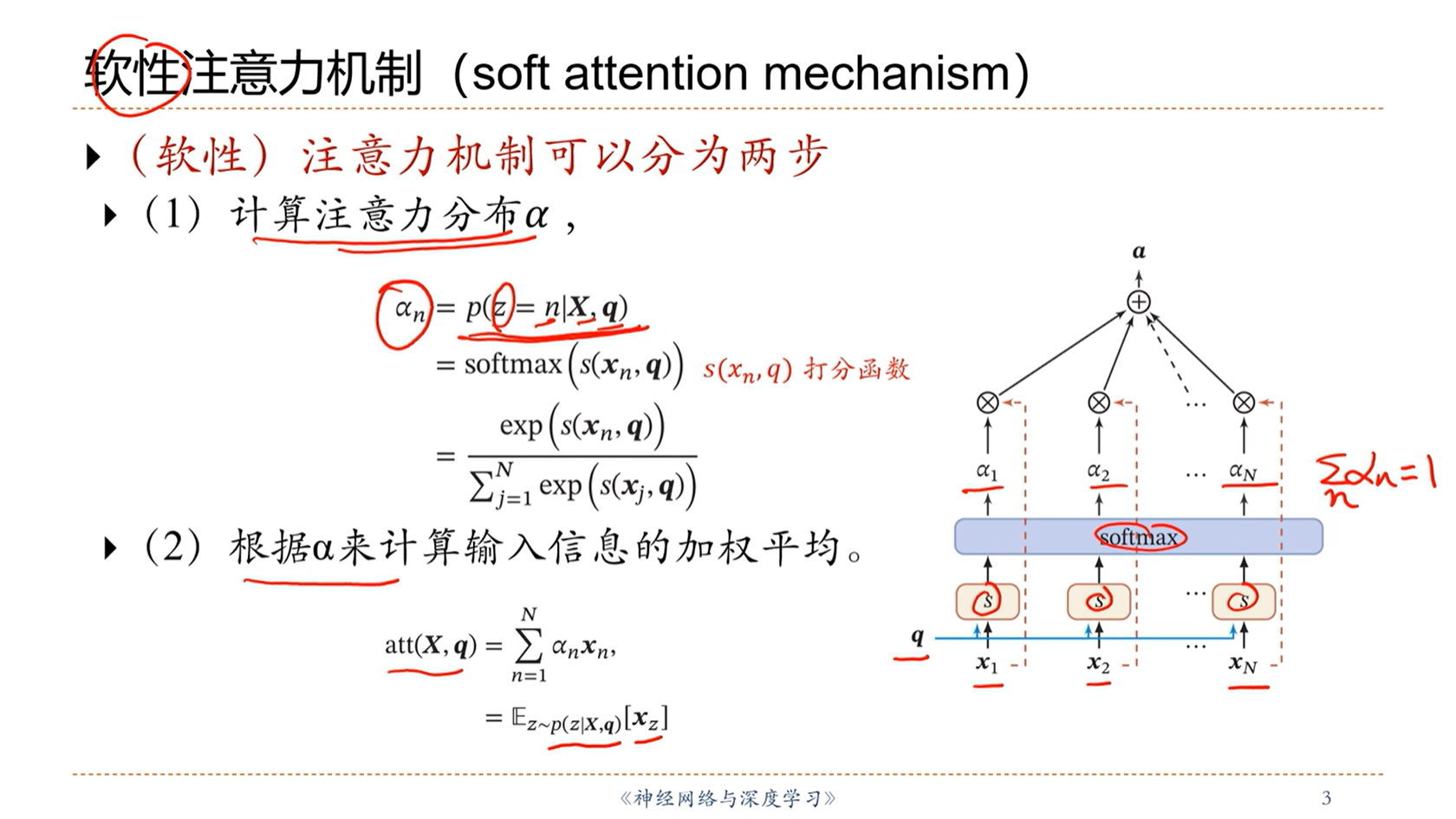
alec:
- 先对所有的输入进行概率打分,然后计算信息的加权平均得到注意力
[√] 注意力打分函数s(x_n, q)
alec:
- 打分函数计算x_n和q之间的相关度
- 如何设计打分函数跟任务相关

alec:
- 上述的模型在效果差不多的情况下,考虑计算效率。实际中可能使用
缩放点积模型可能会比较多
[√] 注意力机制的变体
[√] 硬性注意力 && 键值对注意力
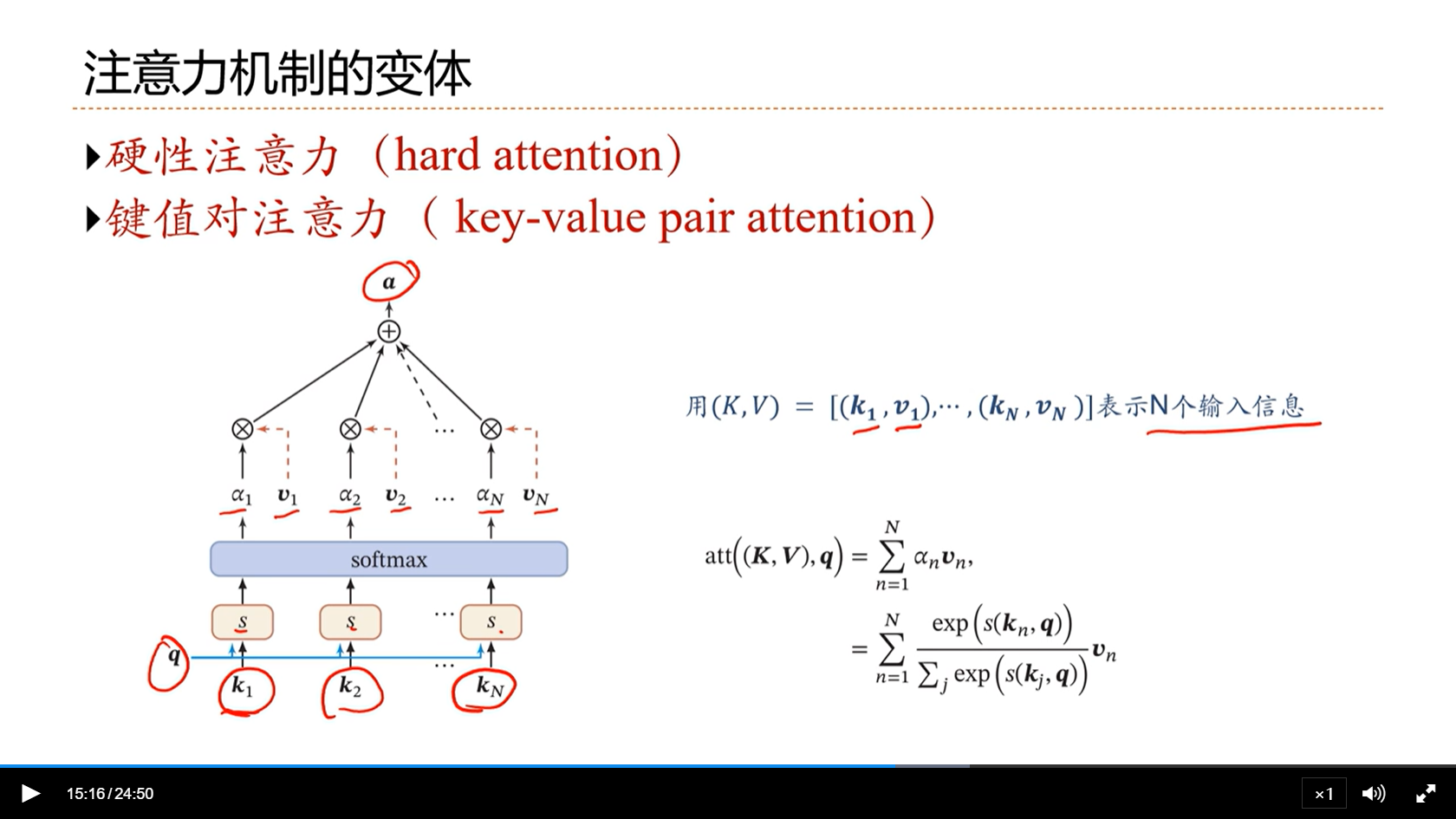
alec:
- 软性注意力是连续的,连续才可导才能够学习;硬性注意力机制是0-1,没有梯度无法学习。硬性注意力机制通常和强化学习来结合。通常主流的注意力不采用硬性注意力机制。
- 软性注意力中,x出现在两个地方:
- 第一个地方:用q和x计算相似度α
