037 - 文章阅读笔记:RepSR:通过结构重新参数化和批量归一化来训练高效的VGG式超分辨率网络(探究sr中的bn) - CSDN - hbw136
本文最后更新于:3 个月前
转载自:
【√】RepSR:通过结构重新参数化和批量归一化来训练高效的VGG式超分辨率网络(探究sr中的bn) - CSDN - hbw136
于 2022-05-17 19:52:30 发表
RepSR: Training Efficient VGG-style Super-Resolution Networks with Structural Re-Parameterization and Batch Normalization
(RepSR:通过结构重新参数化和批量归一化来训练高效的VGG式超分辨率网络)
作者:1.Xintao Wang, 2.Chao Dong,3.Ying Shan
单位:ARC Lab, Tencent PCG, Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences; Shanghai AI Laboratory
代码:https://github.com/TencentARC/RepSR.(暂未放出)
论文地址:https://arxiv.org/pdf/2205.05671
[√] 一、问题亮点
1.将训练的多分支架构sr网络模型直接用于测试通常会导致较差的性能表现,要如何去解决这个问题?
2.在当前的sr网络中BN通常被替换或删去,因为它通常会带来性能损失和奇怪的伪影,还有就是bn在sr领域也缺乏相关研究。
[√] 二、主要思路和亮点
- 作者详细分析了 BN 伪影的原因,并提出了一种有效解决此问题的简单策略。
- 提出了一个简单而有效的 SR 可重参数化块用于解决问题一。 它在不同模型大小之间实现了优于以前的重新参数化方法的性能。
- 基于RepSR,作者能够训练出高效的 VGG 式 SR 网络。 与以前的 SR 方法相比,它可以在性能和吞吐量之间取得更好的平衡。
[√] 三、细节
[√] 1、模型结构
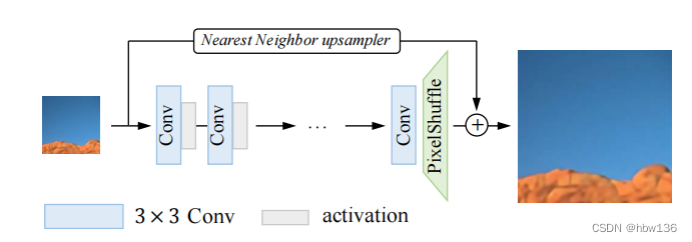
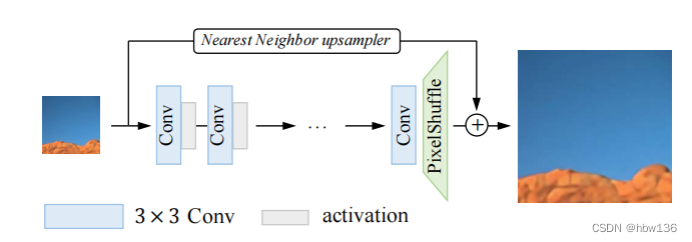
基础网络结构,它有一个普通的 VGG 风格的网络结构,带有一堆 3×3 卷积和激活层。 RepSR 块,它由一个纯粹的残差path、两个带有 Frozen BN 层的扩展和压缩path组成。 在推理过程中,RepSR 块可以合并为一个标准的 3×3 卷积。
alec:
- 本文设计了RepSR块。
- 本文的创新的结构是,将残差块中的残差部分,由1个变成了2个。
- 本文在全局跳跃连接中,加入了最近邻上采样器。
作者展示了SR 网络简洁的结构,如上图所示。 为了保持较低的计算成本和内存消耗,基础网络具有普通的 VGG 式网络结构,即堆叠使用 3×3 卷积和激活层。 作者在网络末端使用像素洗牌层(pixel shuffle)执行上采样操作。 采用简单的最近邻上采样器作为全局跳跃连接。 作者在实验中使用 PReLU作为激活函数。并且已被证明比其他复杂的网络结构更易于部署。
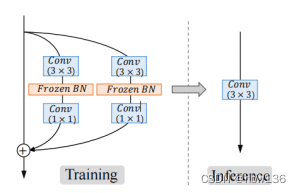
[√] 2、Re-parameterization Block for SR
作者使用重新参数化去解决多分支网络的问题,即在训练期间使用多分支架构,然后将它们合并到标准的 3×3 卷积中进行测试。 其中批量归一化(BN)在最近的研究中展现出了对于在训练期间引入非线性和提高最终性能的重要性。因此,在此基础作者提出了RepSR块,它将BN重新引入到SR的重新参数化中。作者进一步改进了RepSR的详细结构,使其更适合于SR任务。在RepSR的设计中也考虑了结构的简单性。
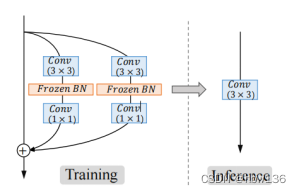
alec:
- 所谓的重新参数化,就是将训练期间的网络参数,在测试的时候,将其合并到一个标准的3x3卷积中,这个让网络结构更加简单、易于部署。
[√] 3、REVISITING BATCH NORMALIZATION IN SUPER-RESOLUTION (研究bn在sr的作用)
批量归一化(BN)在卷积神经网络(CNN)中得到了广泛的应用,它有效地简化了收敛过程,从而提高了性能。给定一个CNN特征x,BN通过使用平均μ和方差σ2将x归一化来计算输出y:
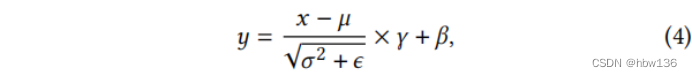
其中,λ和β是可学习的仿射参数,ε是数值稳定性的一个小值。在训练过程中,计算小批次上的每个通道的平均值和方差,而在推理过程中,从训练集估计的总体统计数据用于归一化。
但是,BN 对 SR 不友好。 它往往会在推理过程中引入令人不快的 BN 伪影,如上图所示。输出中混杂着不自然的颜色,导致 PSNR(峰值信噪比)大幅下降。 有时,此类伪影是轻微的,乍一看甚至难以察觉,导致性能略有下降。 因此,BN 通常在 SR 网络中被删除。 为了弥补由于没有 BN 导致的优化问题,一些替代技术,或更长的训练被用于训练更大的网络。
alec:
- BN能够简化收敛过程,从而提高性能。但是BN在SR任务中,会带来伪影等问题。因此在SR任务中,一般不用BN。

