6 - 循环神经网络 - 视频
本文最后更新于:3 个月前
[√] 6.1 - 循环神经网络及应用模式
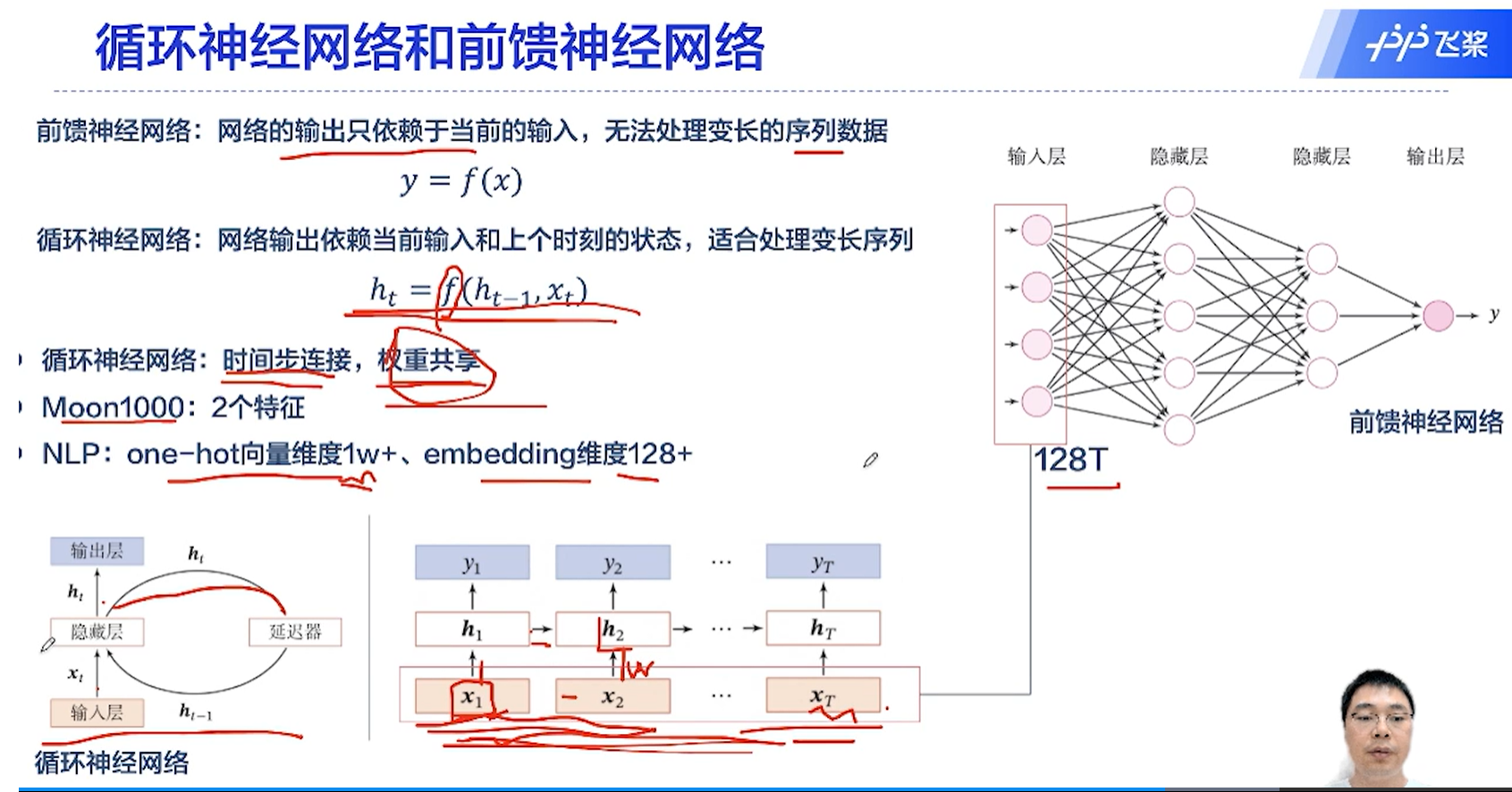
[√] 循环神经网络和前馈神经网络
alec:
- NLP:one-hot向量维度1w+、embedding维度128+
- ↑:将单词转成在计算机中的表示形式:编码为one-hot向量或者embedding编码
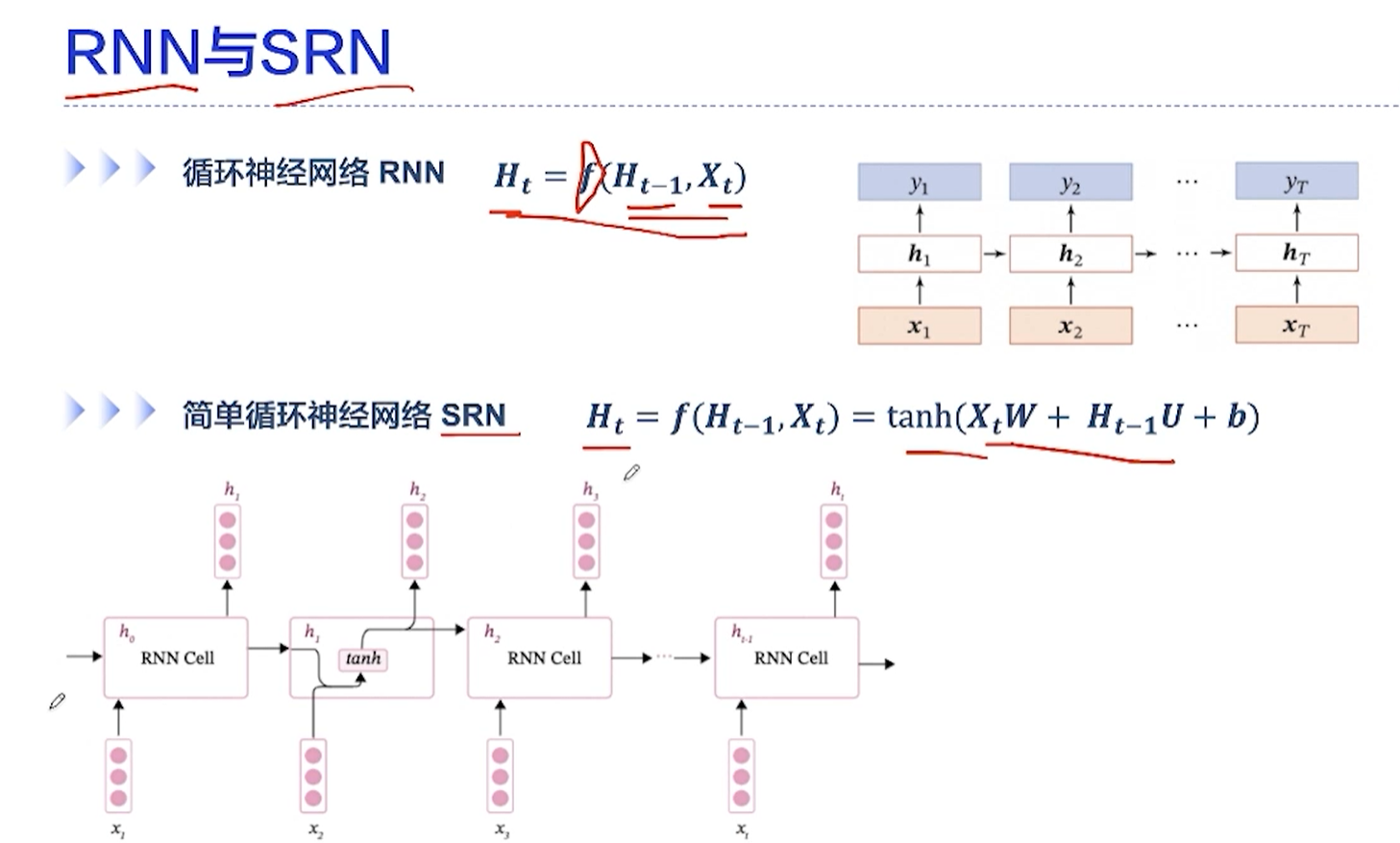
