010 - 文章阅读笔记:当神经网络撞上薛定谔:混合密度网络入门 - 知乎 - 代码律动
本文最后更新于:3 个月前
原文链接:
当神经网络撞上薛定谔:混合密度网络入门 - 知乎 - 代码律动
编辑于 2018-06-12 18:20
ps:本文为依据个人日常阅读习惯,在原文的基础上记录阅读进度、记录个人想法和收获所写,关于原文一切内容的著作权全部归原作者所有。
alec:
【混合密度网络】
通过组合高斯概率分布,理论上我们可以逼近任意概率分布。
【混合密度网络的实现方式】
所以我们的思路就比较清晰了:我们要设计这么一个网络,输入 x ,输出一个混合概率分布(即多个 mu 和 sigma 的组合值),而我们需要获取真正的预测值的时候,就从这么个混合概率分布中产生一个随机值,多次取随机值则可以得到所有 y 的可能值。混合概率网络的实现也很简单,我们设计一个具有两个隐藏层的网络,输出层节点数为 12 * 3 个,可以表示为 12 个高斯分布的叠加,我们用前 12 个节点表示 12 个高斯分布叠加时各自的权重,而中间 12 个表示平均数 mu,最后 12 个表示标准差 sigma。(2个隐藏层 + 输出层为x乘3,其中x为设定的组合的高斯分布的个数,3为权重、均值、方差)
[√] 概述
你一定听说过『神经网络络可以拟合任意连续函数』这句话。
没错,通过增加网络的隐藏层数量和隐藏层大小,你可以得到强大的学习网络,无论是二次三次函数,还是正弦余弦,都可以用你的网络进行无限逼近。
好了,打住,今天我不是来教你逼近这种简单函数的(这种内容应该在学习深度学习的第一天就已经解决了)。让我们来考虑这个情况——当我们要拟合的『函数』,不止有一个值会怎样?