对此我深有体会,所研究的模型中有大量的bn,最近则遇到了类似的情况,推理过程中会有特定位置的伪影,不知道怎么解决,现在理解了确实可能是bn造成的,这也使得验证结果忽高忽低。


作者也对bn伪影进行了研究,从观察结果开始分析——那些BN伪影更有可能出现在图像的平滑区域。这些平滑区域明显有一个非常不同的局部方差,这表明伪影可能与BN中使用的不正确统计数据有关。有趣的是,如果批量归一化通过输入图像本身的统计数据而不是总体统计数据来规范化特征,BN伪影可以大幅减少。这一现象意味着BN伪影的原因可能是由于训练测试的不一致,即小批量统计和population之间的不一致。
alec:
- BN更可能出现在图像的平滑区域。
- 如果通过图像本身的统计数据批量规范化,而不是使用总体的统计数据批量规范化,那么BN伪影可以大幅减少。
- 猜测可能是图像中出现伪影的原因是训练和测试的不一致。训练的时候,使用当前小batch的均值和方差进行BN,而测试的时候,使用训练数据总体的均值和方法进行BN。这种做法是否存在问题呢?
作者进行了一个实验来验证这一说法。作者从图3中的图像中裁剪LRpatch,其输出有严重的BN伪影。然后,作者将这个贴片粘贴到狒狒LR图像的中心,其输出明显很好,没有伪影,如下图所示。合并后的图像通过SR网络。有趣的是,BN工件仍然存在于粘贴的平滑patch上,而左侧patch不受影响。似乎这些“有问题的”patch产生了异常的特征统计数据作为它们自身的特征。由于SR网络更多地关注本地处理,并从头到尾保持空间信息(即不像识别等任务提取特征时通常会增加通道数),有问题的patch总是会产生BN伪影,无论它们是单独产生的还是与其他patch一起产生的。
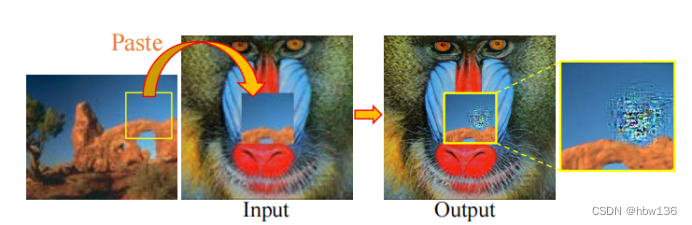
alec:
- 作者将能够产生伪影的patch,组合到SR良好的LR图像上,然后再超分,发现伪影的patch在超分之后仍然会产生伪影,良好的LR图像,超分效果仍然良好。
确实如此(自己魔改的含bn模型,伪影确实容易出现在平滑的位置)