- 循环神经网络的显著特点:
- 时间步上的连接
- 权重共享
[√] 循环神经网络(RNN)

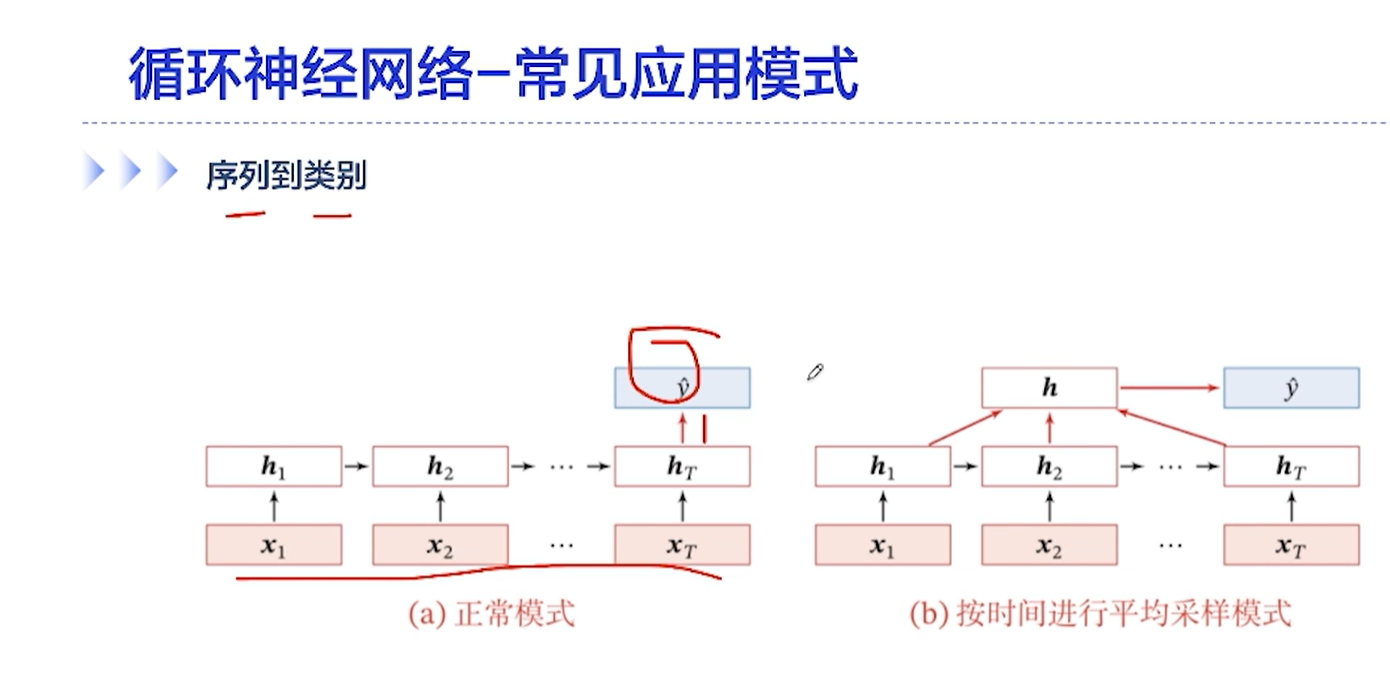
[√] RNN常见的应用模式
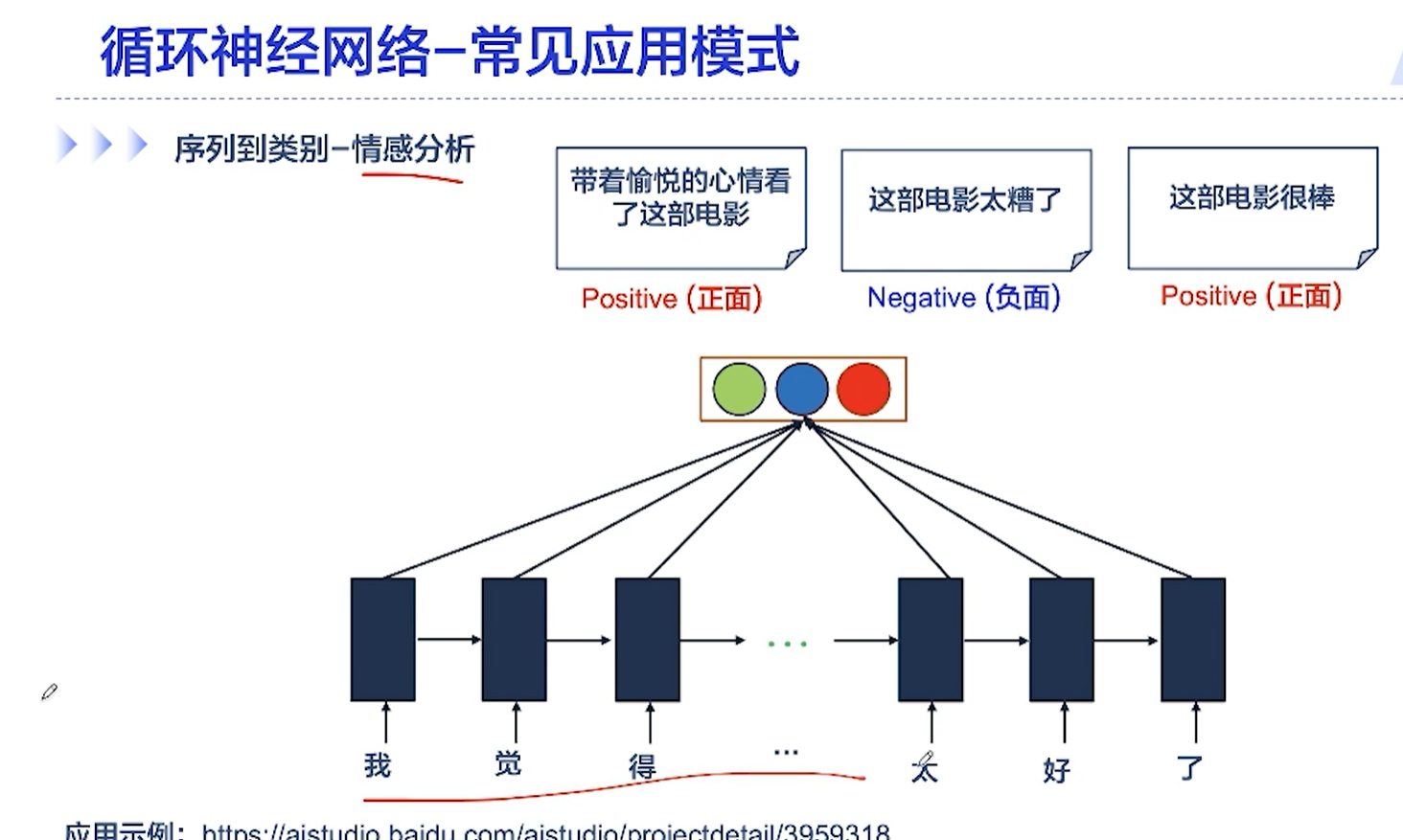
[√] 序列到类别
[√] 同步的序列到序列
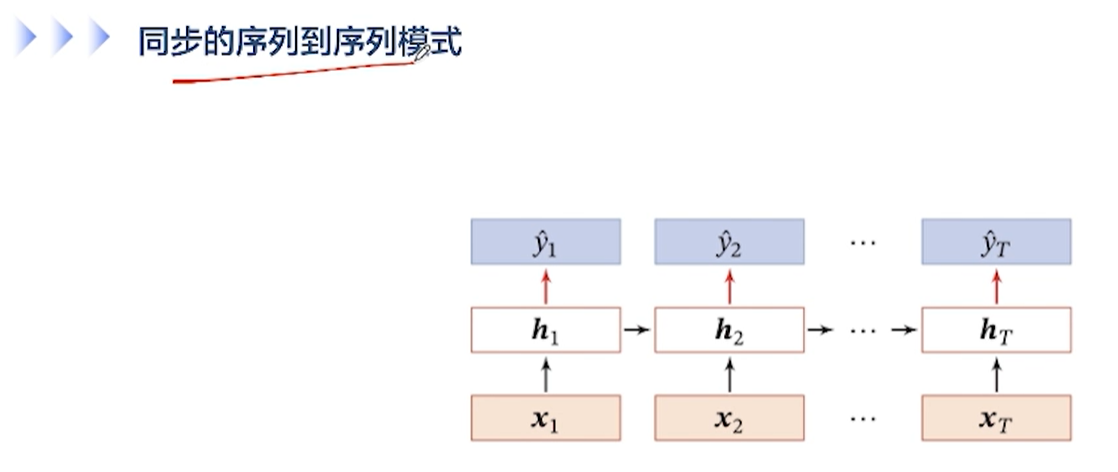
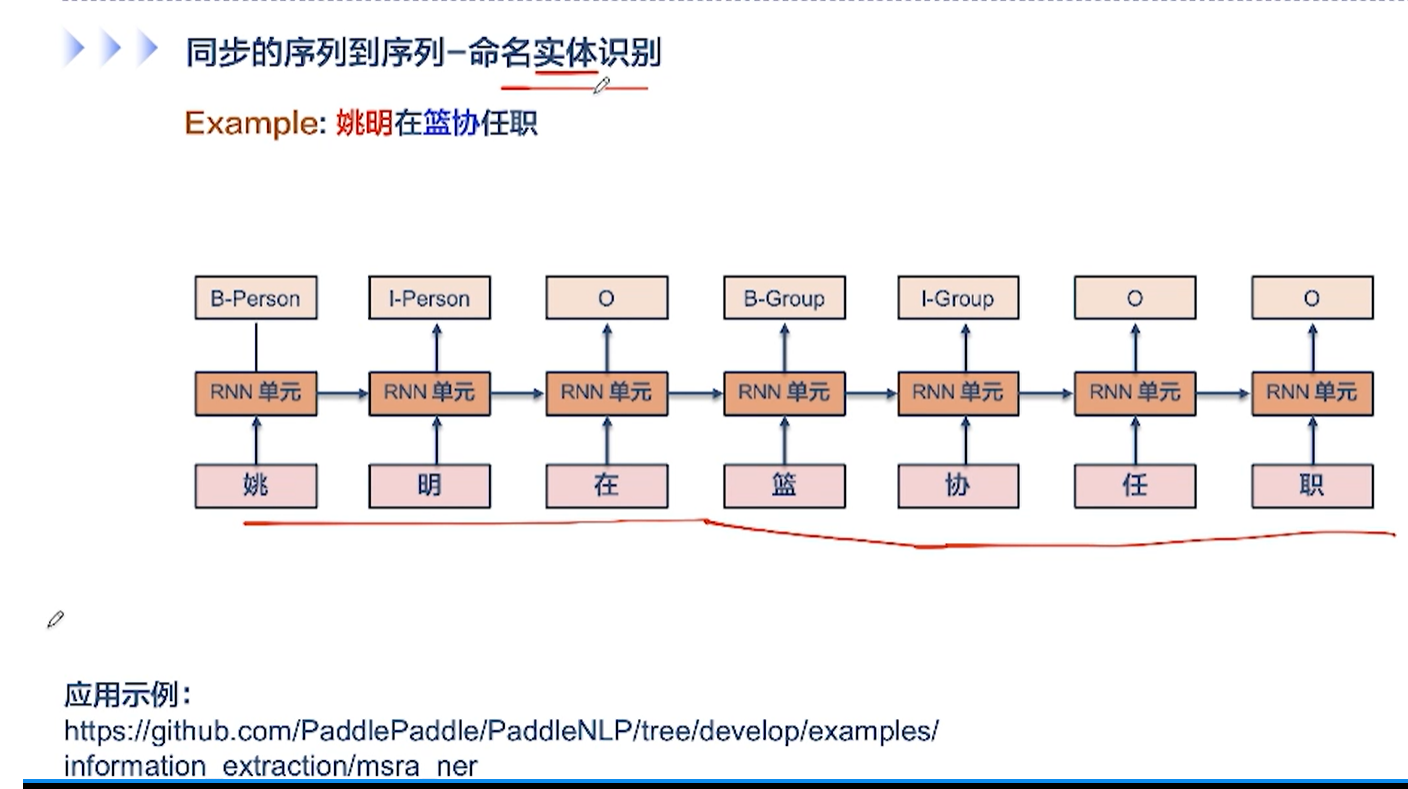