- 第二个地方:注意力机制计算出的注意力α,用在对x进行加权汇总的时候,用α进行加权汇总。
- 键值对注意力:
- 把输入信息分为键和值
- 先使用q和key运算,然后通过softmax,得到相似度α
- 然后使用相似度α和val进行加权汇总,得到最终选出来的注意力
[√] 多头注意力 && 结构化注意力

alec:
- 一个注意力可以看做用一个
查询去输入信息中选一组信息,多头注意力可以看成用多个查询去输入信息中选择多组信息
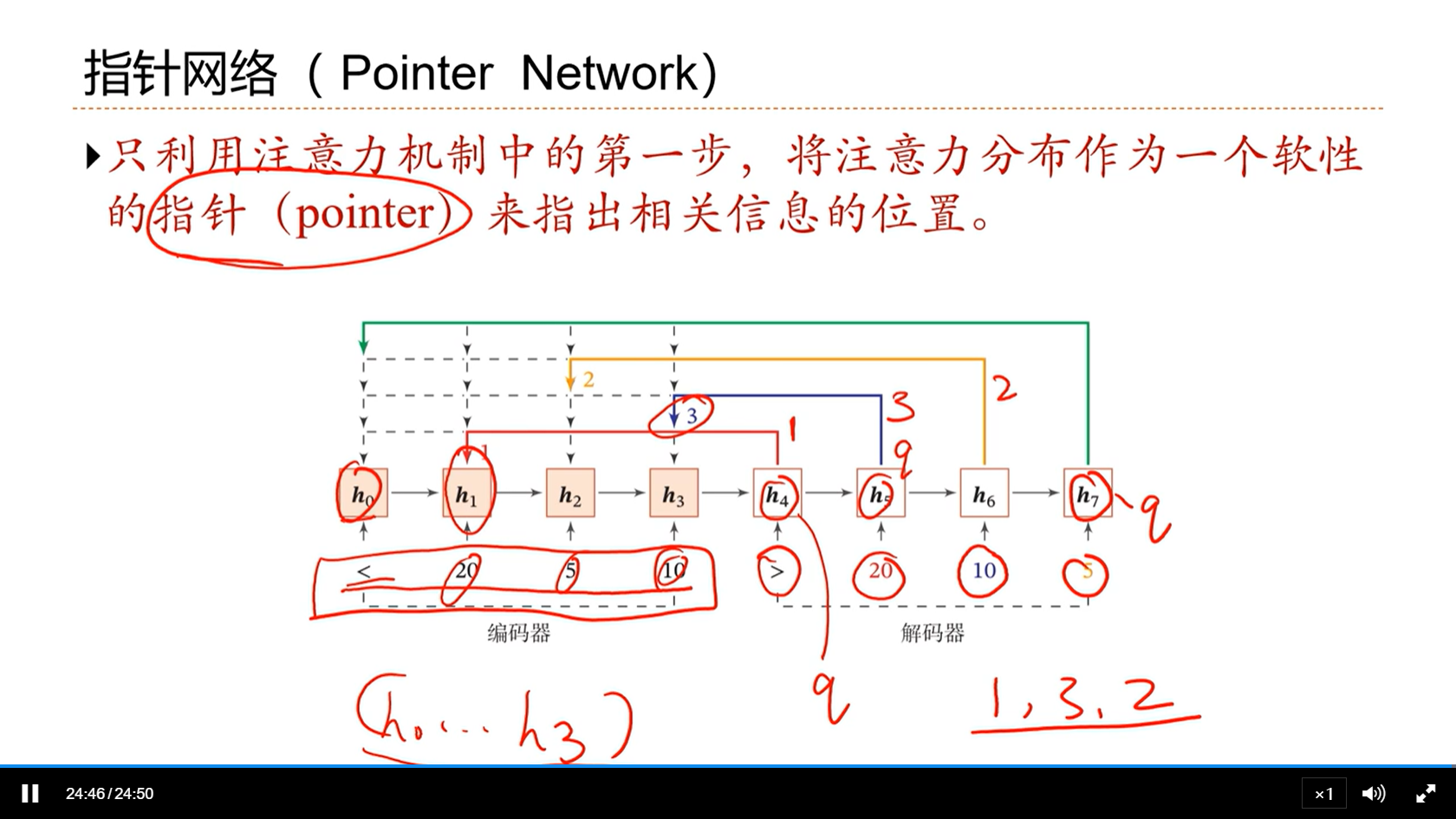
[√] 指针网络
[√] 8.3 - 注意力机制的应用
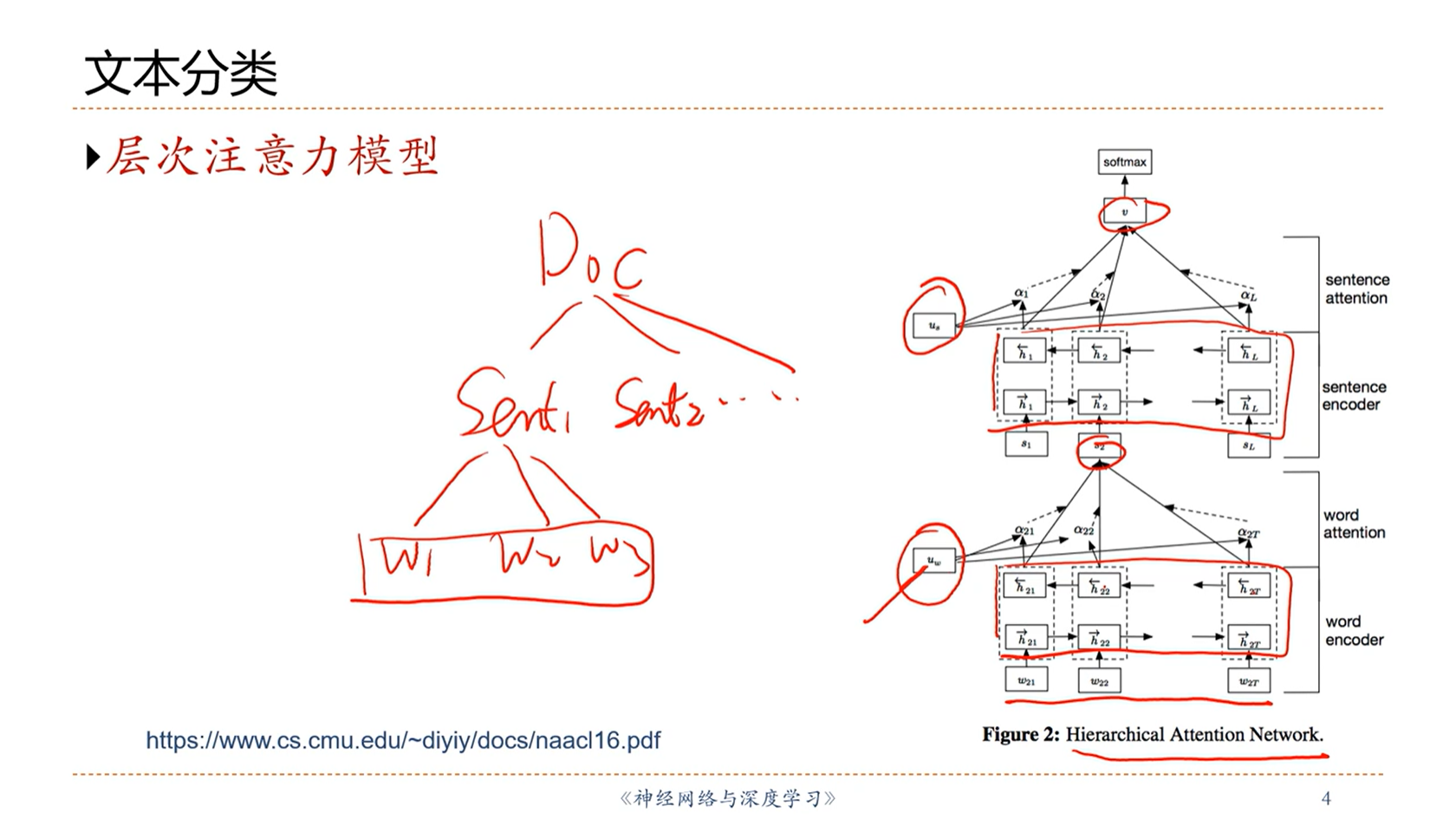
[√] 文本分类
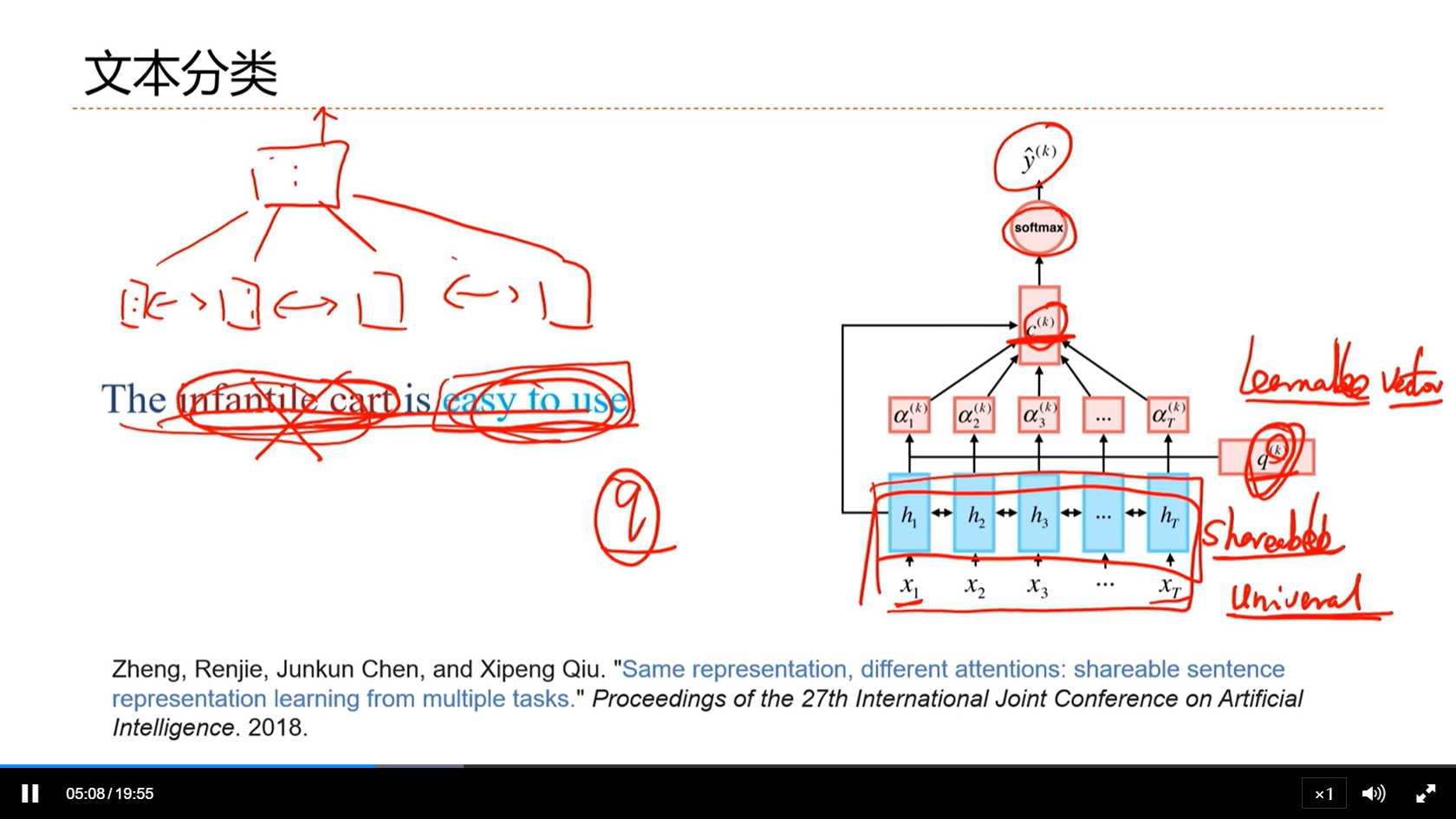

alec:
- 用不同的任务查询向量,关注点就不一样
[√] 机器翻译
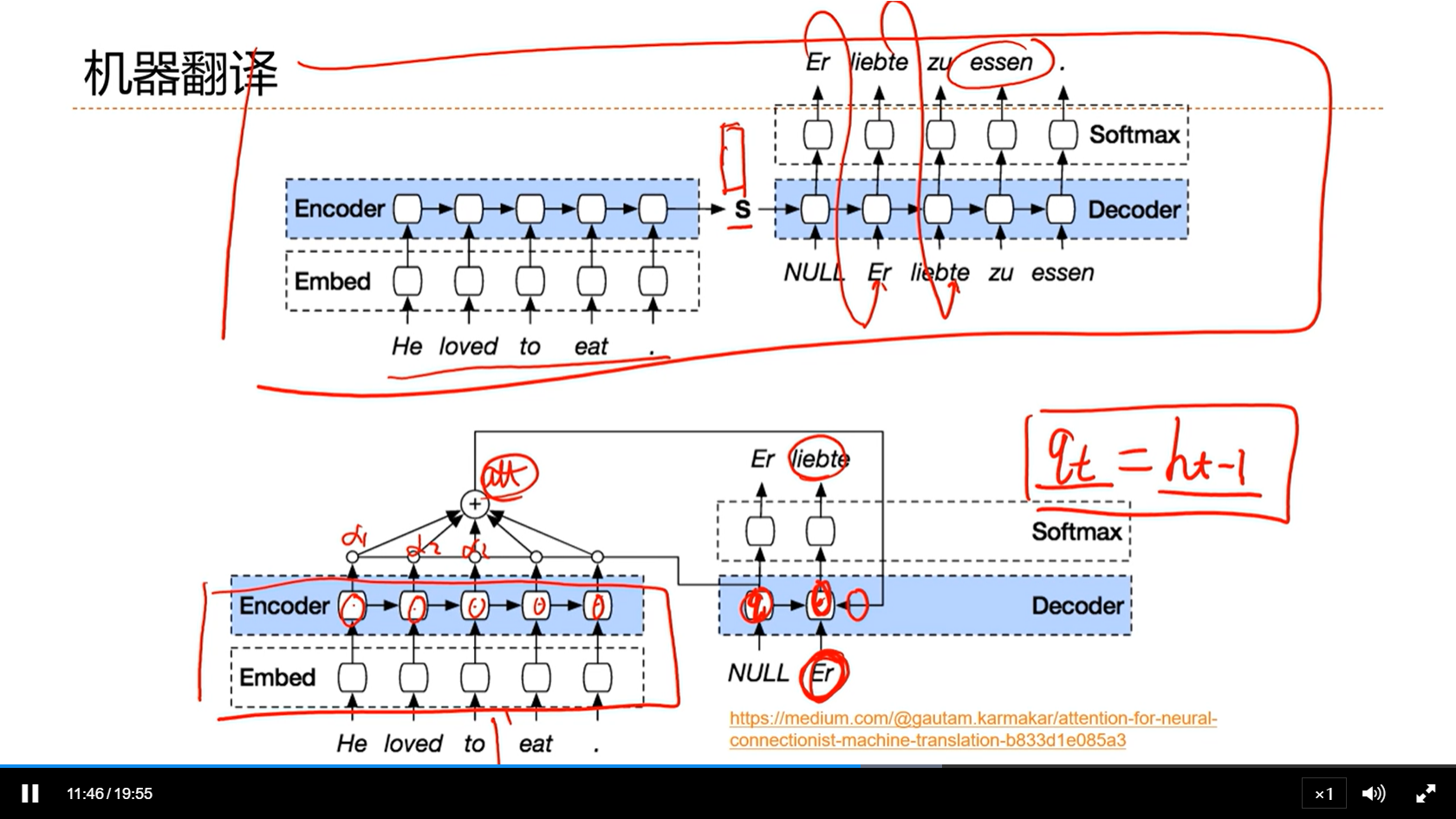
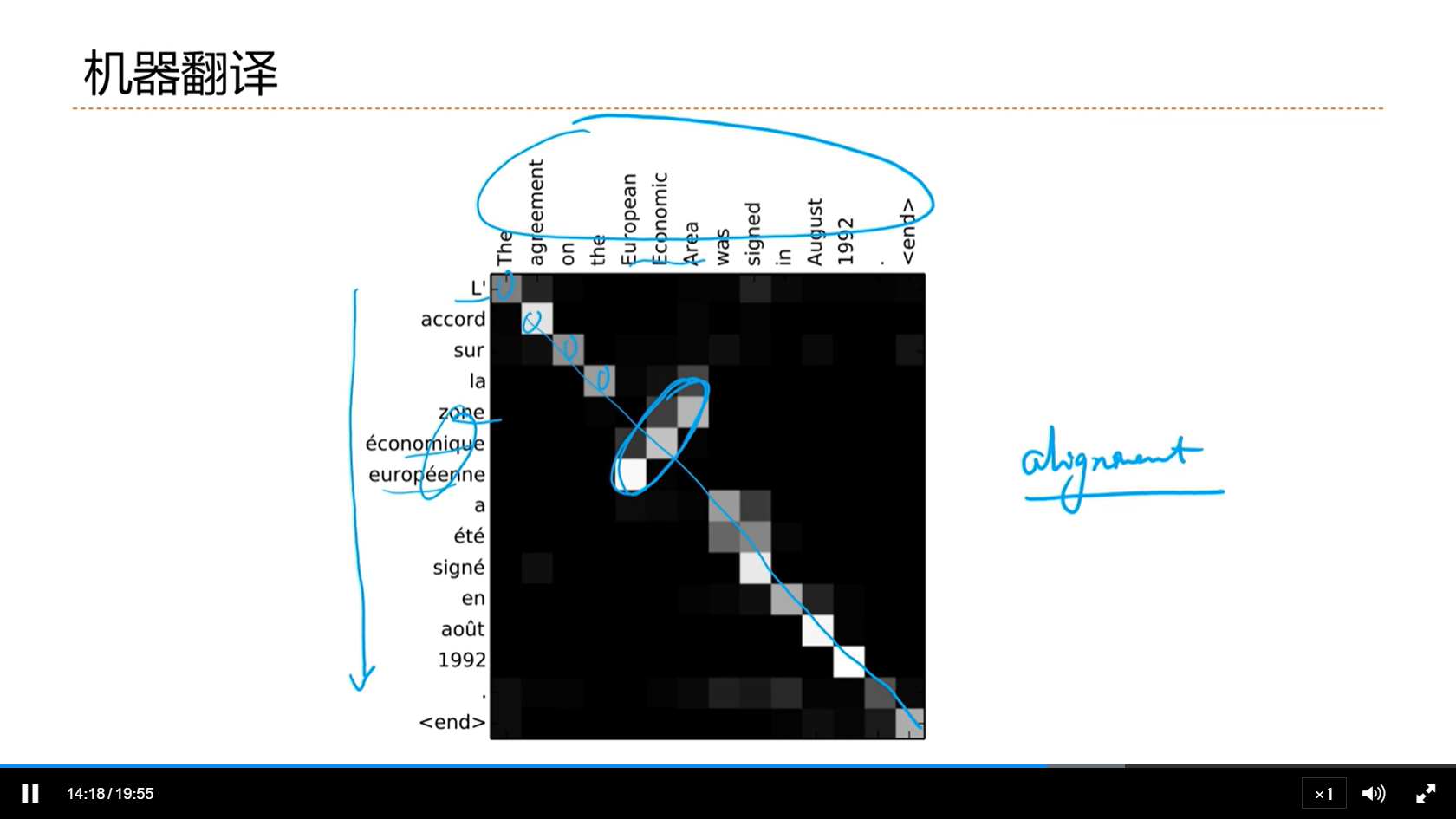
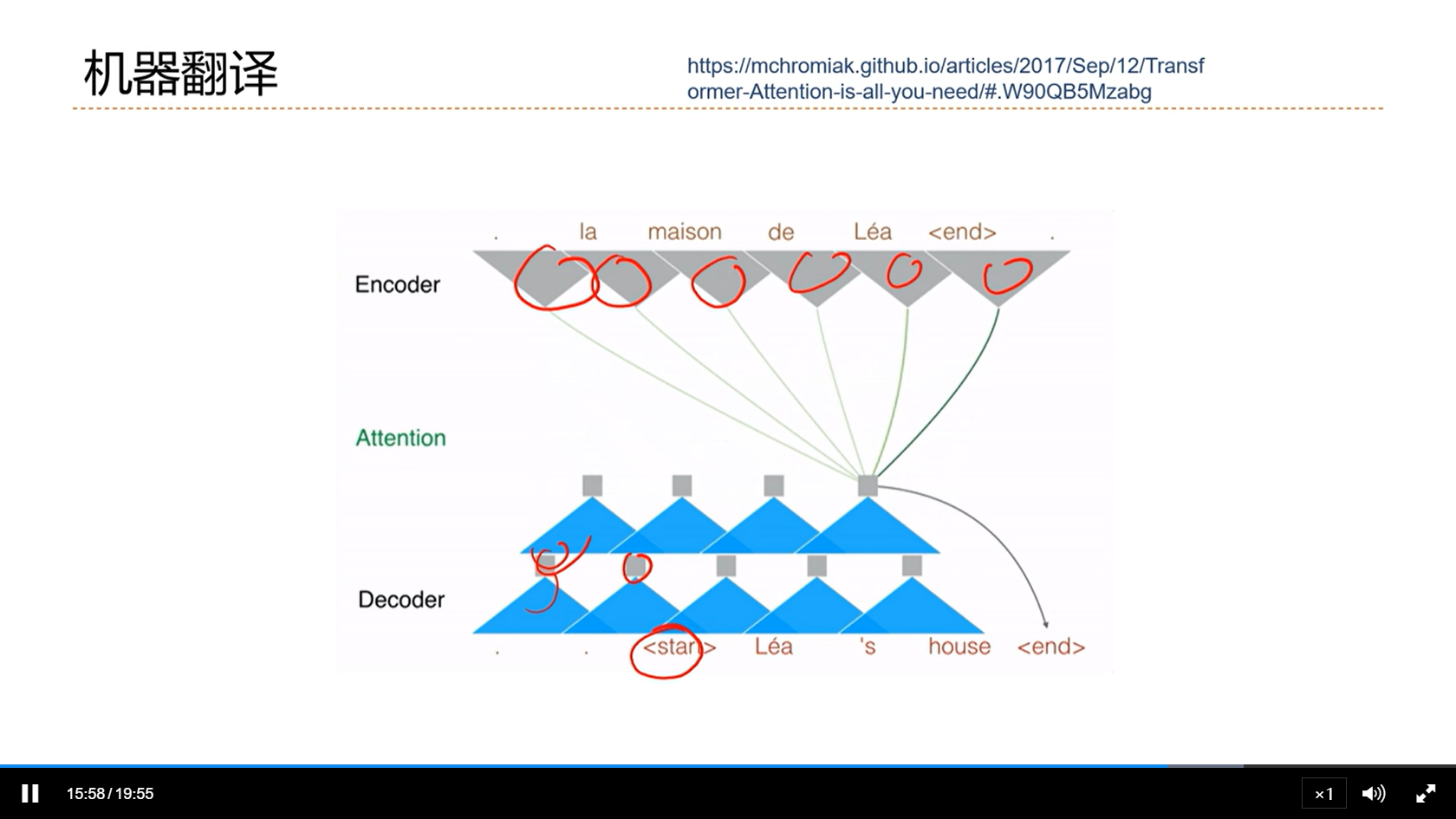
alec:
- 注意力机制对机器翻译的帮助是非常大的
[√] Image Caption(看图说话)
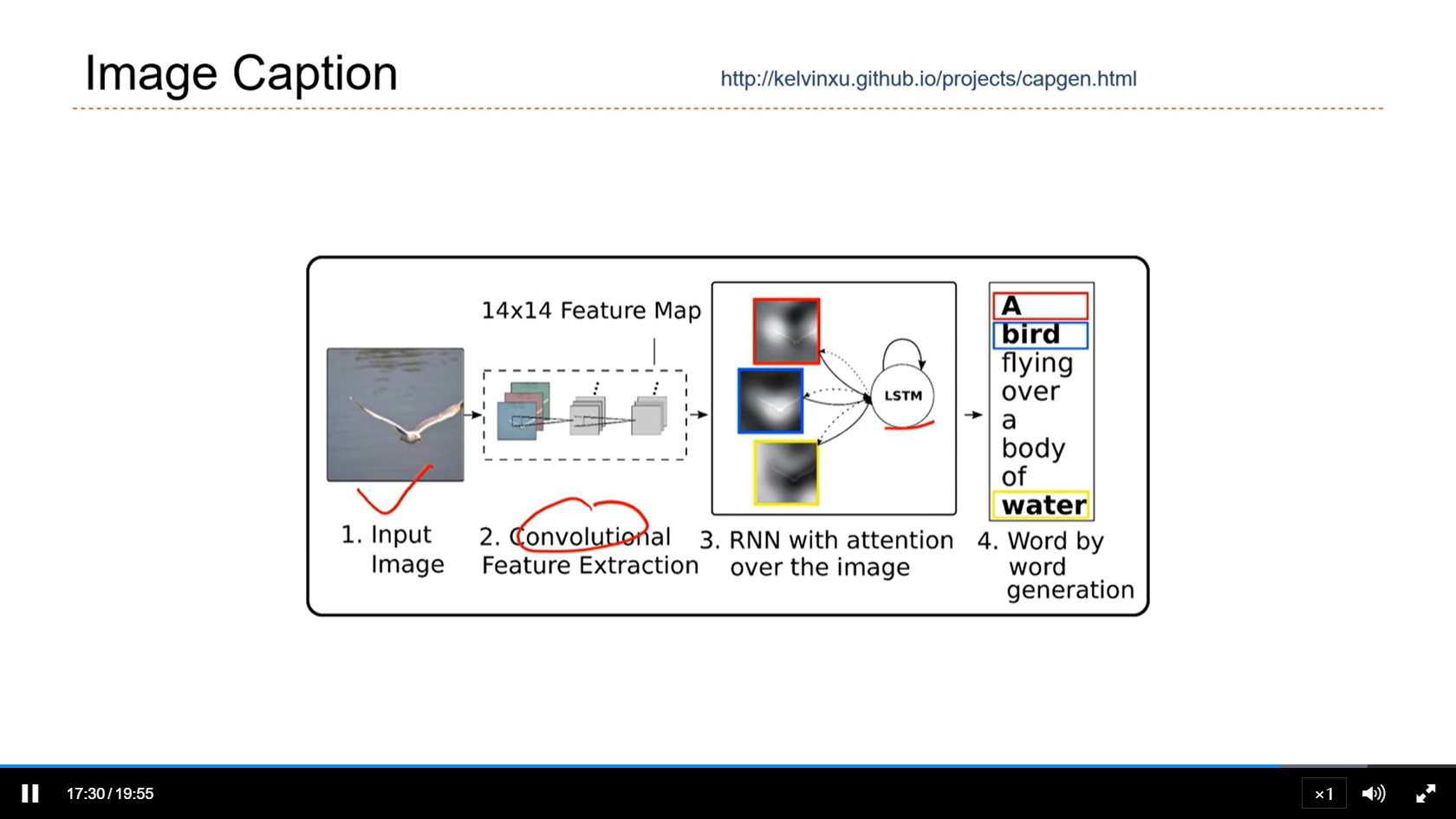
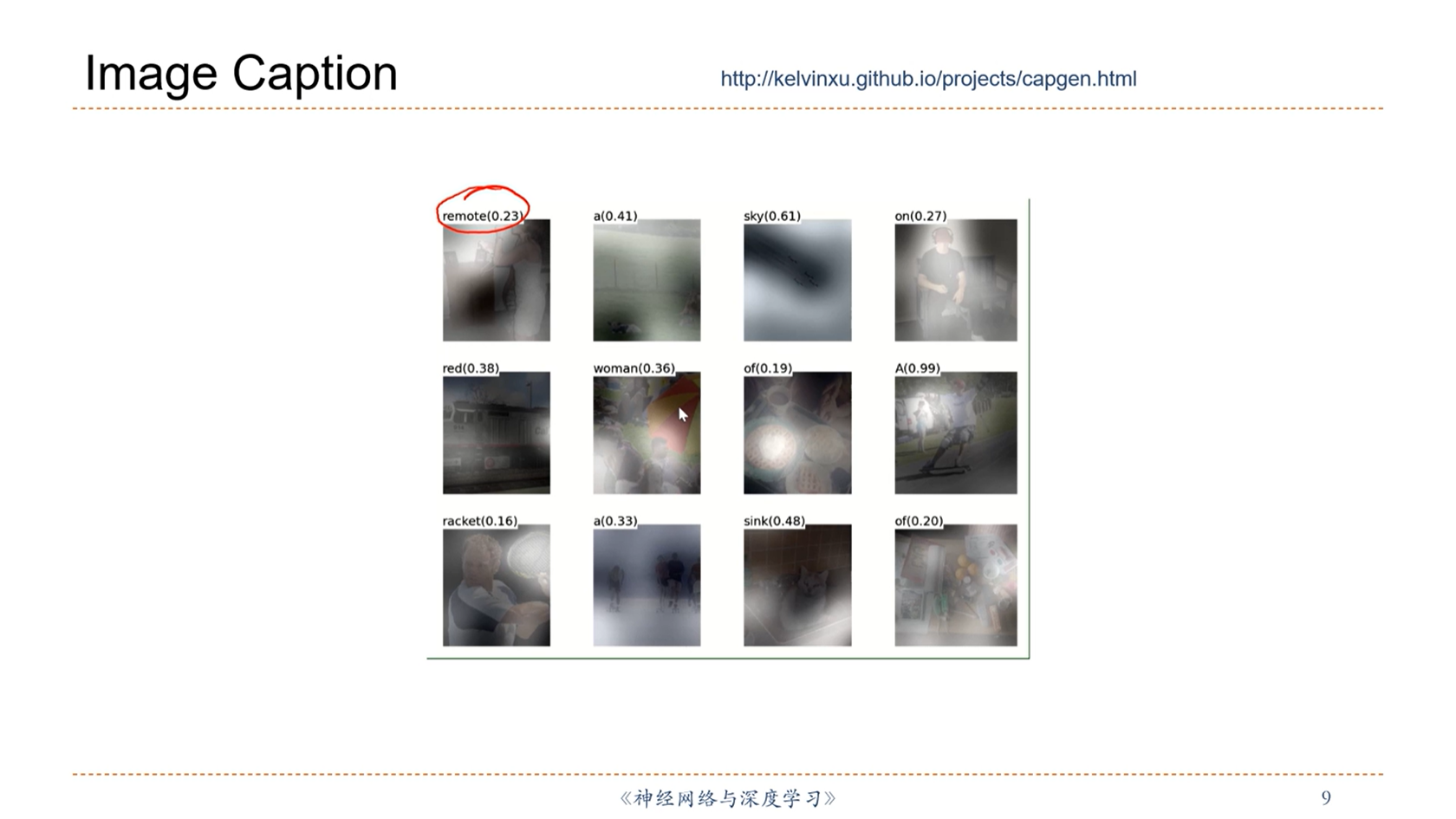
[√] 8.4 - 自注意力模型
alec:
- 自注意力模型是一种应用十分广泛的注意力机制的模型
[√] 变长序列的建模

alec:
- 由于长程依赖问题,双向RNN只能建模局部的依赖关系
- 如何建模比较长的非局部的依赖关系呢?