基于作者的分析,减少训练-测试不一致性的一个直观的想法是在训练过程中使用population统计数据。因此,作者建议像正常的BN一样,首先用小批量统计数据来训练SR网络。在训练的后期,作者转向使用population数据。
alec:
- 作者猜想,BN产生伪影的可能原因是训练和测试的时候,BN的均值和方差数据的不一致导致的。训练的时候使用当前batch的均值和方差,测试的时候使用总体的均值方差。所以作者修改训练方式,在训练的前期使用当前batch的数据训练,后期则使用总体的均值和方差来做BN。
- 但是这种策略是否会牺牲性能?因为切换过程实际上改变了BN层的优化行为。从作者的实验来看,这种策略不会降低原本具有高性能的数据集的性能。
但是这种策略是否会牺牲性能?因为切换过程实际上改变了BN层的优化行为。从作者的实验来看,这种策略不会降低原本具有高性能的数据集的性能。1、用BN训练和用作者的策略训练的两个模型在set5上都获得了相似且良好的结果。此外,所提出的策略能够去除BN伪影,并提高性能(Set14,B100,DIV2K结果在Tab中。 1).综上所述,采用所提出的策略,作者可以享受到BN训练更快的收敛速度,而不受到BN伪影的影响。

[√] 四、实验
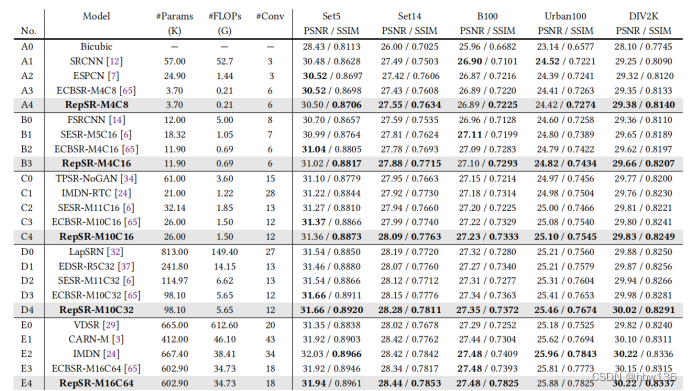

alec:
- 本文提出的模型,能够比ECBSR模型减少一半的训练时间,但是能够保持相同的性能。
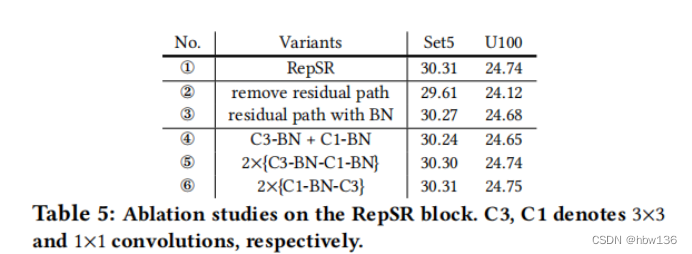
alec:
- C3和C1分别表示3x3的卷积和1x1的卷积。
[√] 五、总结
(1)作者提出了简单有效的重新参数化块,训练的时候使用RepSR,测试的时候,调整为使用3x3卷积。
(2)作者重新思考了BN的影响,提出了新的带有BN的训练策略。并证明了这个BN策略的有效性。
作者提出了RepSR,由简单而有效的重新参数化块组成。为了引入BN训练的非线性,作者仔细分析了BN伪影产生的原因,并提出了一种有效的策略来解决这个BN问题(bn在sr的伪影问题得到有效解决)。残差path和展开压缩卷积等设计,进一步提高了再参数化性能。所提出的RepSR允许作者训练高效的VGG风格的SR网络,以更快的推理速度实现更好的性能。