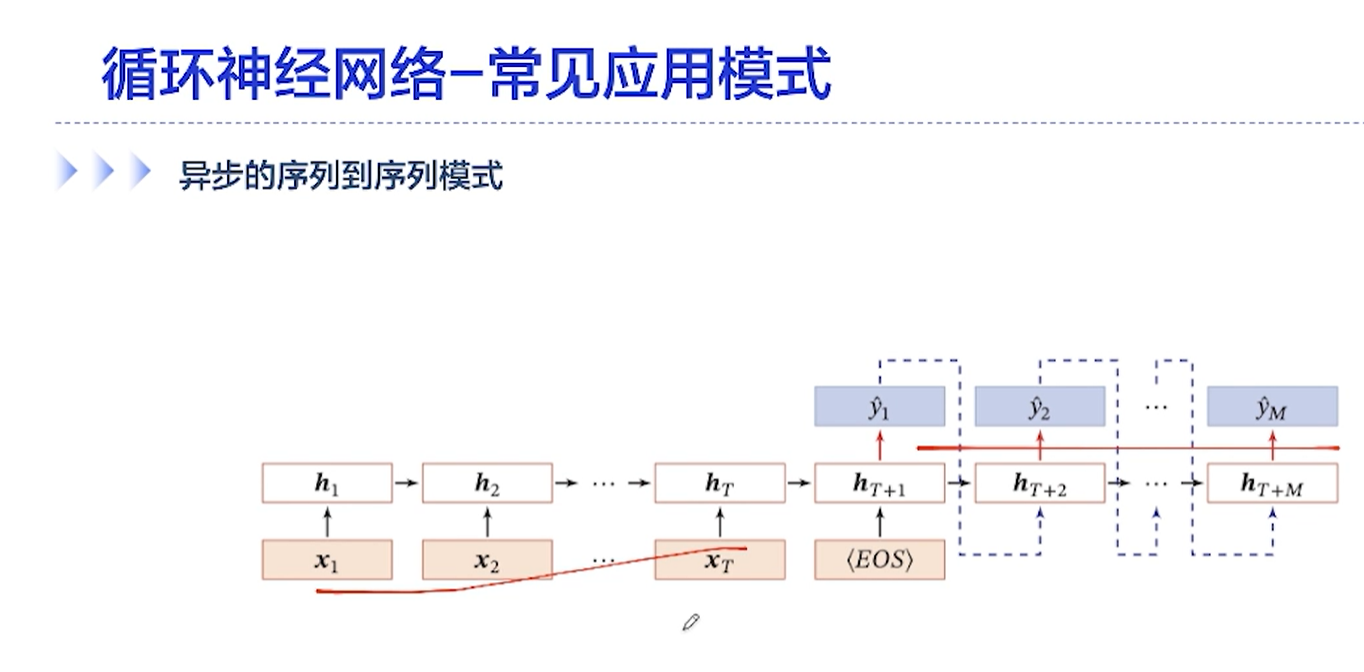
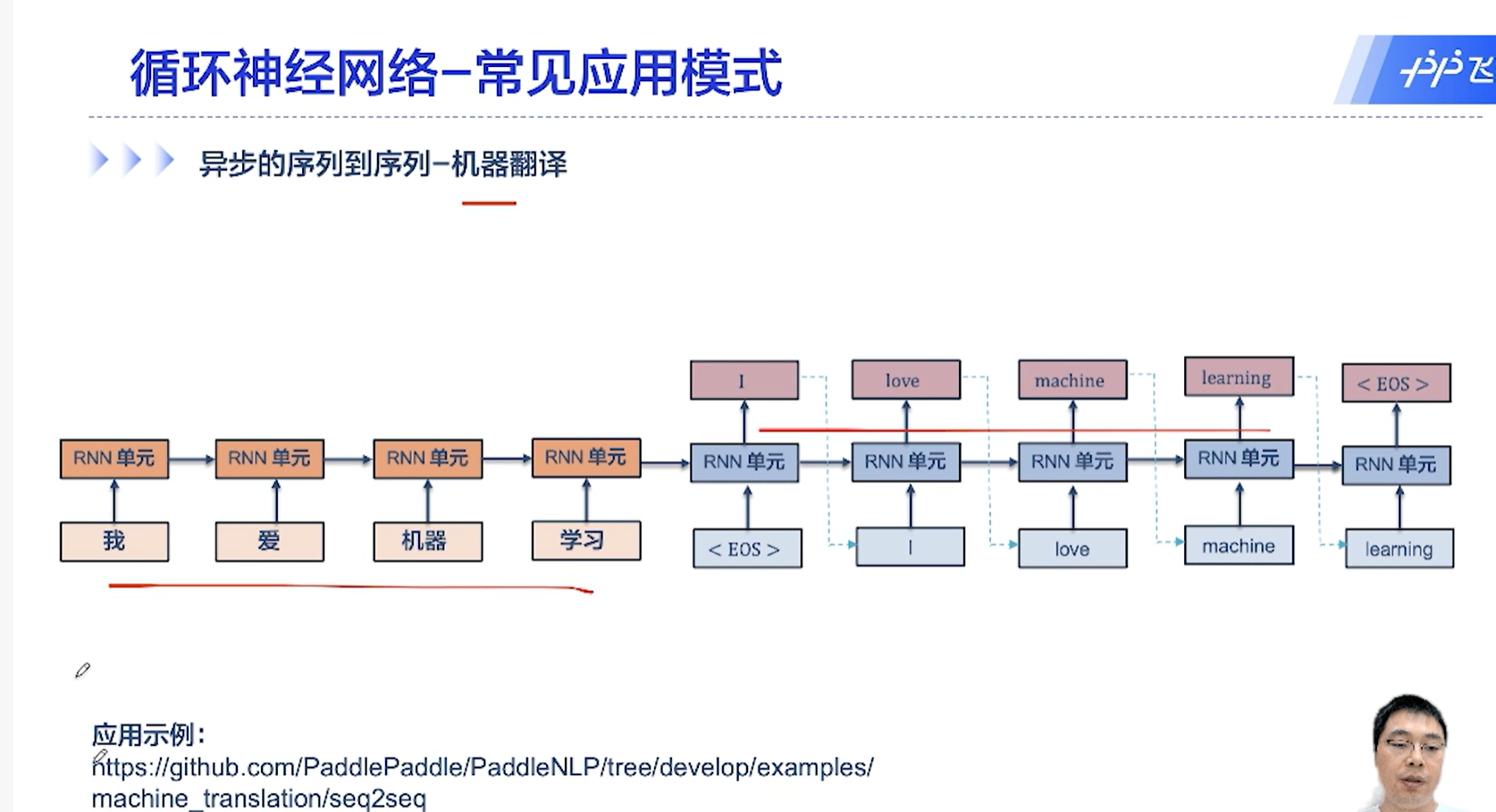
[√] 异步的序列到序列模式
[√] 6.2 - SRN的记忆能力实验
[√] RNN与SRN
[√] 机器学习实践五要素

[√] SRN记忆能力实验-模型构建
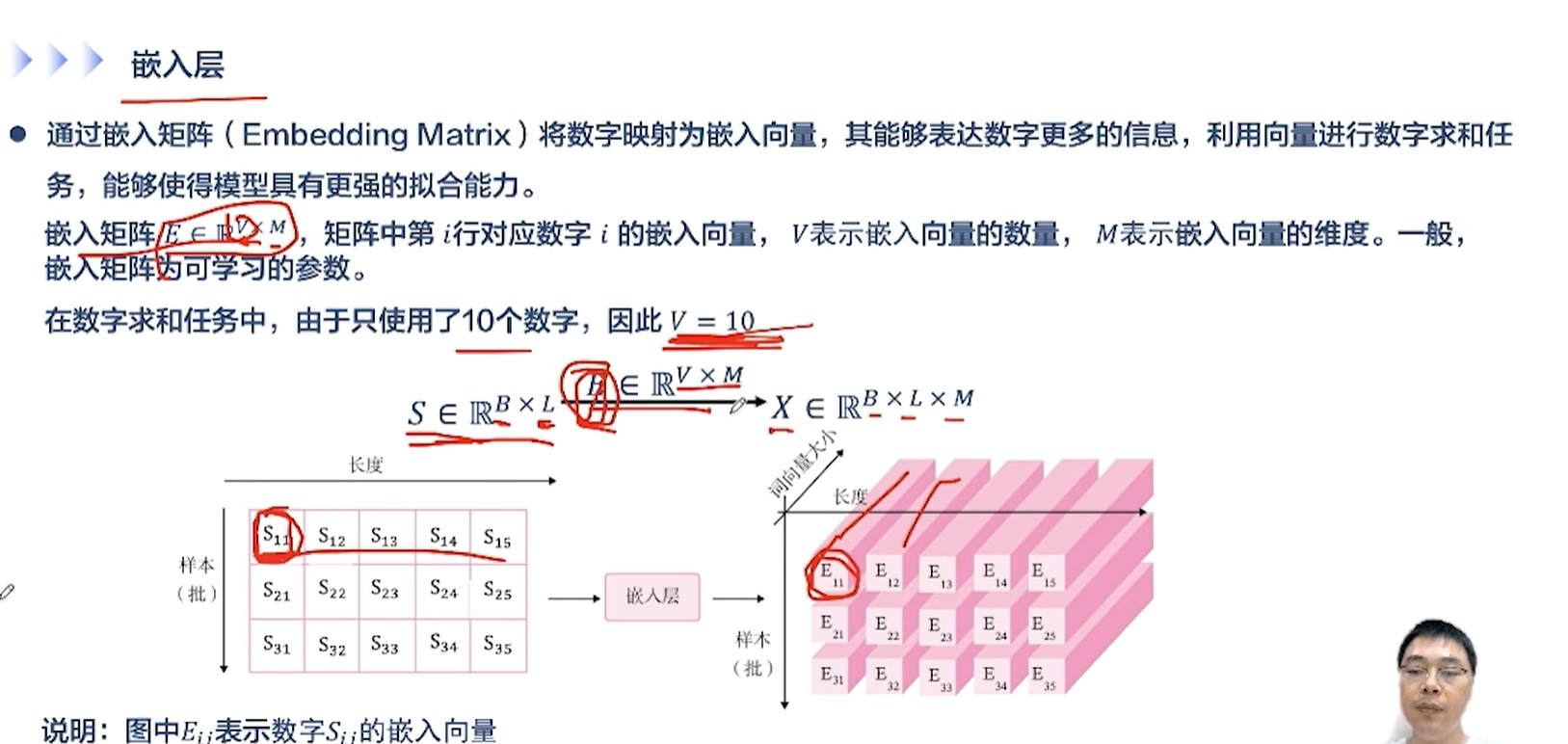
alec:
- 嵌入层的作用,是将输入的单词转换为一个向量,方便进行表示和学习