严格来说,『多值函数』不是严谨的定义,良好定义的『函数』在其定义域内的每个输入都对应一个输出,而且只对应一个输出[1]。然而实际上我们经常要处理一些多值问题,比如反三角函数(arcsin, arccos 等等),所以现在问题来了,当我们希望拟合的函数有多个输出值的时候,我们的神经网络模型应该怎么定义呢?
本文全文源码以及可视化代码由 jupyter notebook 编写,文末有源代码获取方法。
alec:
- 神经网络,考虑拟合单值函数。即一个输入对应一个输出。
- MDN,用来试着解决一个输入对应多个可能的输出的拟合问题。
[√] 第一个任务:单值函数拟合
让我们先回忆单值函数是怎么拟合的。
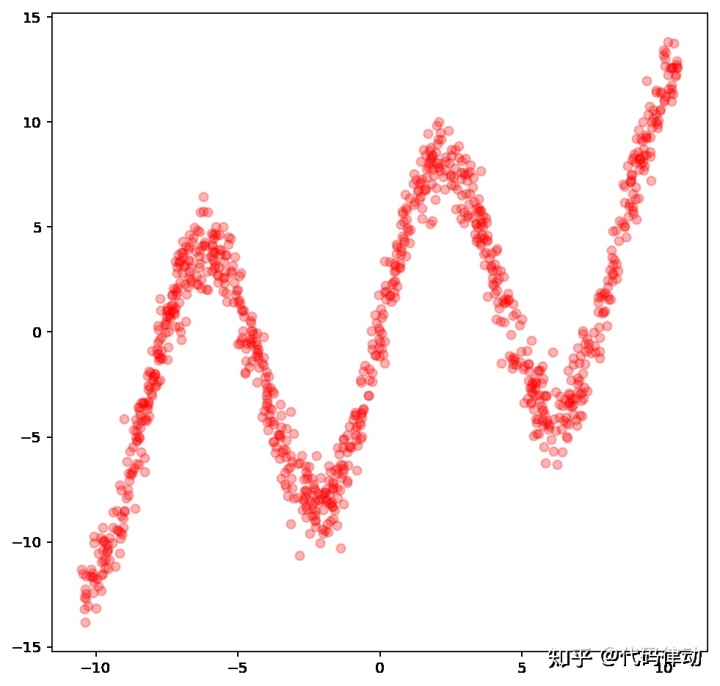
我们首先要设计一个函数,以产生点集,用于后面的拟合,我们选用的是正弦函数和线性函数的混合函数:
f(x)=7.0sin(0.75x)+0.5x
在生成数据的时候,还会加入一些随机的噪声。
1 | |
这些数据点可视化的结果是这样的:
现在我们设计一个具有一个隐藏层的简单网络进行拟合,我们希望用神经网络模型设计一个函数y = f'(x),在一定区间上可以达到处处|f'(x) - f(x)| < ε,这个表达式是 L1 的形式,可以直接当做我们的 loss 函数。当然,我们也可以使用 L2 (平方差)来设计我们的 loss 函数。
我们将使用 tensorflow 来实现我们的网络:
1 | |
现在我们看一下结果,其中蓝色是训练数据,红色是网络的输出值。
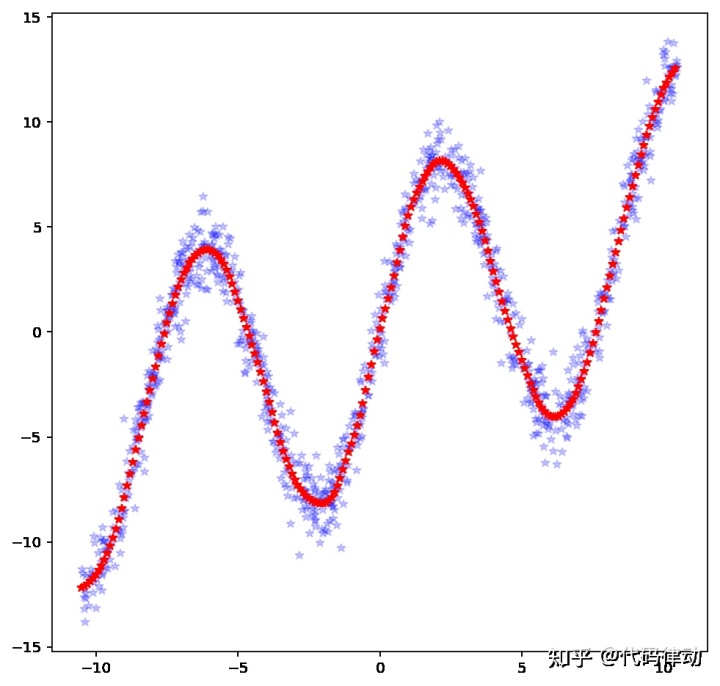