[√] 自注意力模型
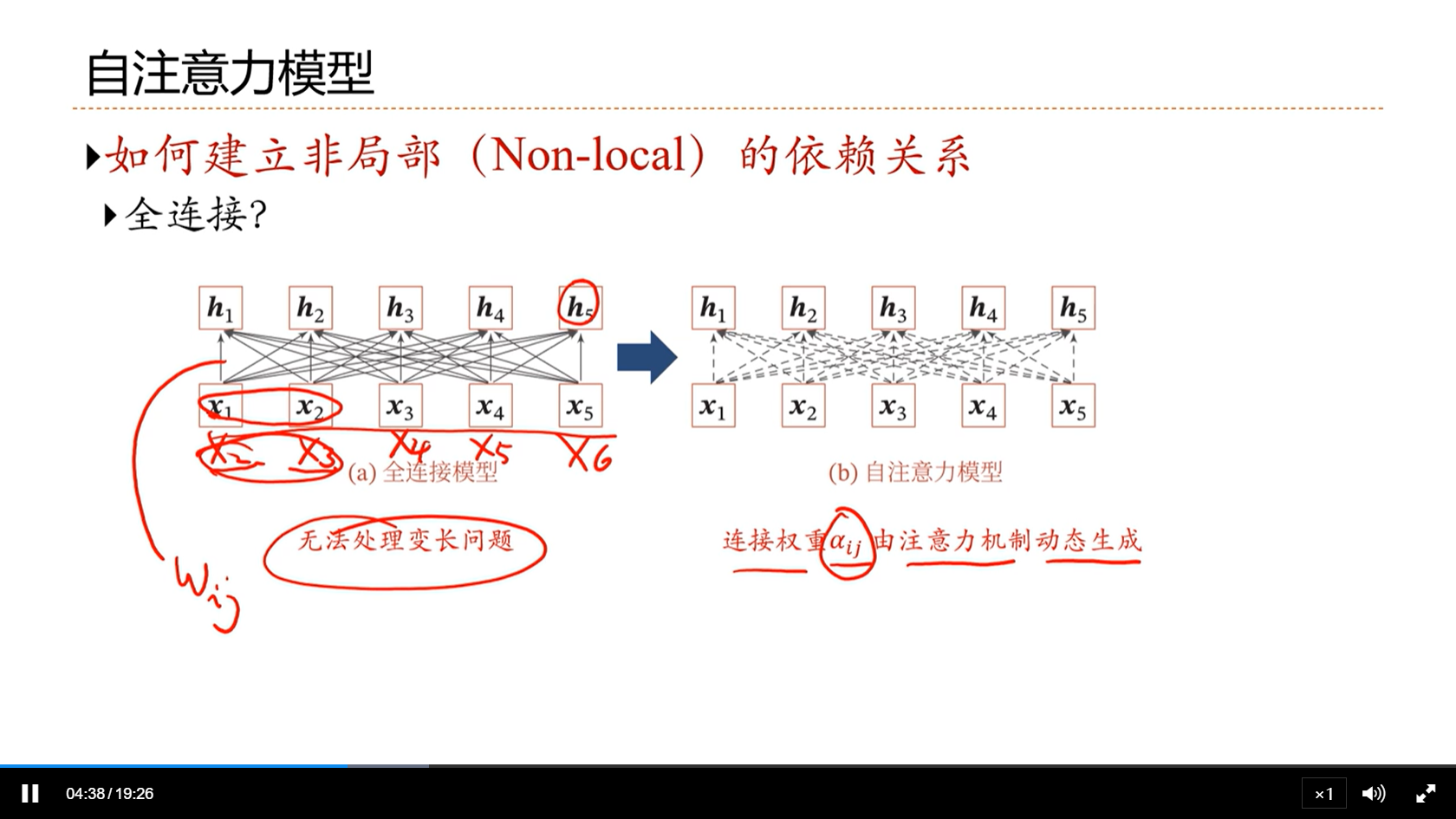
[√] 自注意力示例
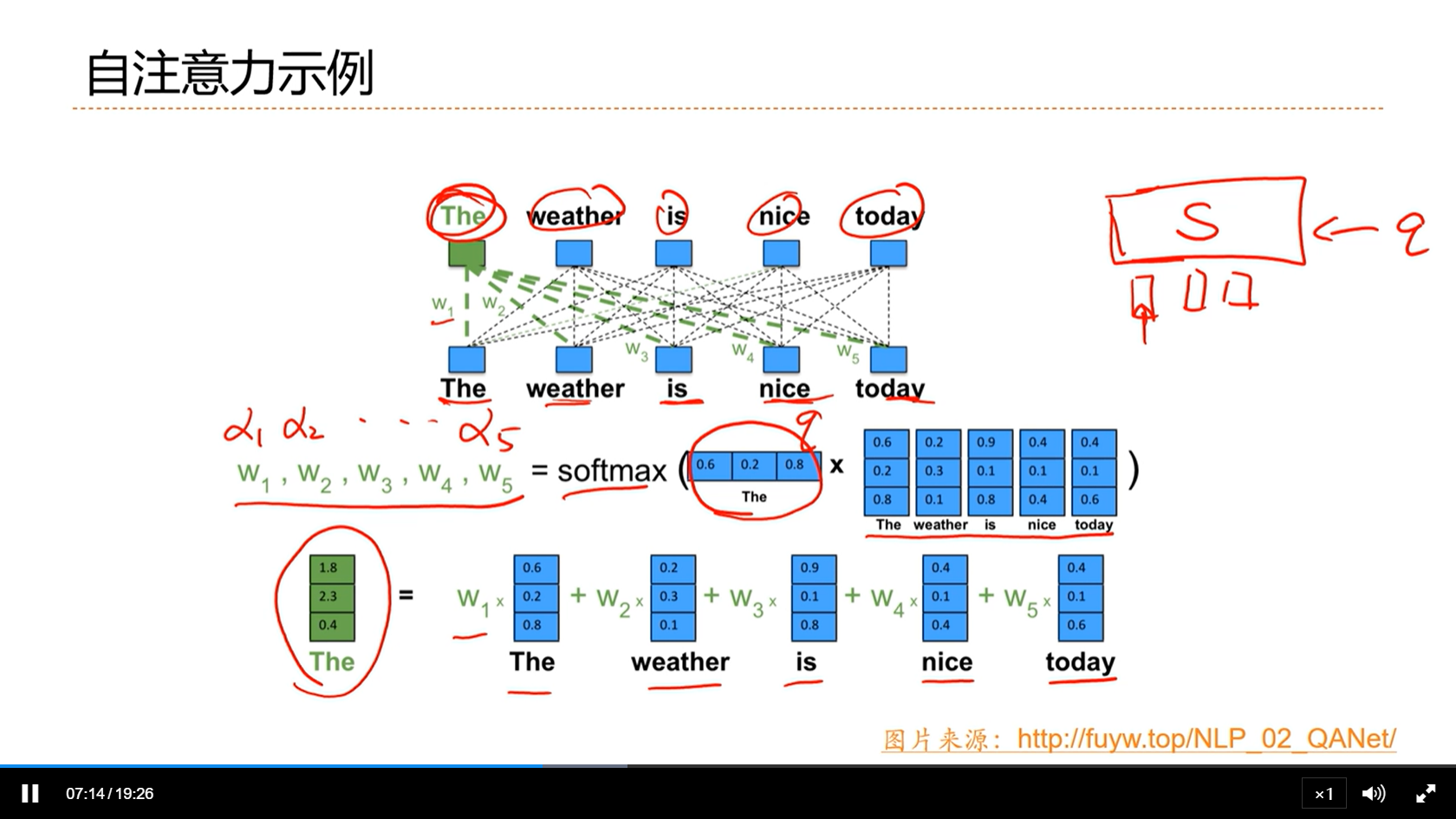
alec:
- 自注意力:每个词自身作为查询去计算注意力,自己attention自己
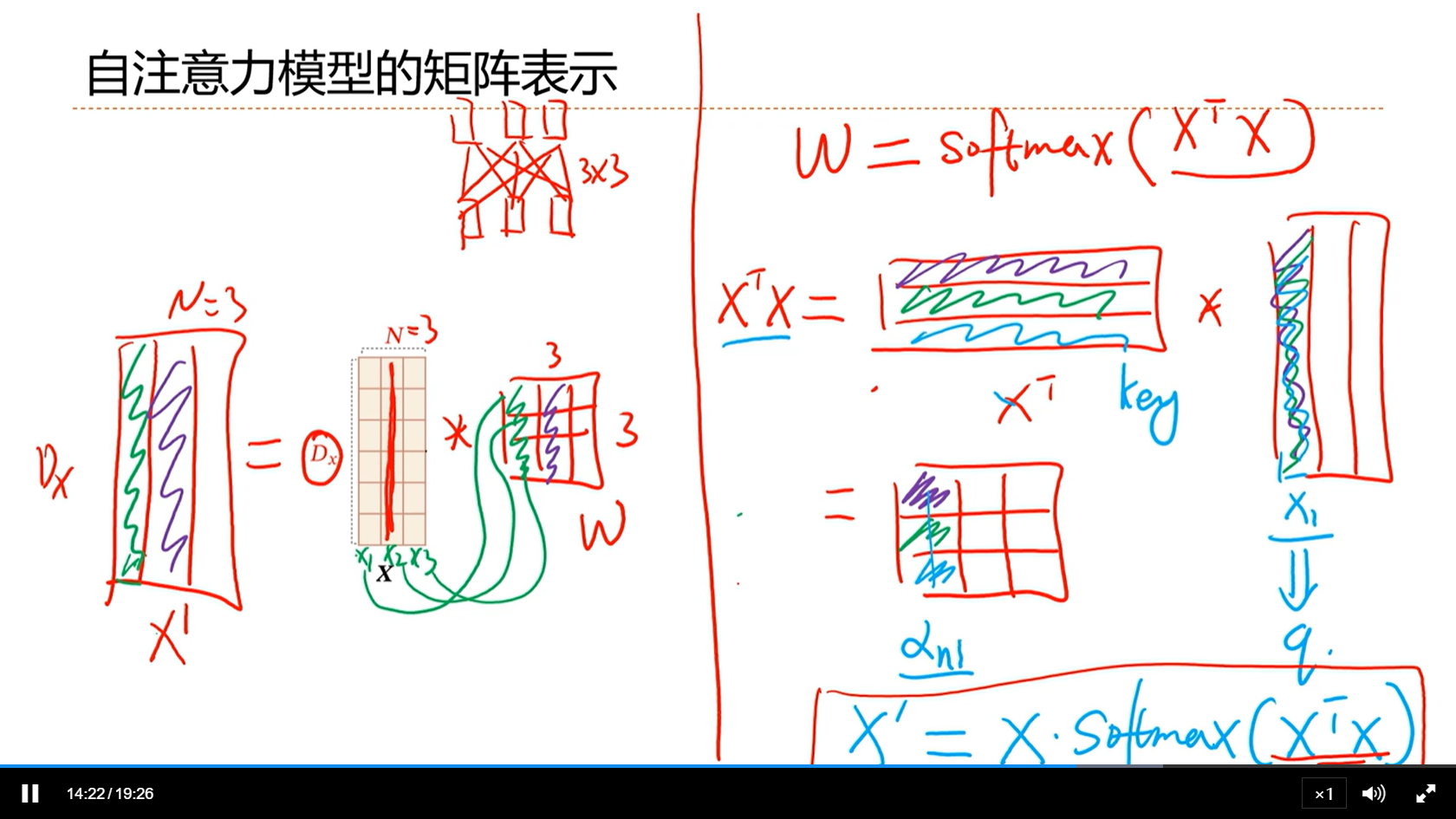
[√] 自注意力模型的矩阵表示
[√] QKV模式(Query-Key-Value)
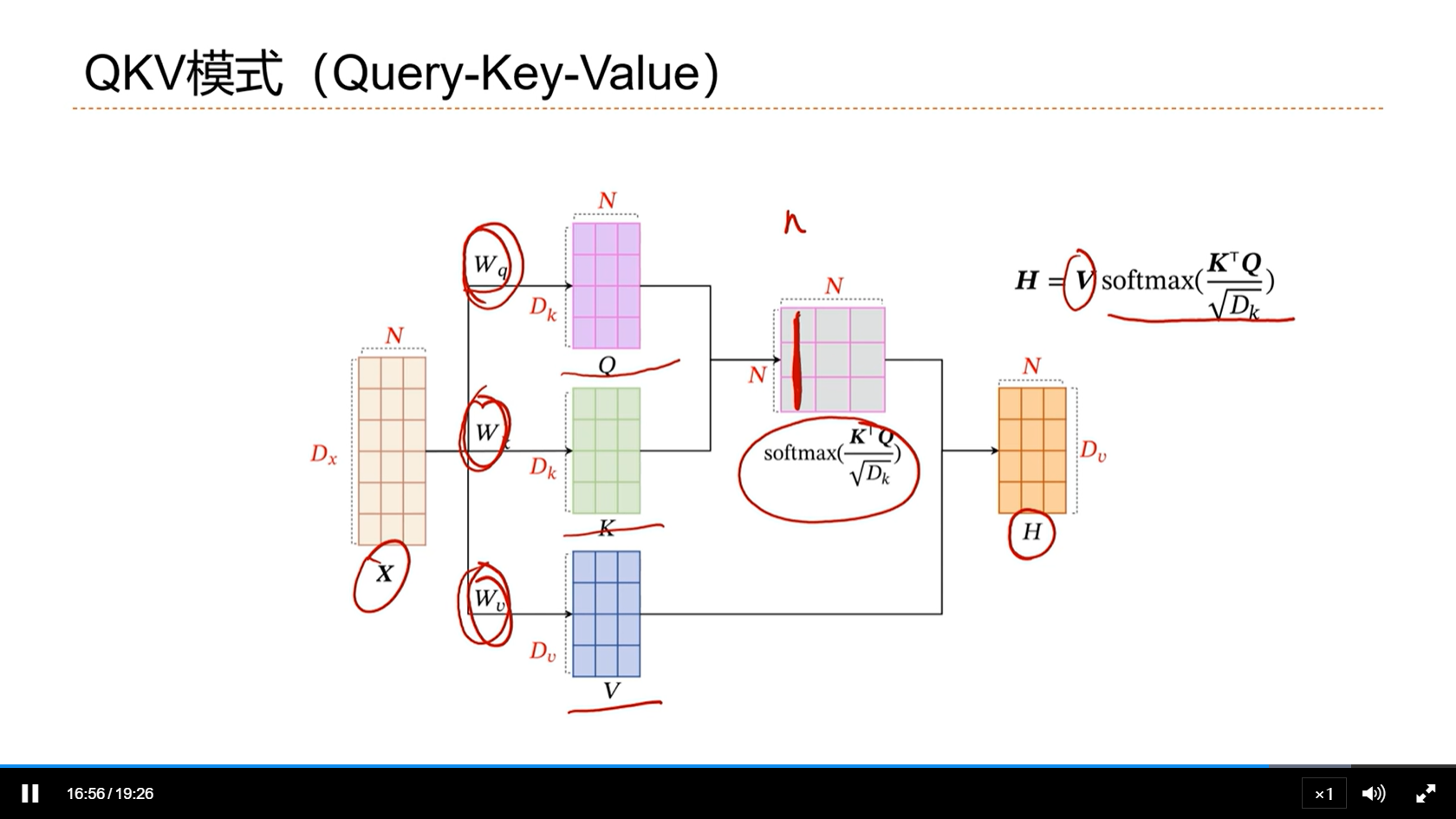
alec:
输入信息自身分成三份变成查询Q、K、V。查询Q和K计算得到权重矩阵α,然后α和V计算得到注意力