- 输入的shape为B×L×M,其中B是批量大小,L是时间维度的长度,M是单词转换为向量之后一个单词的通道数维度
[√] 通过查表和one-hot两种方式,将数字映射为向量

嵌入矩阵W的维度为(嵌入向量的数量A,嵌入向量的维度B),然后查表,输出一个维度为B的转换后的向量。
[√] SRN层
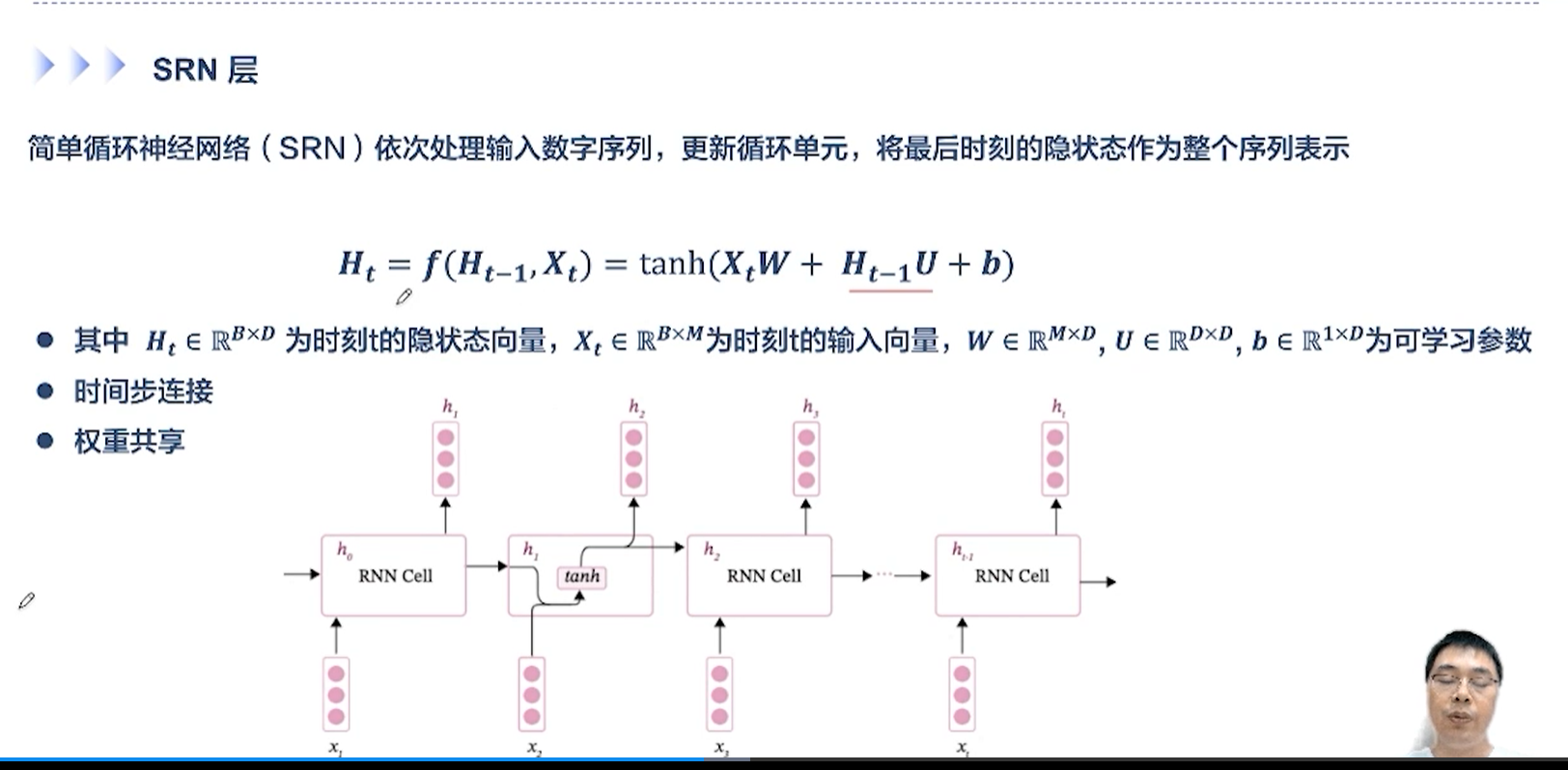
嵌入层将每个输入的单词,转换为一个M维的表示向量
输入向量的通道数维度为M,状态向量的通道数维度为D