可以看到,红色的点几乎完美地排成了一条阶段上升的曲线。
[√] 交换坐标轴
现在我们进一步,将数据点的 x 轴与 y 轴交换,这样我们就有了一个多值函数的输入。在 python 中,交换两个轴的数据非常简单:
1 | |
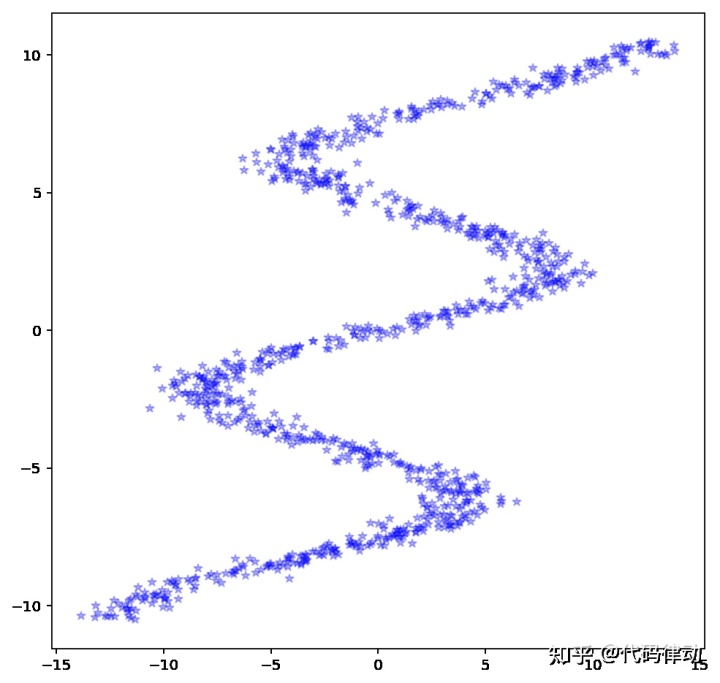
现在我们的 x 可能会对应多个 y,如果再套用以前的方法,结果就不那么理想了。
1 | |
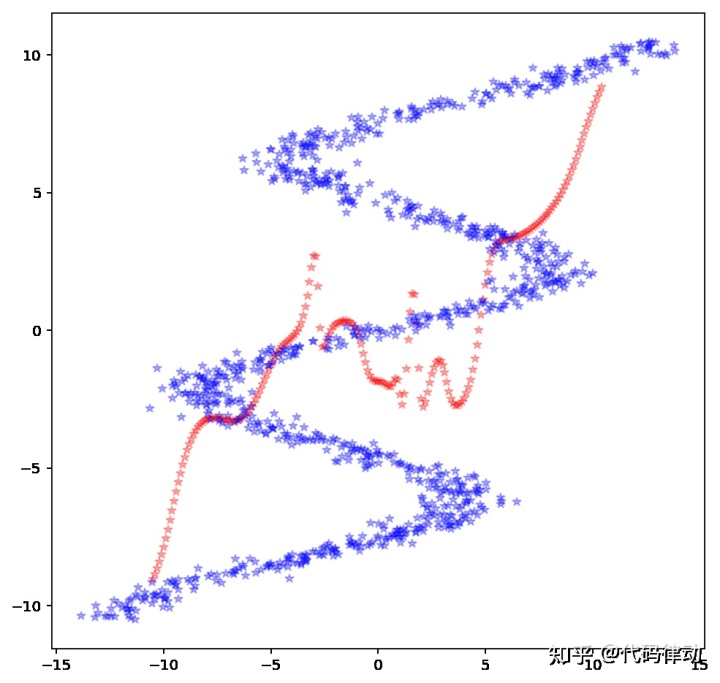
是的,我们原来的模型已经失效了,无论增加多少层,增大多少节点数,都不能拟合多值函数曲线。所以,现在我们应该怎么办?
alec:
- 因为神经网络拟合的是单值函数,但是这里输入的数据是多值数据。所以无法使用单值函数拟合多值数据。
[√] 混合密度网络:薛定谔的猫
在前面的代码中,我们对于多值函数的预测走入了一个误区:我们的神经网络最后的输出是一个确定值,然而实际上我们需要的是多个『可能』的值。你也许会想,用神经网络输出多个值并不难呀,只要定义最后的输出层节点数大于 1 就可以了。是的,你可以定义一个多输出的网络(比如 3),然后每次输出 3 个预测值,然而这个网络的效果肯定是非常差的(你可以自己思考一下为什么)。
alec:
- 为什么?
现在我们换一种思路——假如我们输出的不是一个值,而是目标值的一个『可能分布』,比如当 x=1 时,我们得到 y 有两个取值 { 1, -1 },并且每个取值的概率都是 0.5。这就像薛定谔的那只量子叠加态的猫一样,我们得到的结果是一个概率分布,只有当我们进行一次『观察』时,才会得到一个具体结果!