相比之下,QKV模式更多的优点是,引入了三个参数矩阵W,这样QKV模式就变得可学习了,更加灵活
QKV模式现在已经变成了非常常用的自注意力模式,默认的自注意力基本上就是使用这种模式了
[√] 自注意力模型

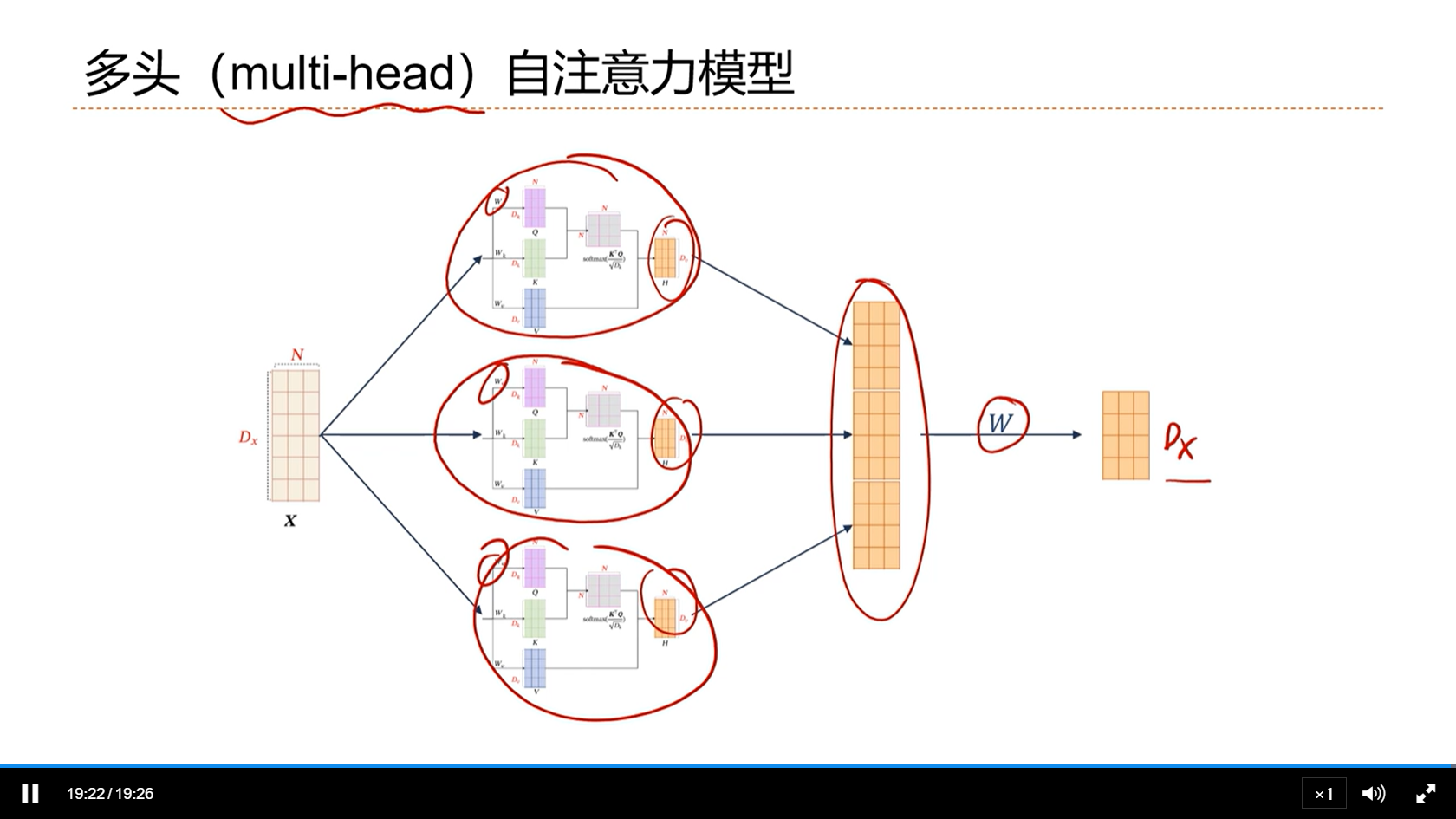
[√] 多头(multi-head)自注意力模型
alec:
- 在QKV的基础上,通过多头注意力机制,进一步使得自注意力机制的功能更加的强大
[√] 8.5 - Transformer
alec:
- transformer是自注意力机制一个成功的模型
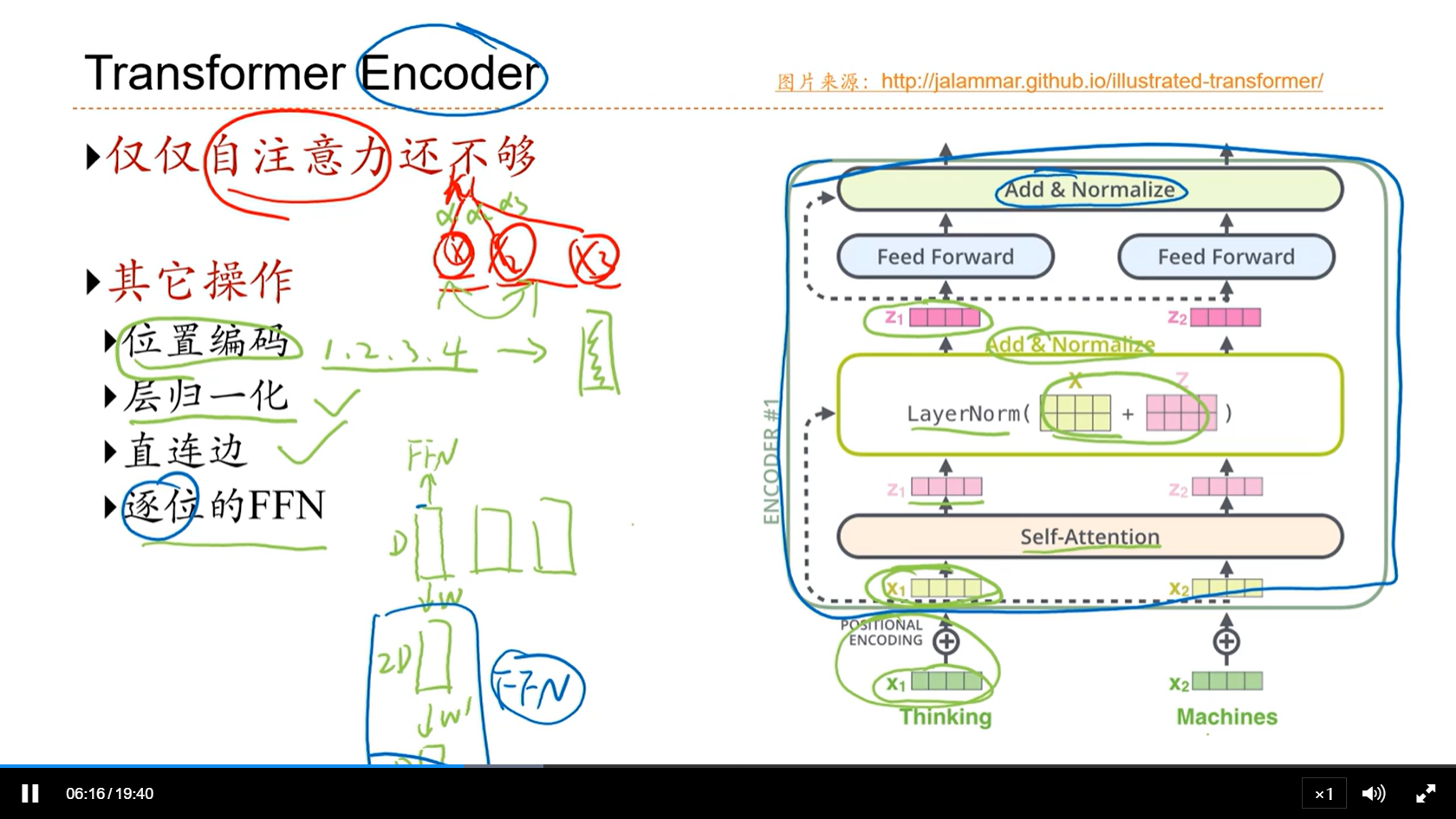
[√] Transformer Encoder