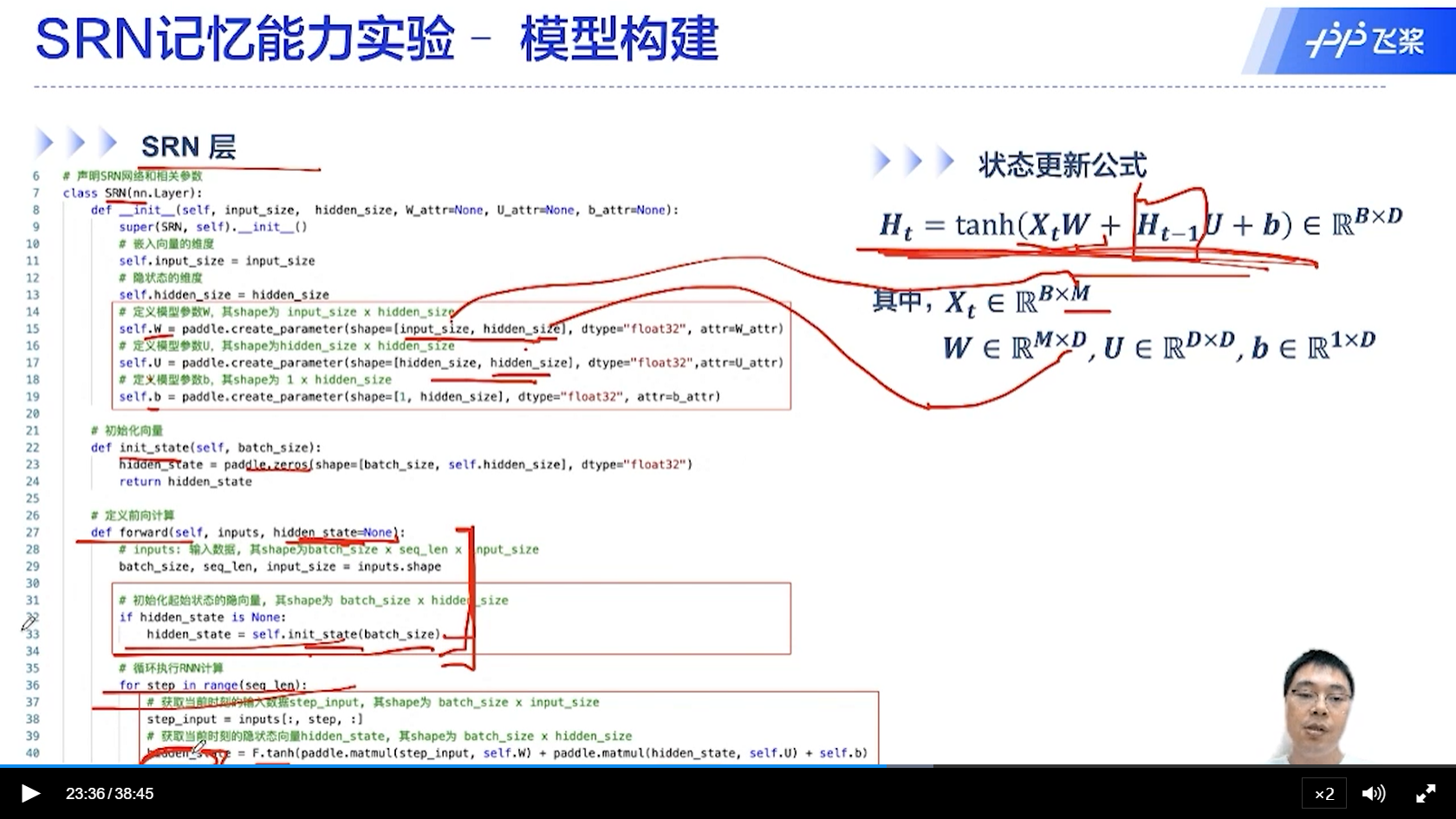
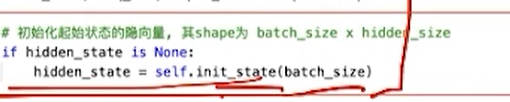
此处初始化H_0

不同的时间步,一步一步的往前传递
[√] 手动推导SRN前向计算

alec:
- 可以看出,对于SRN,不同的时间步,参数W和U,是一样的。这个就是权重共享。

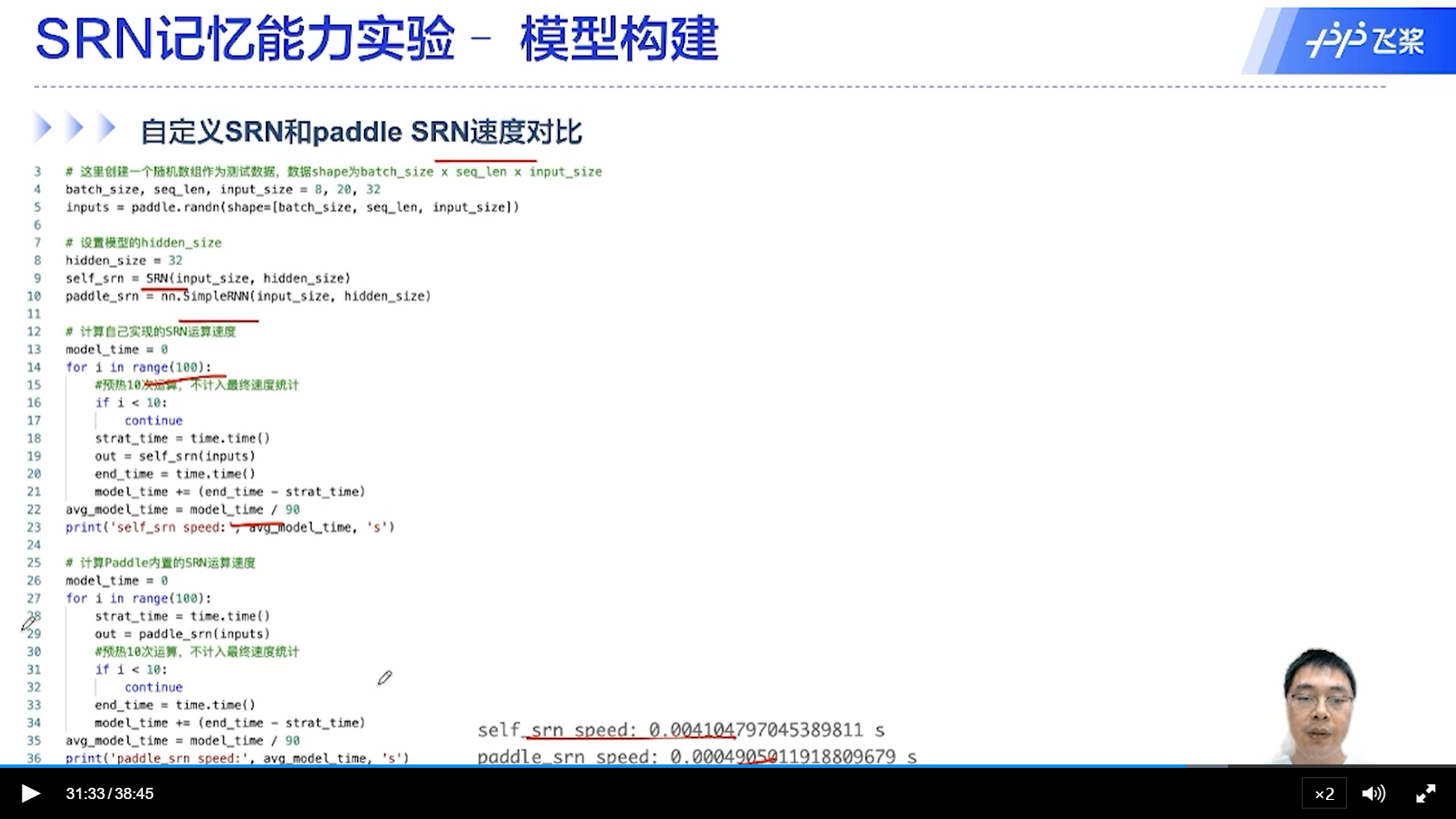
[√] 自定义SRN和Paddle SRN速度对比