使用这个思想设计的网络就叫混合密度网络(Mixture Density Network),用处相当大。
你也许会问,概率究竟应该怎么表示呢,难道是输出一个类似 one-hot 表示的数组吗?显然我们不能使用 one-hot 来表示这个概率分布,因为我们输出的值域是连续的浮点数,我们不可能用有限的数组来表达。这里就要引入一个统计学里面的很常见的概念了,就是高斯分布。
高斯分布的概率密度曲线表示为: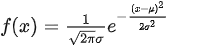
这里面的参数只有两个,一个是均值 mu,一个是标准差 simga,通过改变这两个量,我们可以得到多样的概率分布曲线。
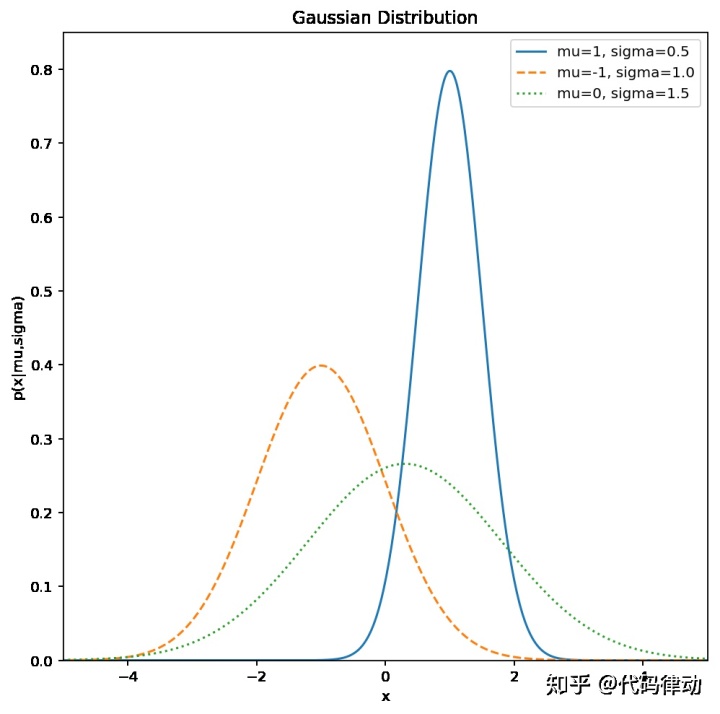
而通过组合多个高斯概率分布,理论上我们可以逼近任意概率分布。比如将上面的三个分布按概率 1: 1: 1,混合为一个分布:
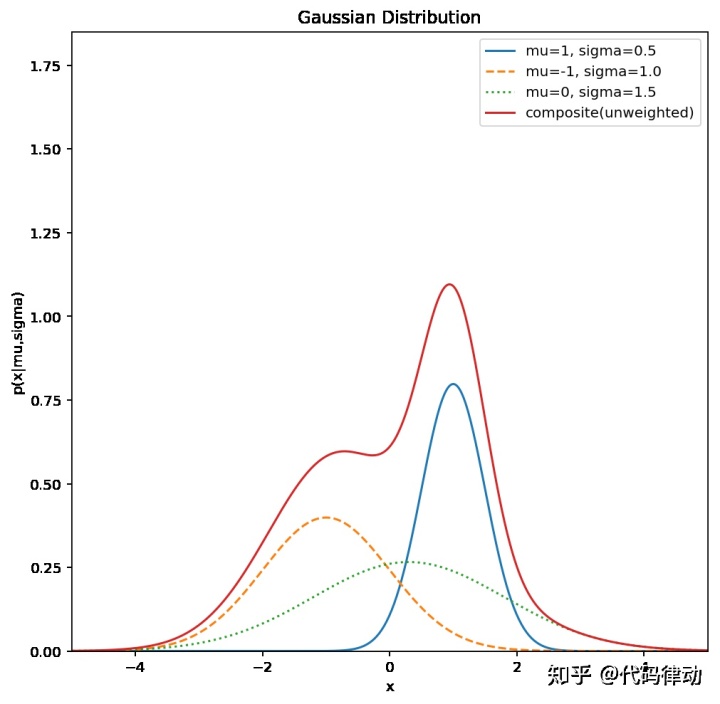
所以我们的思路就比较清晰了:我们要设计这么一个网络,输入 x ,输出一个混合概率分布(即多个 mu 和 sigma 的组合值),而我们需要获取真正的预测值的时候,就从这么个混合概率分布中产生一个随机值,多次取随机值则可以得到所有 y 的可能值。混合概率网络的实现也很简单,我们设计一个具有两个隐藏层的网络,输出层节点数为 12 * 3 个,可以表示为 12 个高斯分布的叠加,我们用前 12 个节点表示 12 个高斯分布叠加时各自的权重,而中间 12 个表示平均数 mu,最后 12 个表示标准差 sigma。
1 | |