alec:
- 自注意力的权重只和内容相关,交换位置、权重不变。但是在序列中,位置信息也是非常重要的。
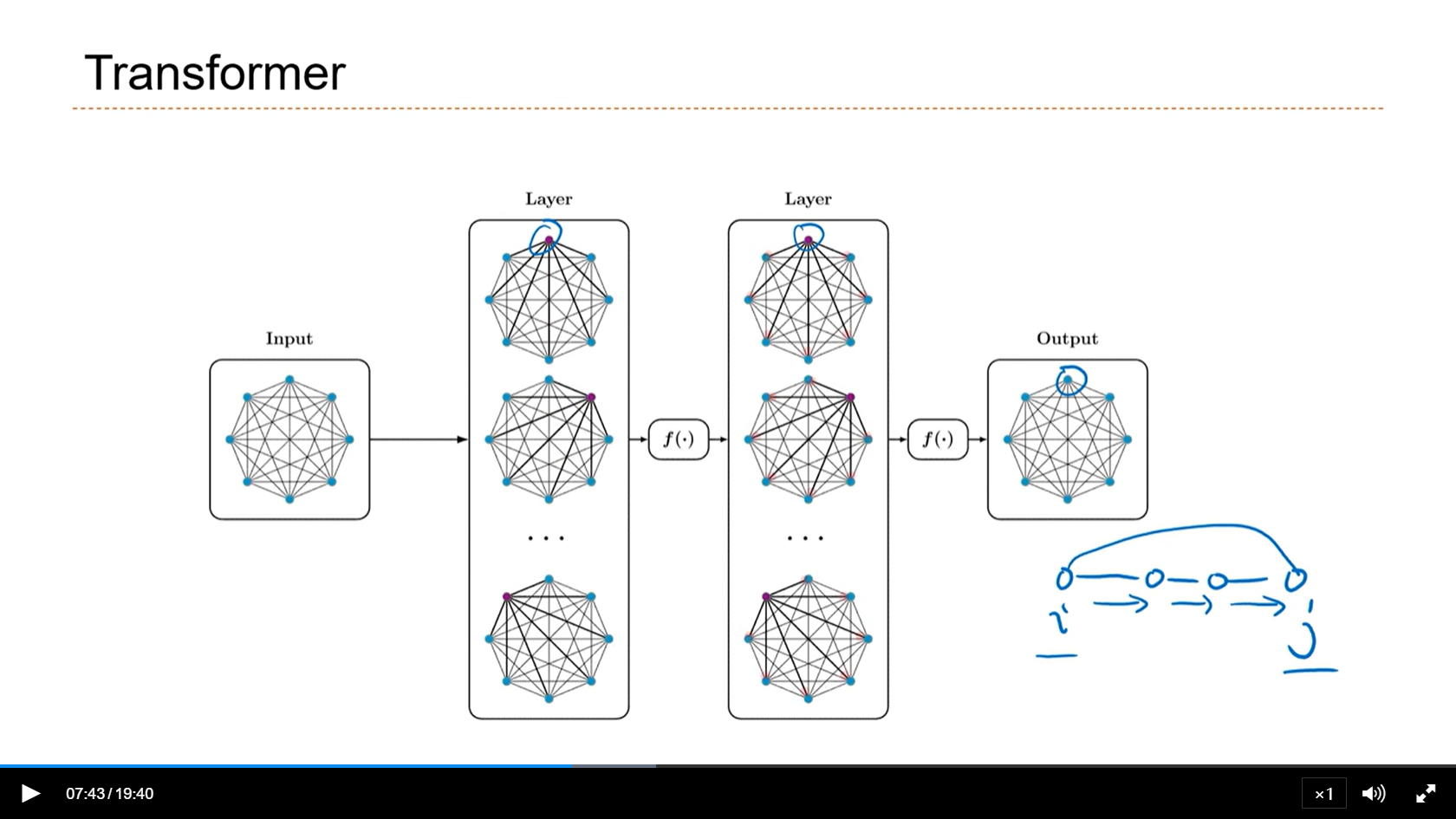
[√] Transformer
alec:
- 相比于序列一步一步的建立i和j之间的关系,transformer全连接的连接i和j,效率更高。
[√] 复杂度分析

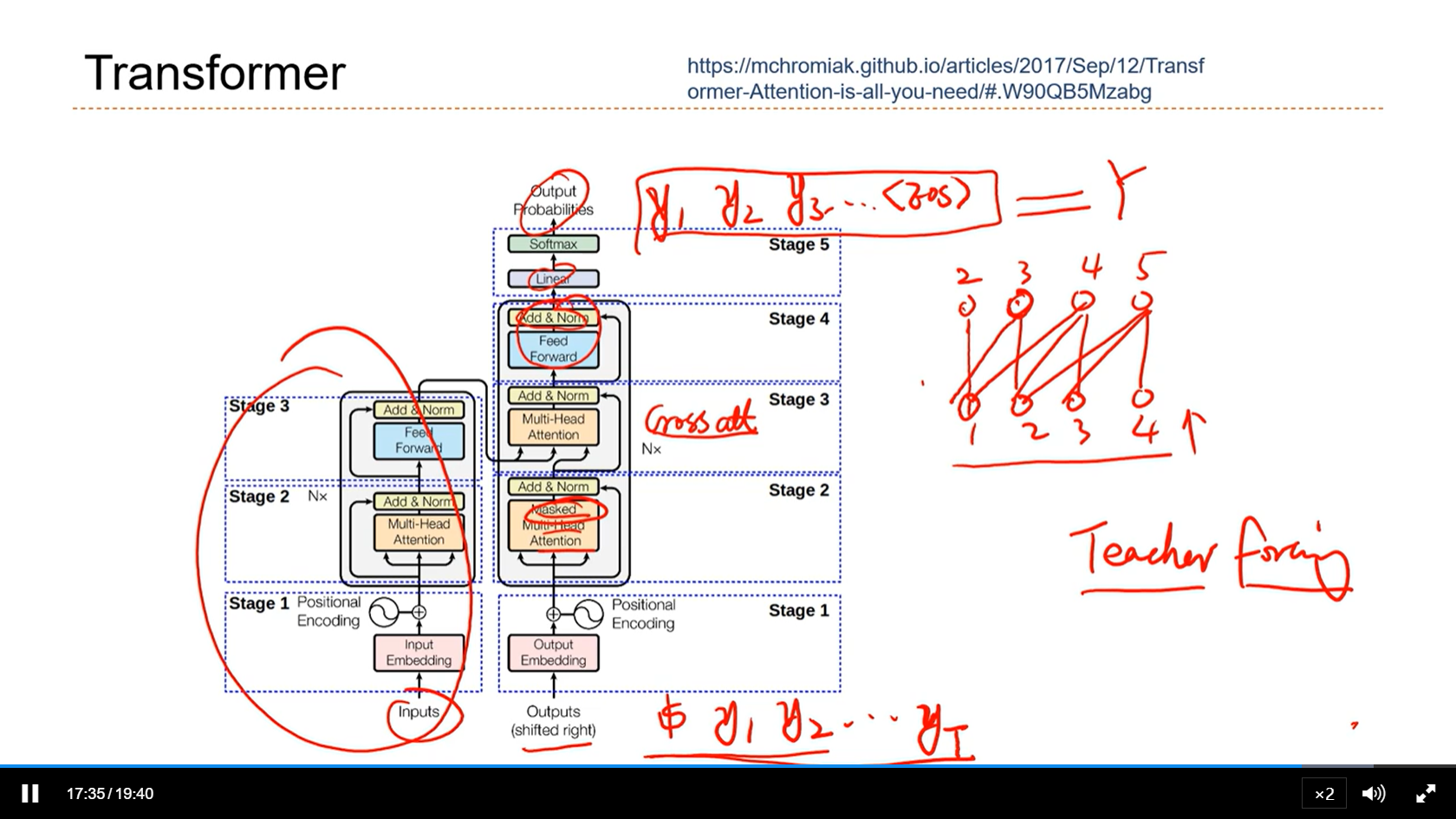
[√] Transformer
alec:
- 用transformer之前,通常会先进行预训练。transformer在小数据集上非常容易过拟合。
[√] 8.6 - 外部记忆
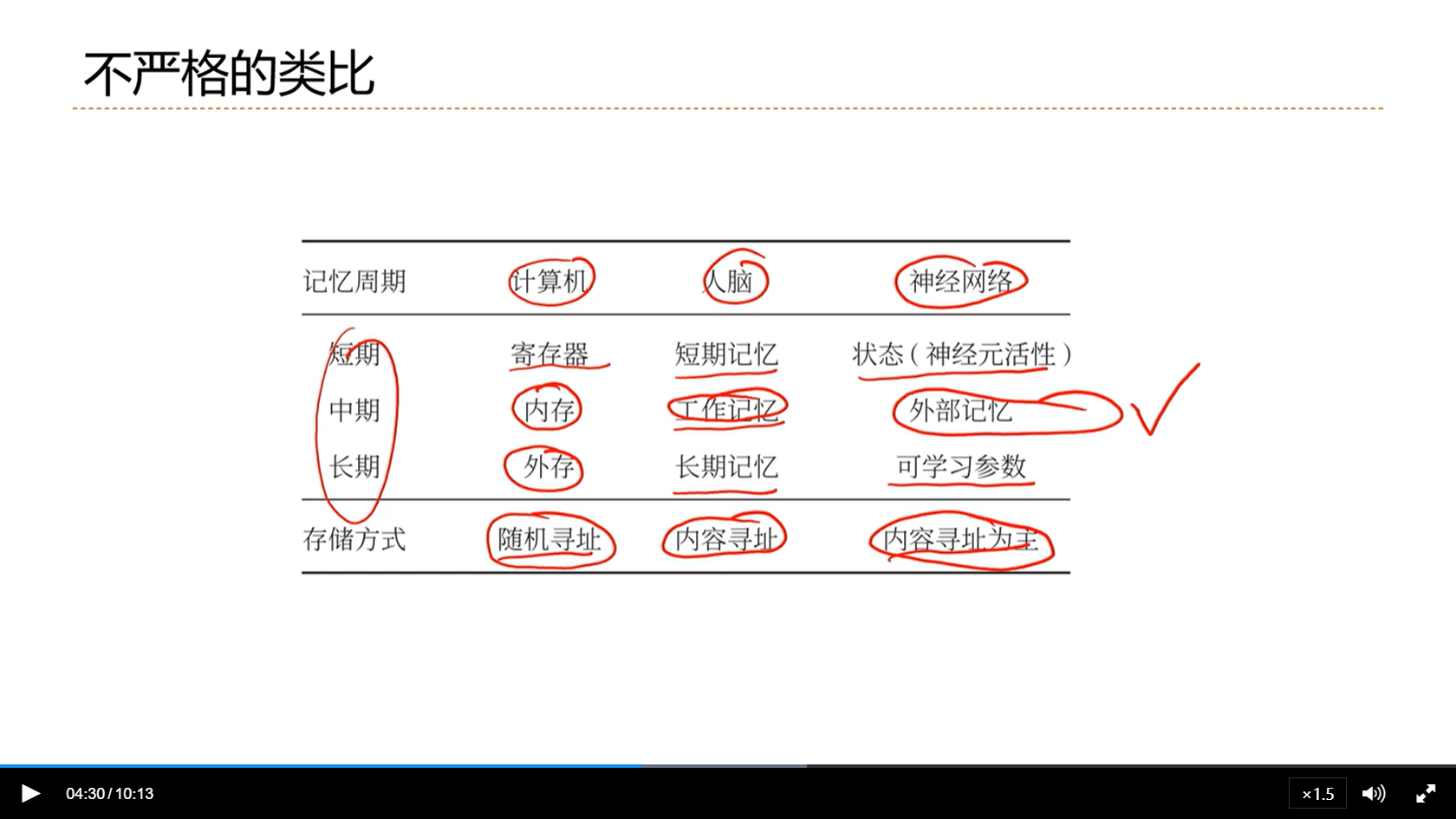