[√] 线性层

线性层直接使用全连接实现。
[√] 模型汇总

SRN的构成:嵌入层 + SRN层 + 线性层
其中线性层用于将最终的状态转为预测的类别
本实验案例中,前两个数字都是0-9,因此最终的结果再0-18中,所以最终线性层输出中,一共预测19个分类。
[√] 多组训练

模型中的shape,长度指的是时间维度的长度
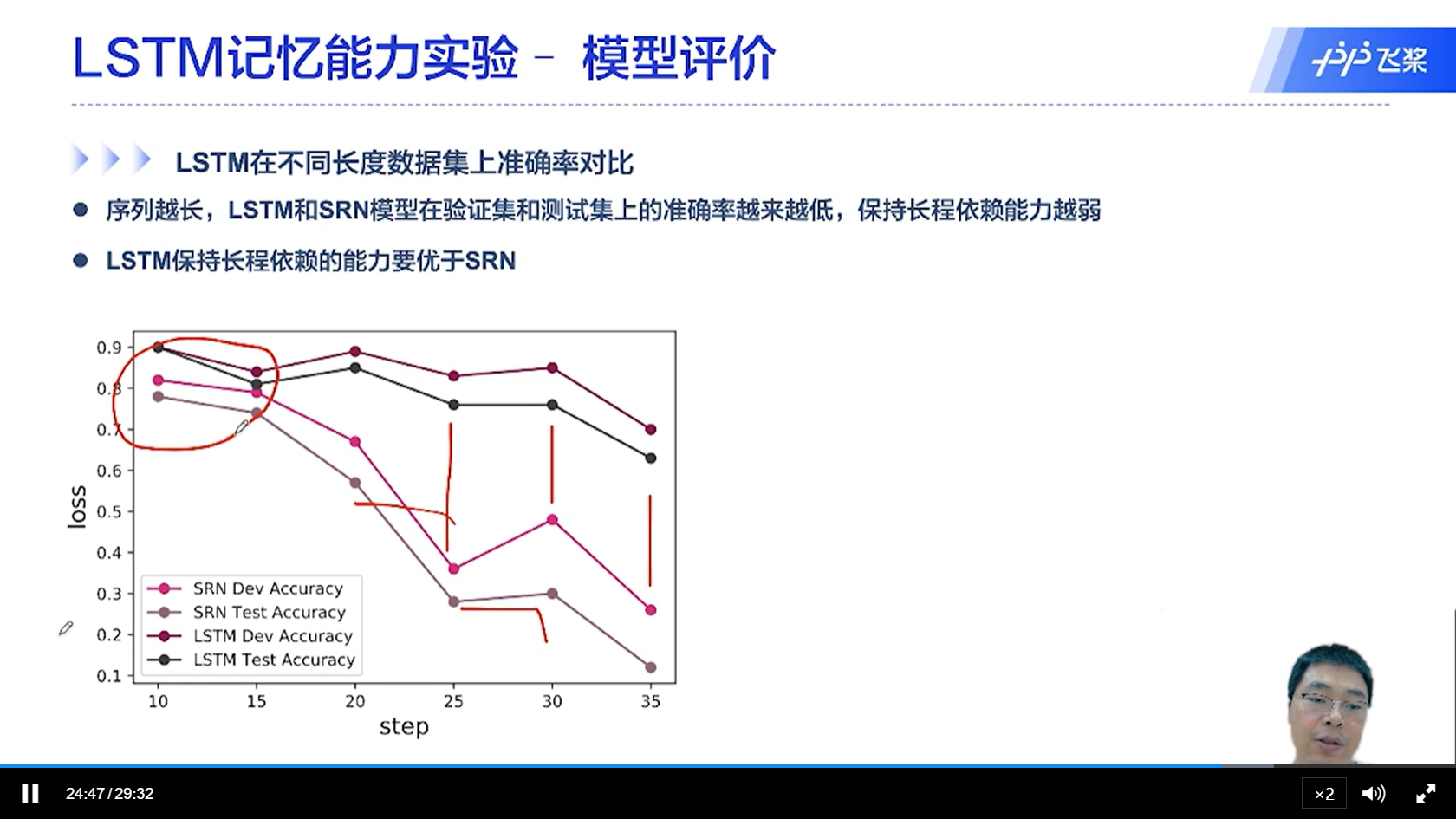
[√] SRN在不同长度数据集训练损失的变化