我们的 loss 函数不能是和之前一样的平方差来表示,我们希望最大化真实的 y 值在混合概率密度中的概率,将经过标准化的 y_normal 与概率权重相乘,并取对数相加后取相反数,这个结果就是概率联合分布的最大似然函数。
1 | |
运行网络:
1 | |
生成数据测试一下。
1 | |
注意,由于我们得到的是一个概率分布,所以还需要根据预测出的联合概率密度来随机生成具体的点。在测试中,我们对于每一个输入 x 都成生 10 个随机点。最终得到的生成图像如下:
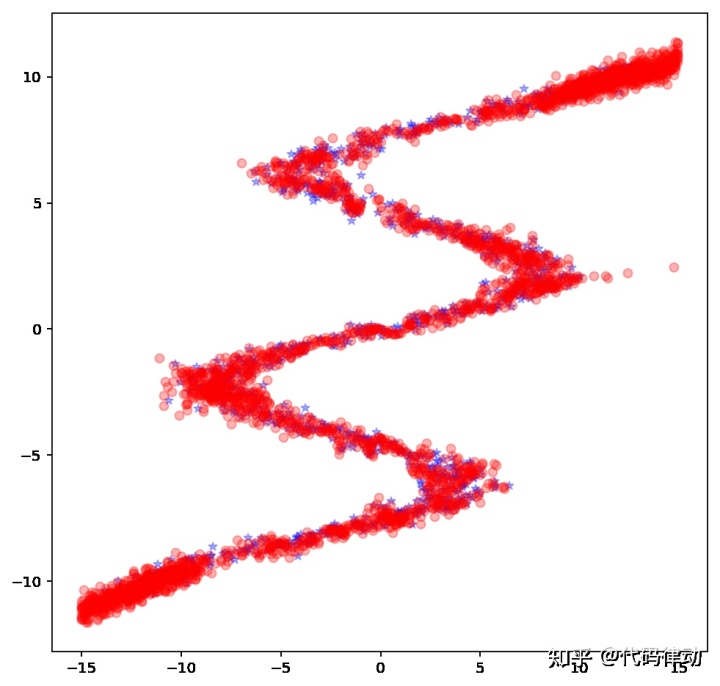
wow!完美,我们的混合密度网络真的拟合了这个多值函数,虽然有一点小瑕疵,实际上我自己通过增加节点数或者隐藏层后,生成的图像非常好,你也可以动手试试。
本文代码大量参考自[2]。如果对编程感兴趣,欢迎加入我们的讨论群:745478917,一起学习魔法。
以上全文以及可视化代码已经制作成了 jupyter notebook 文件,可以关注公众号『代码律动codewaving』,回复 mdn 获取下载连接。
[1] https://zh.wikipedia.org/wiki/%E5%A4%9A%E5%80%BC%E5%87%BD%E6%95%B0
[2] http://blog.otoro.net/2015/11/
[√] 评论
本质上来说,(基于平方损失的)用于回归的神经网络是得到了一个条件概率分布p(y|x),并且p(y|x)是正态分布,由于正态分布是单峰的,所以回归一般的单值函数会有不错的效果。然而在拟合多值函数的情况下,p(y|x)变成了一个多峰的分布,用普通的神经网络性能当然不好。近似多峰分布最简单最自然的想法就是用混合高斯分布。详细的内容在PRML神经网络一章都有清楚的推导,如果我这段没写明白,可以去翻翻PRML。