[√] 记忆网络
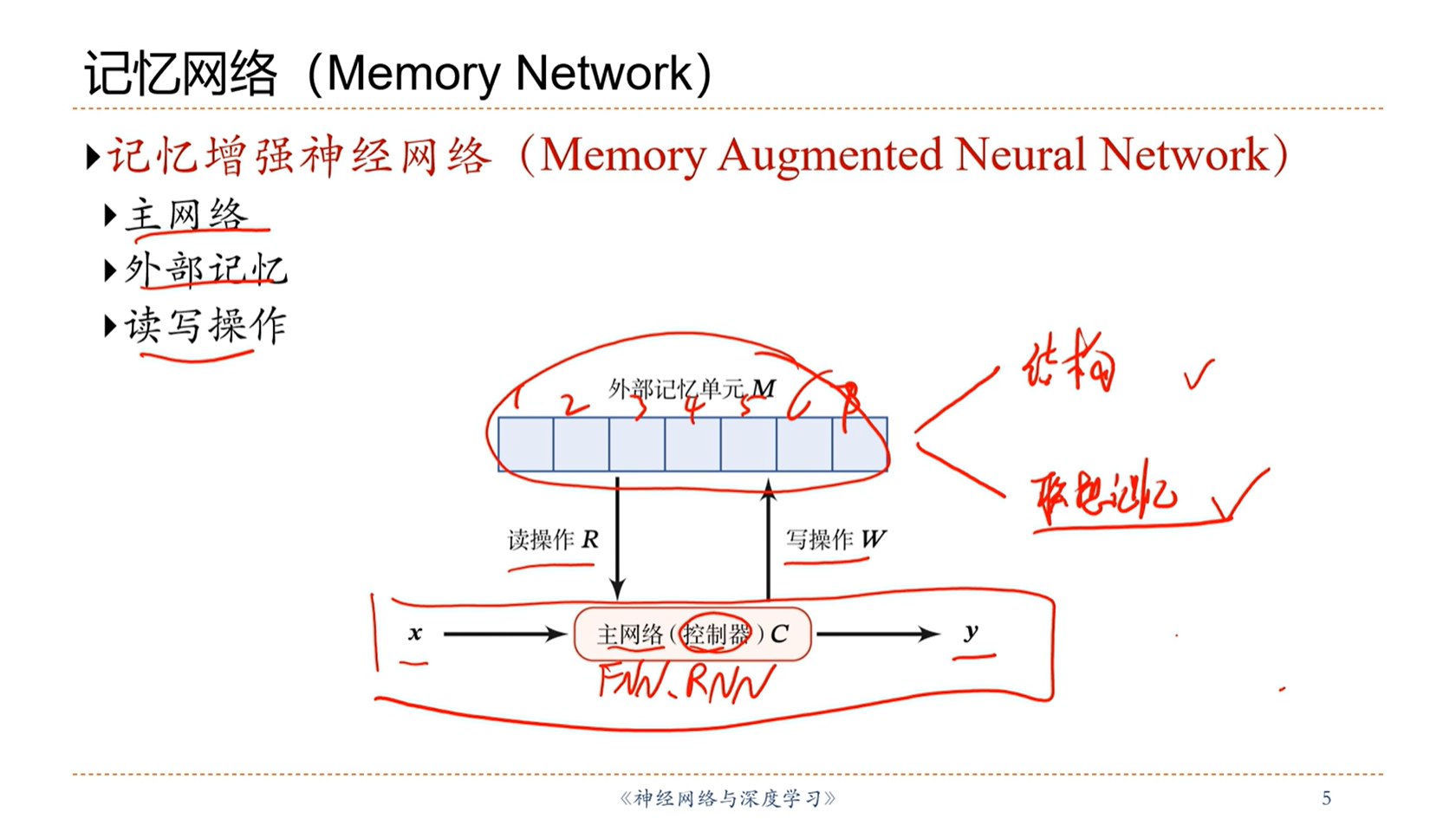
[√] 8.7 - 结构化的外部记忆
[√] 结构化的外部记忆
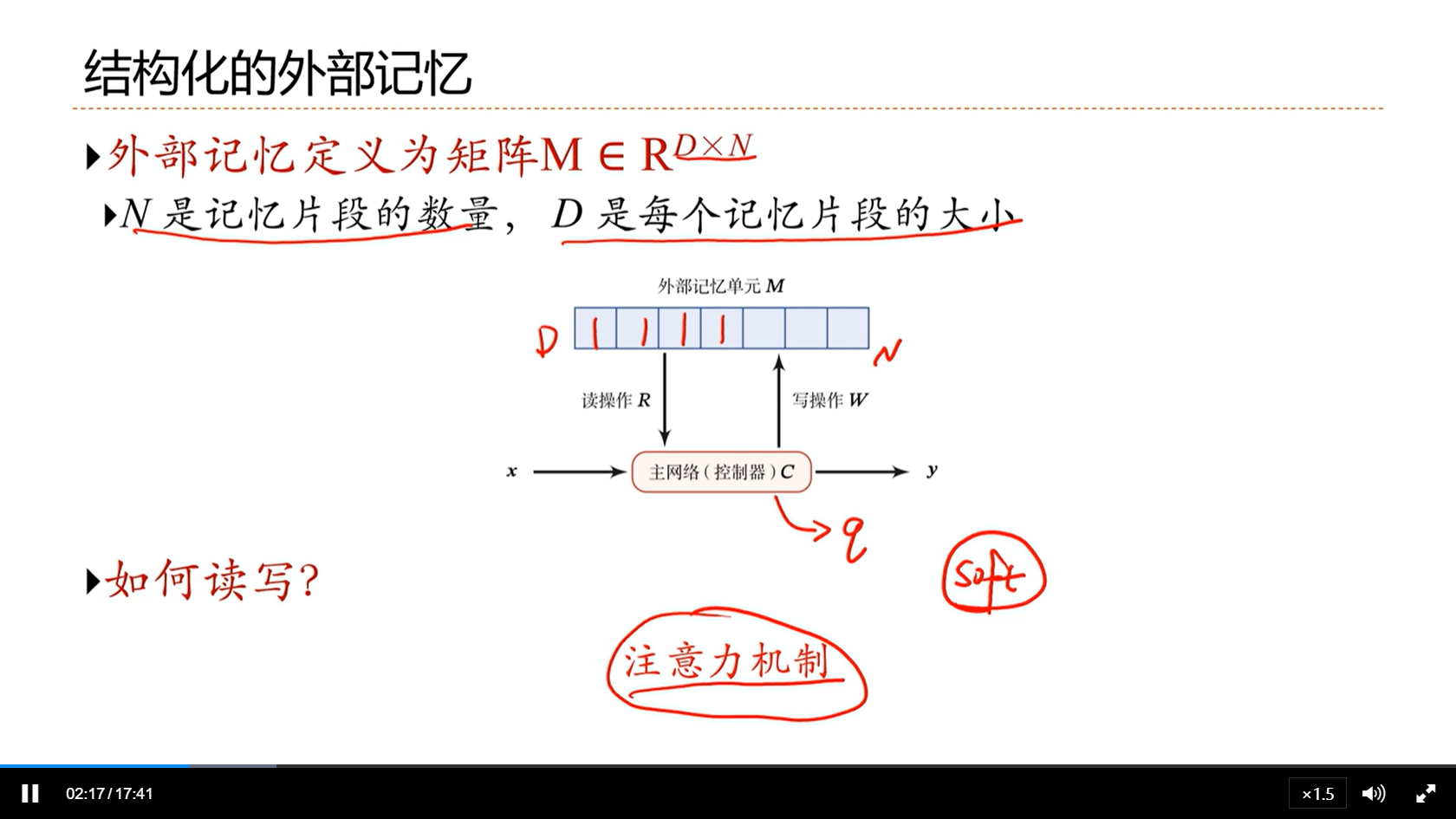
[√] 记忆网络
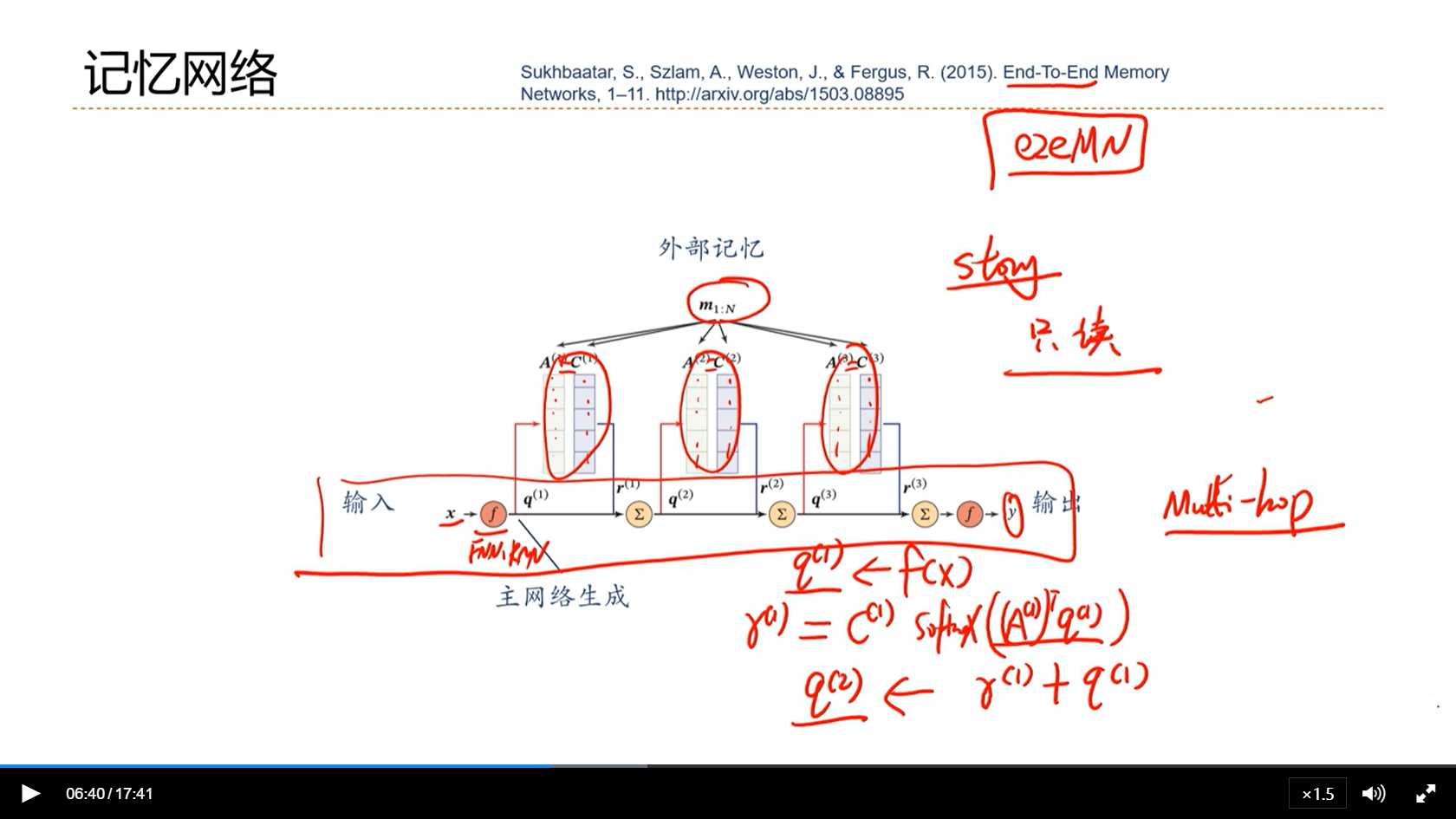
[√] 8.8 - 基于神经动力学的联想记忆
[√] 联想记忆
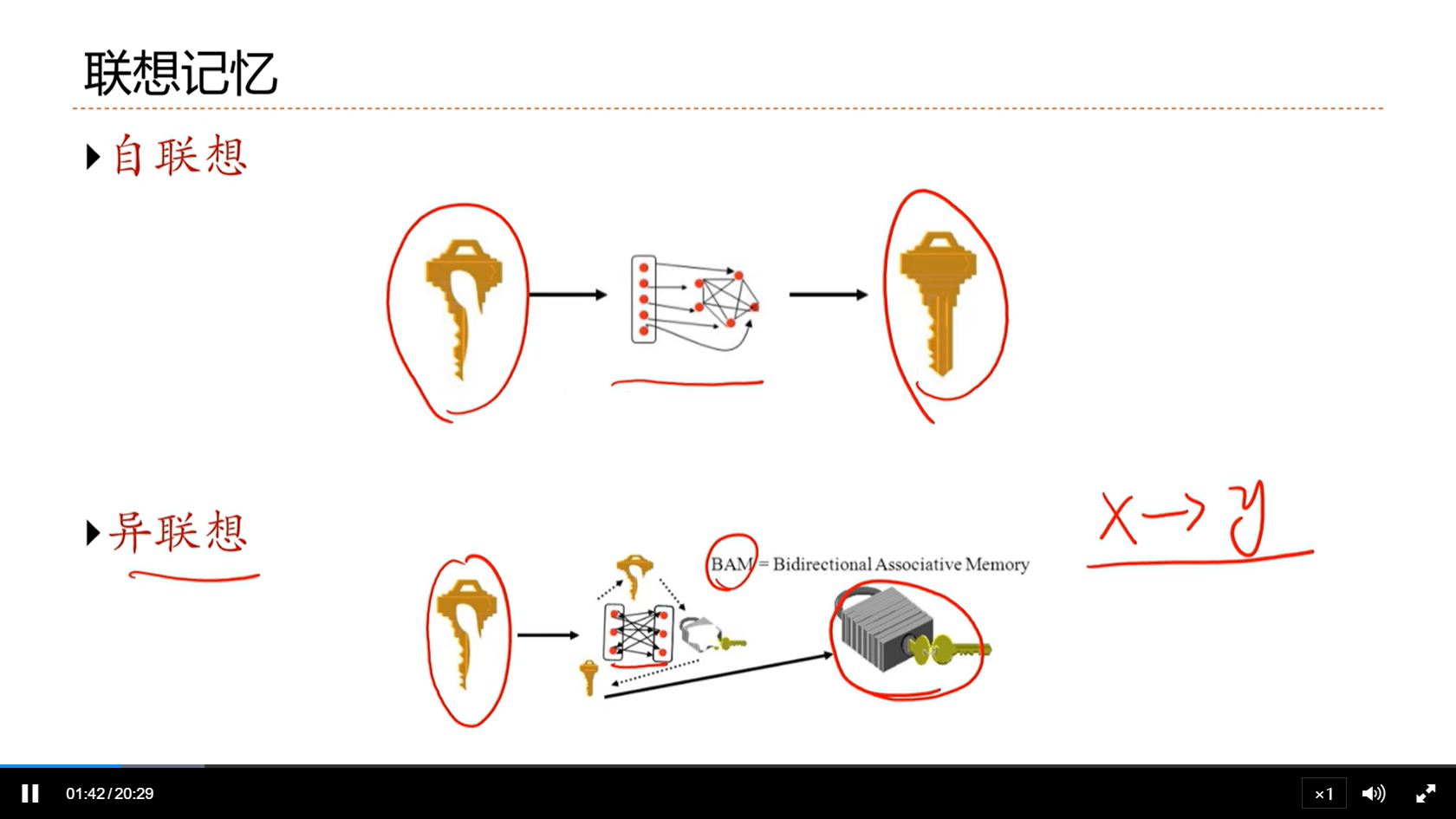
[√] 如何实现联想记忆
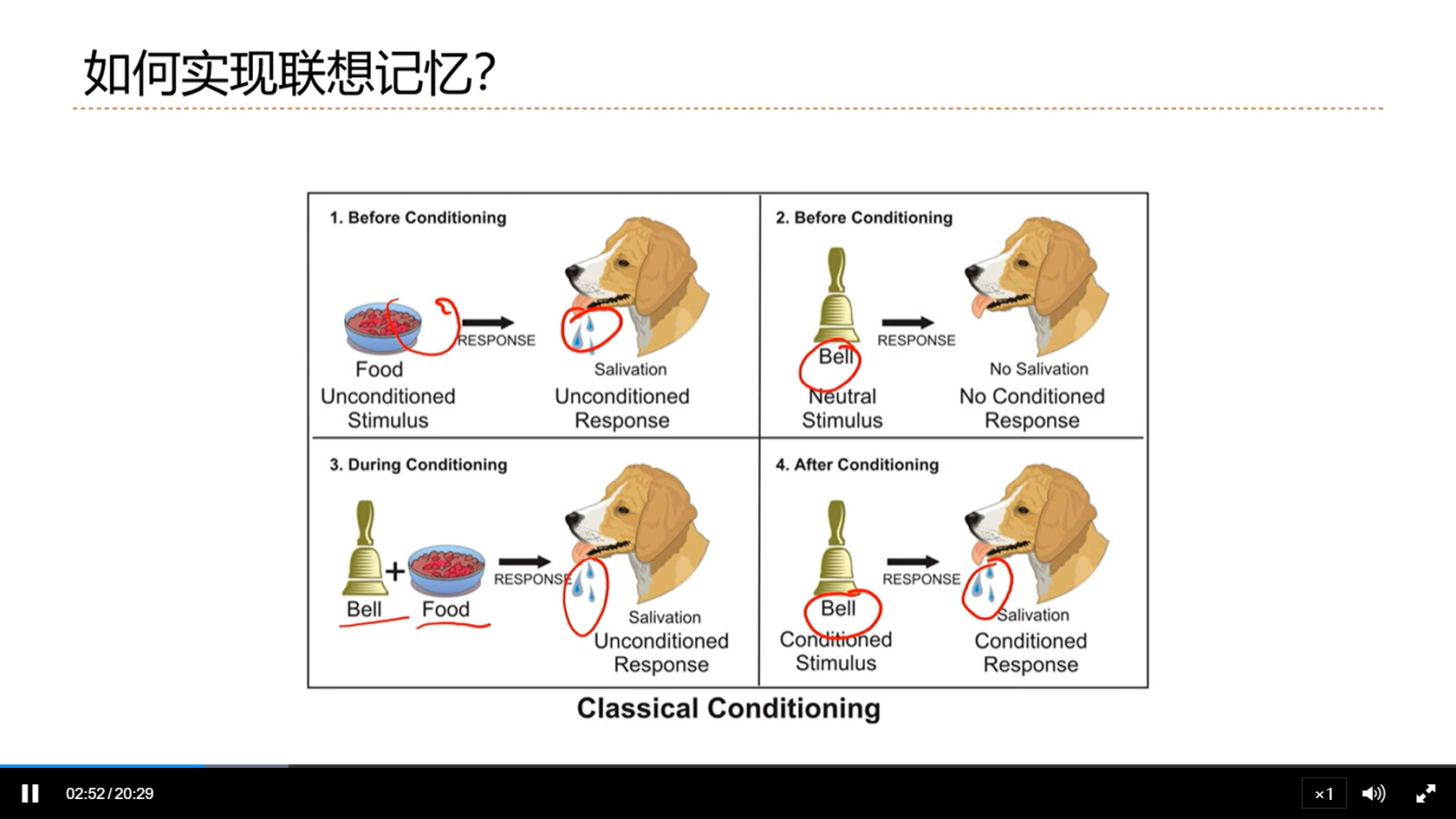
[√] 神经网络如何学习?