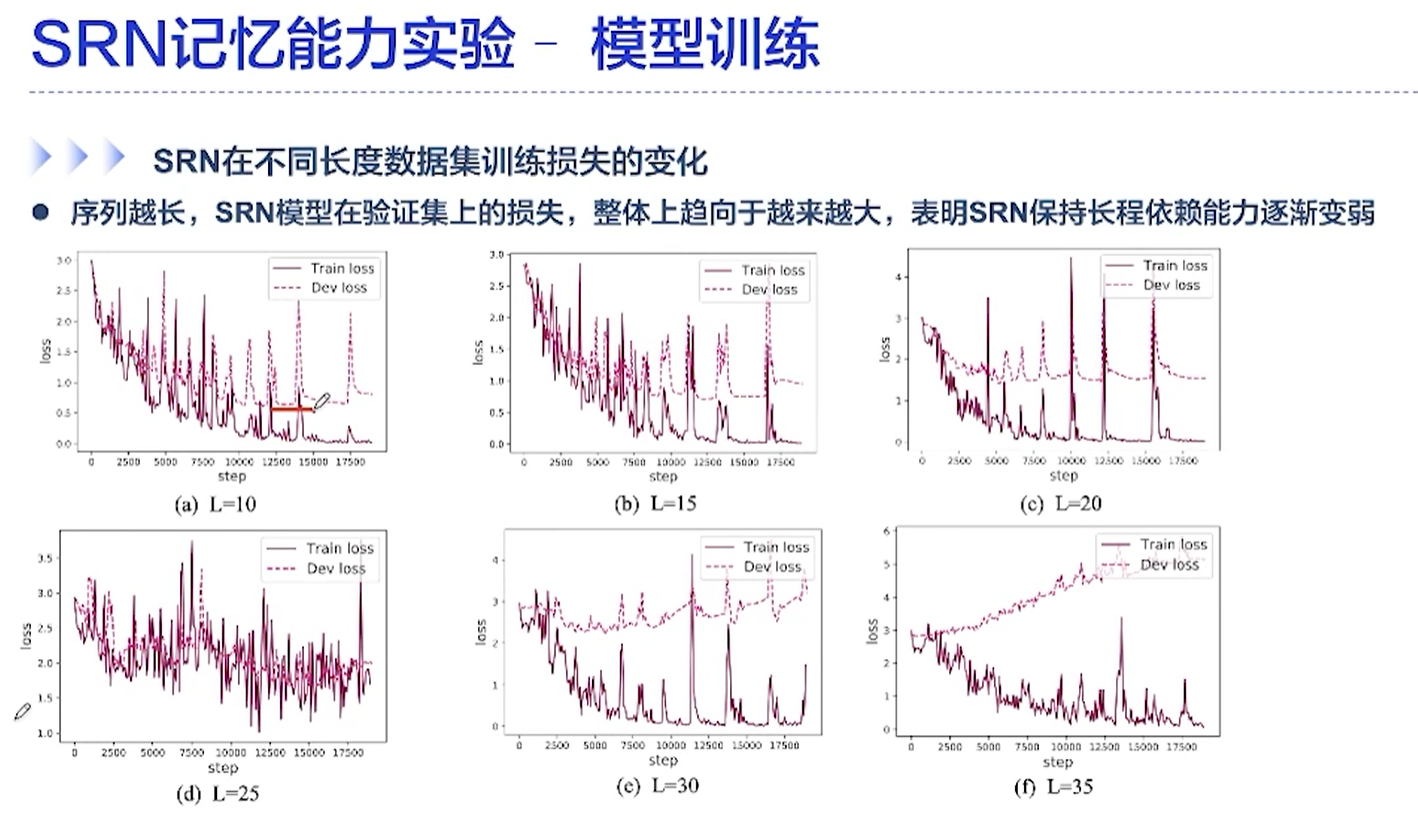
可以看出,长度越长,效果越差。网络的记忆能力越差,越来越记不住了。
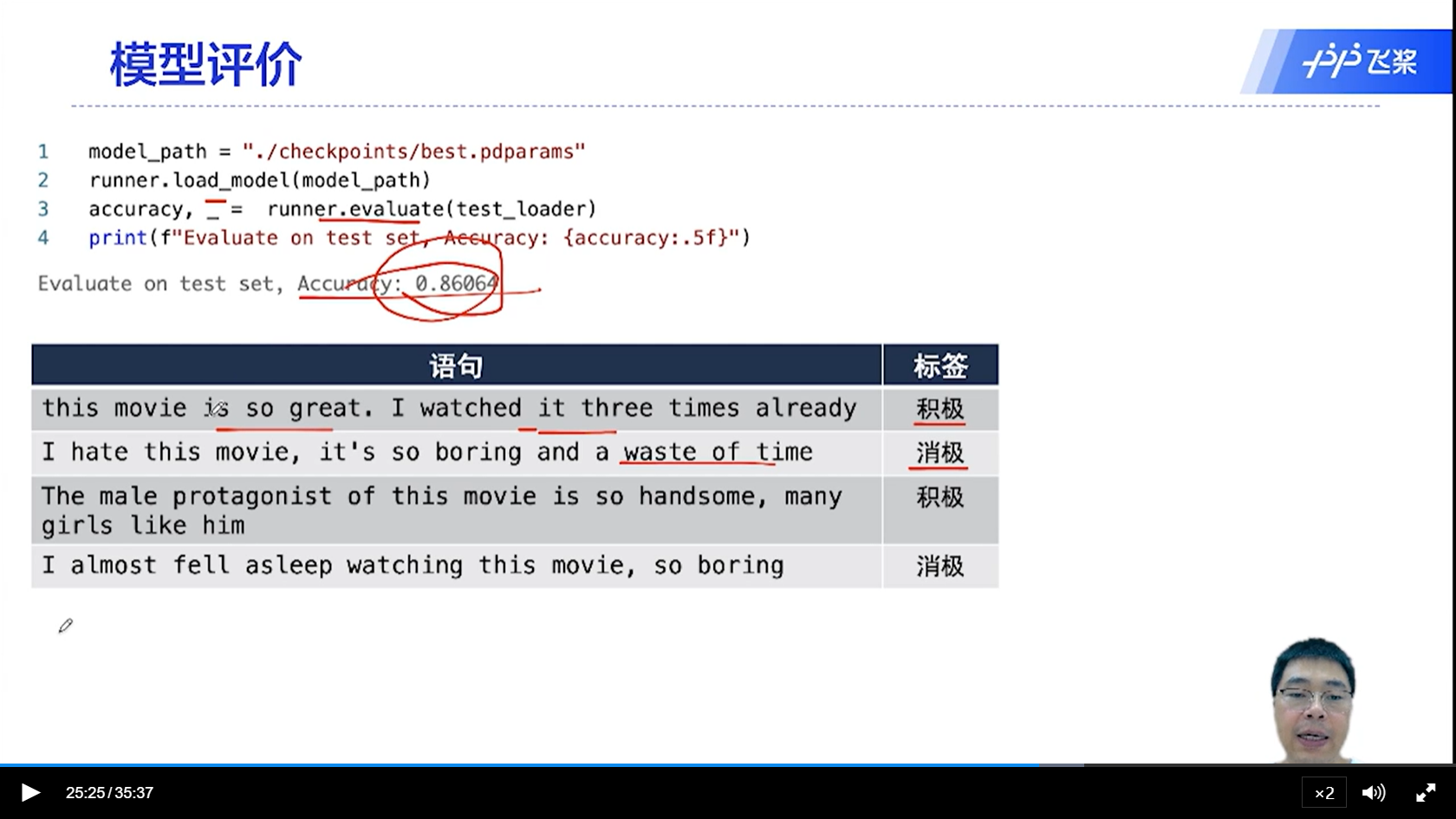
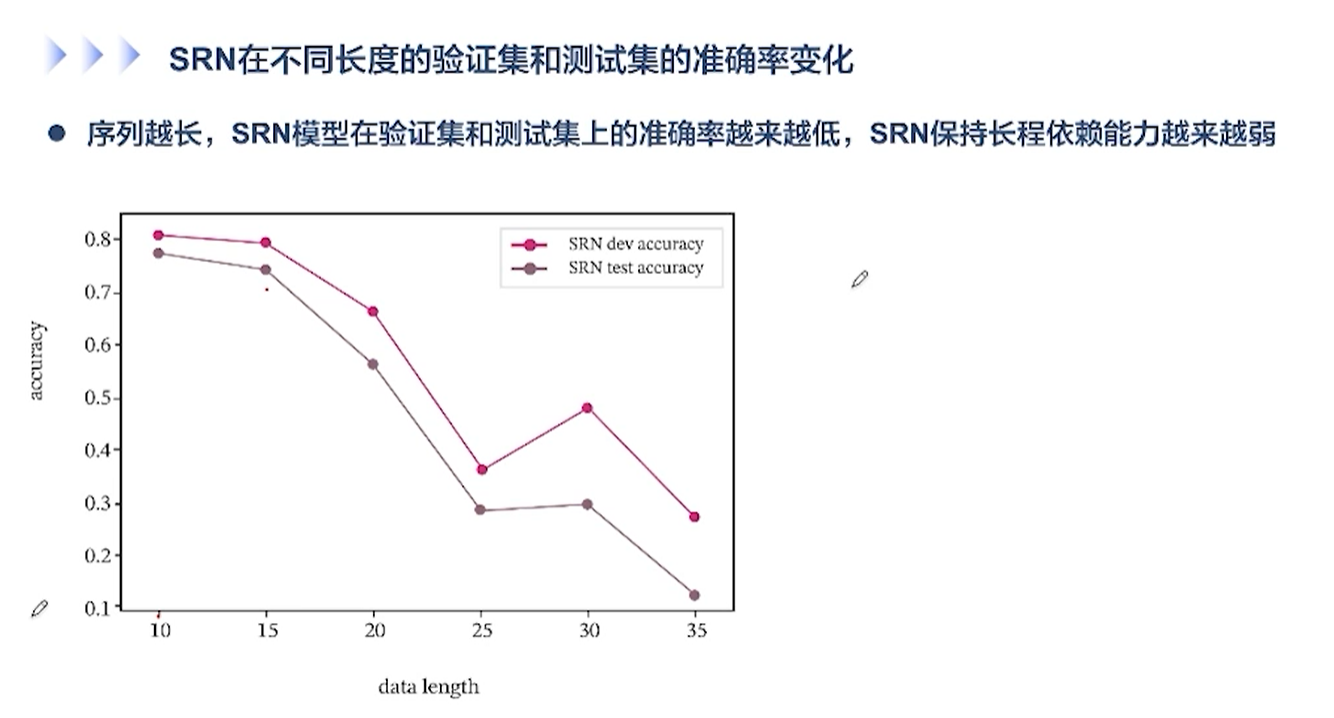
[√] 利用测试集对指定长度的模型评价

[√] 6.3 - SRN的记忆能力实验代码演示
alec:
- SRN层将最后时刻的隐状态作为整个序列的表示
- SRN中,嵌入层和SRN都是可以学习的