alec:
- 赫布法则:两个神经元AB,AB之间间接的兴奋等导致二者连接加强了,那么时间久了之后AB就能直接导致另一方兴奋了。即无意的刺激多了,神经元的联系就加强了。这种无意的刺激就变成了有意的刺激。
[√] Hopfield网络
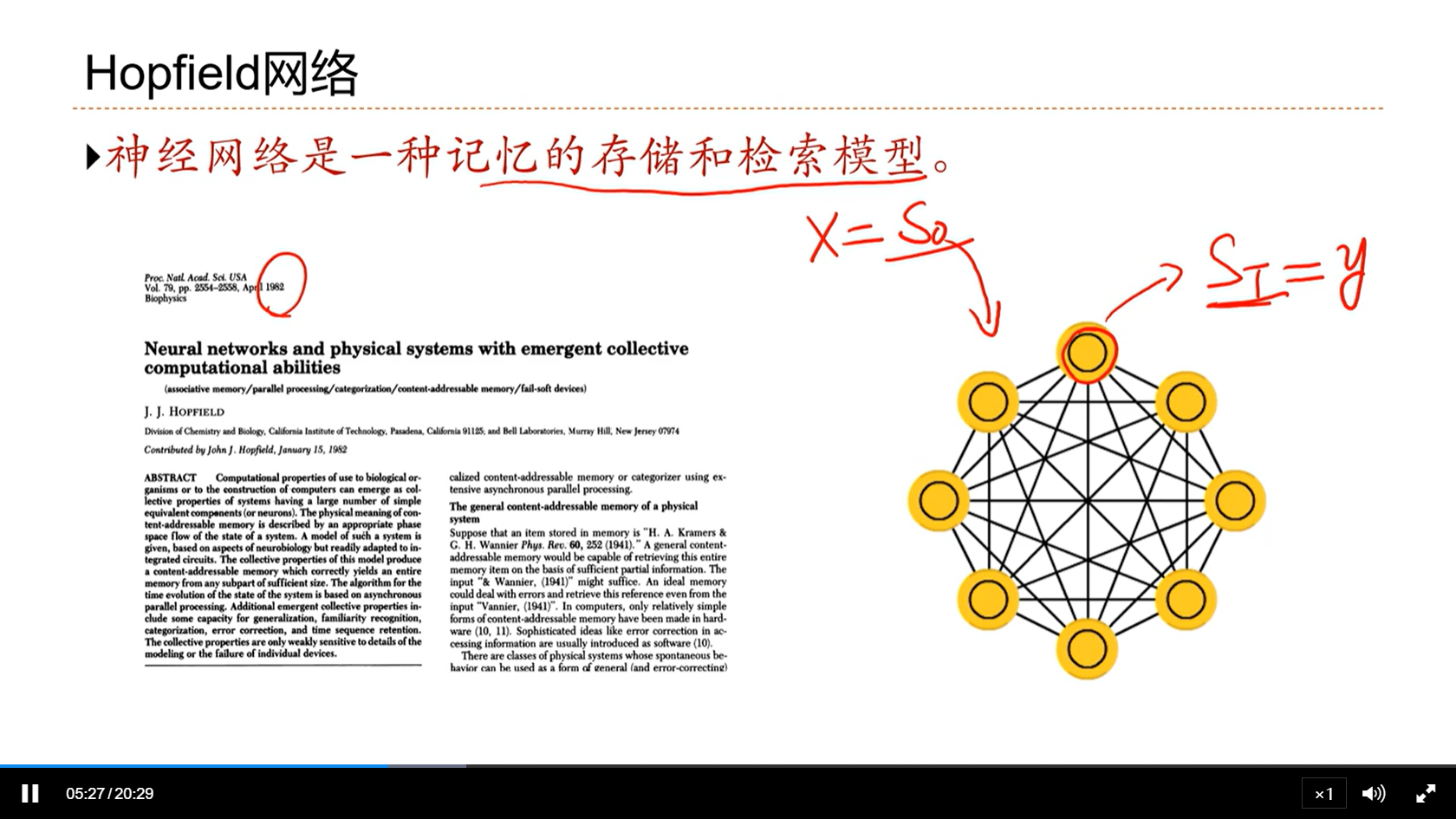
alec:
- Hopfield网络是赫布法则对应的人工神经网络的实现。
- 这个网络也可以看做是一个全连接的网络
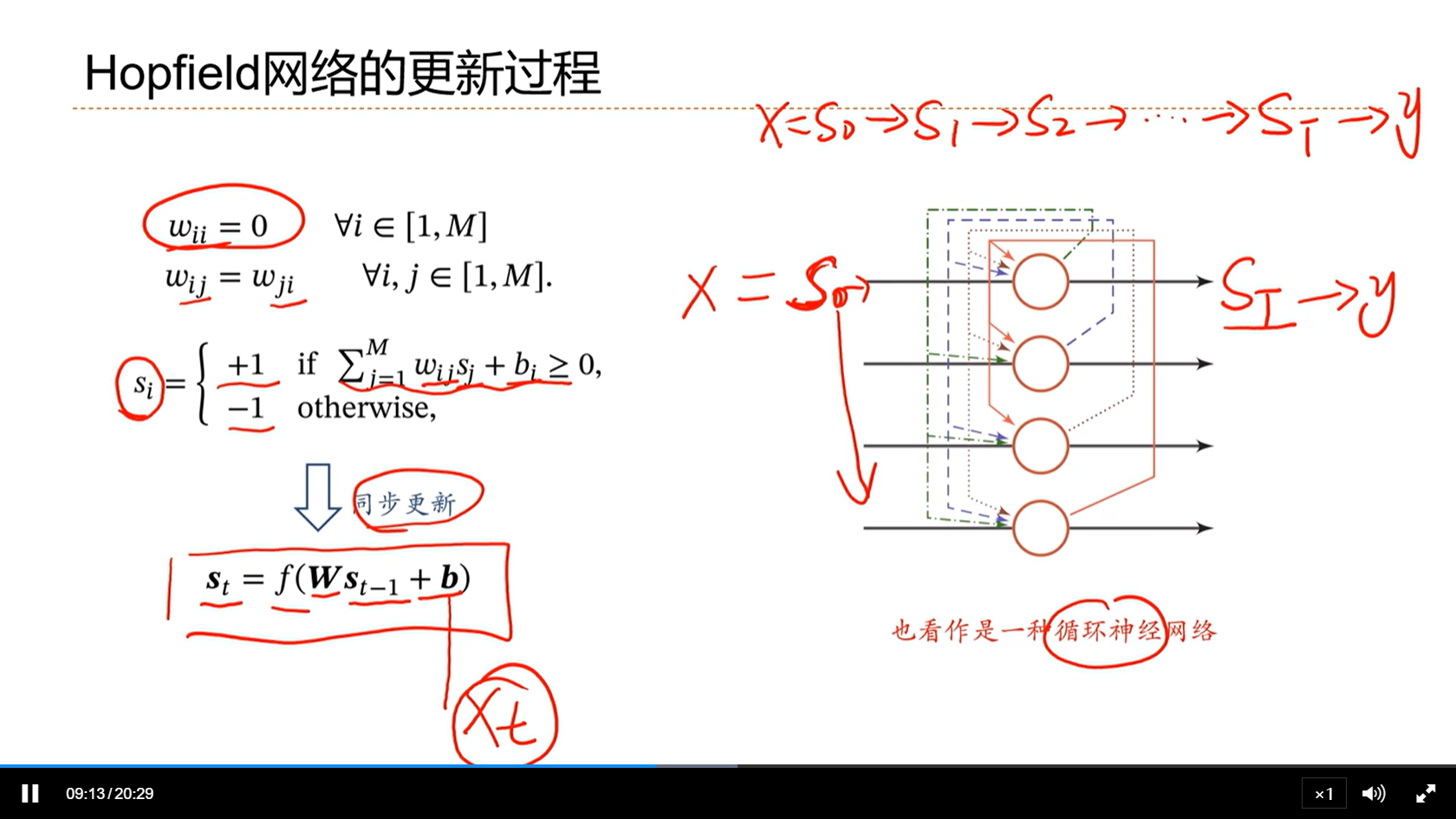
[√] Hopfield网络的更新过程
[√] 能量函数

[√] 检索过程(联想记忆)
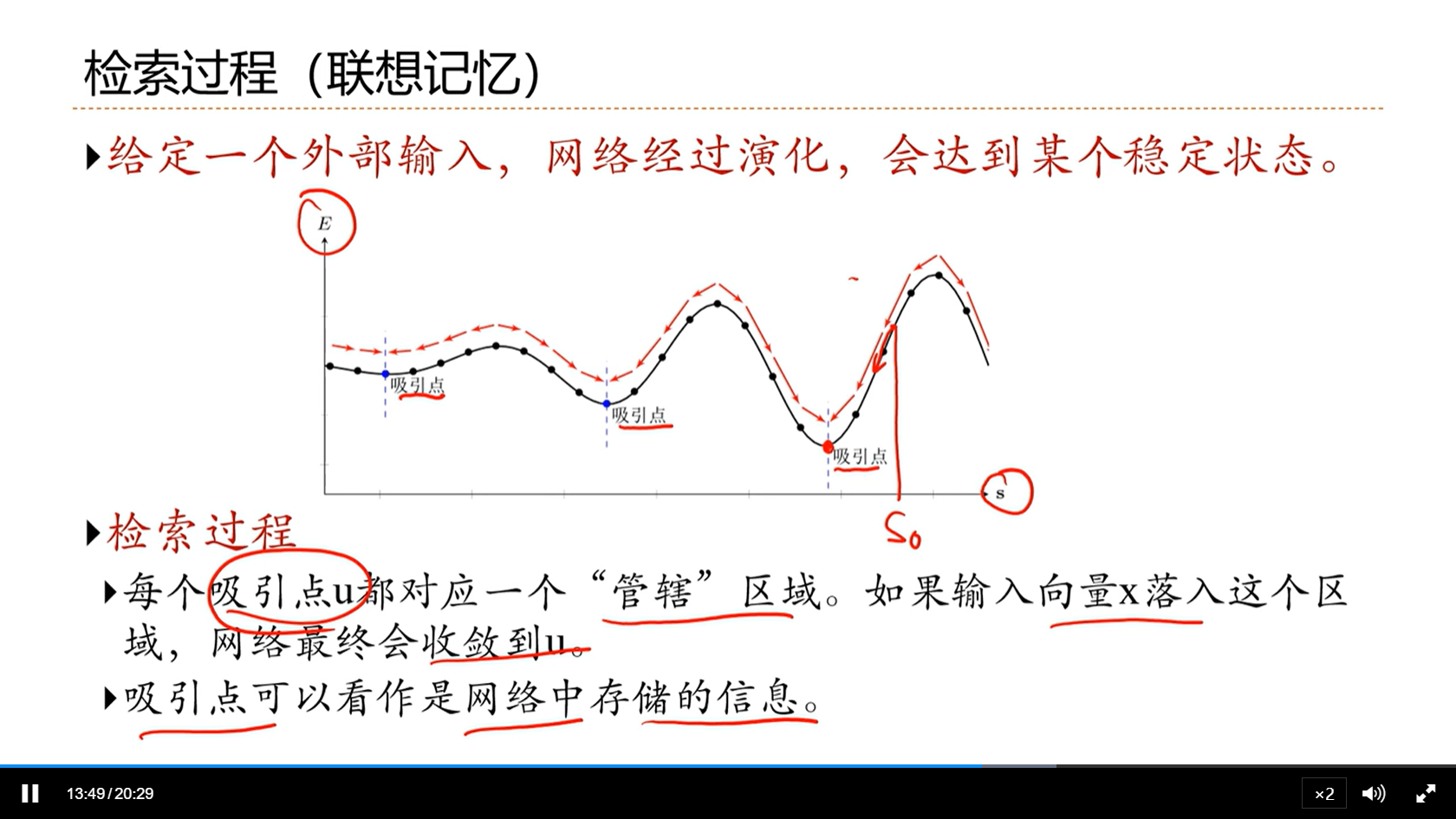
[√] 存储过程(学习过程)

[√] 使用联想记忆增加网络容量

[√] 8.9 - 总结
[√] 通用近似定理

[√] 总结

8 - 注意力机制
https://alec-97.github.io/posts/1405476561/