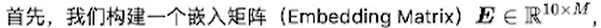
嵌入矩阵的维度,是10xM,意思是这个嵌入矩阵可以转换10个数字为M维的向量,10的意思是用于查表。通过第一个维度的索引来查表。
[√] 6.4 - SRN的梯度爆炸实验
alec:
模型优化目标通常为损失函数和正则化项的加权组合
[√] SRN梯度爆炸实验-实验说明
[√] SRN的主要问题
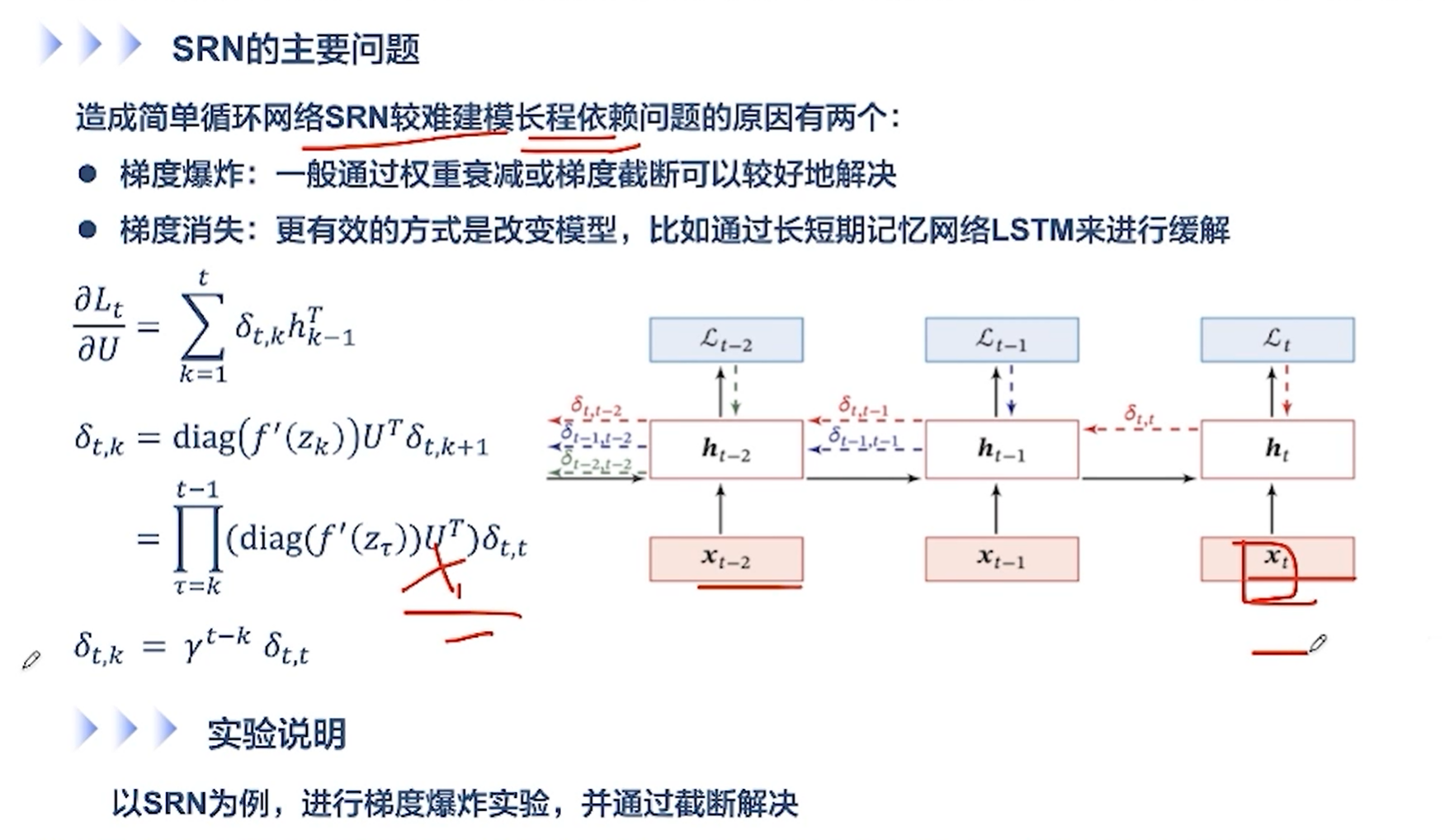
alec:
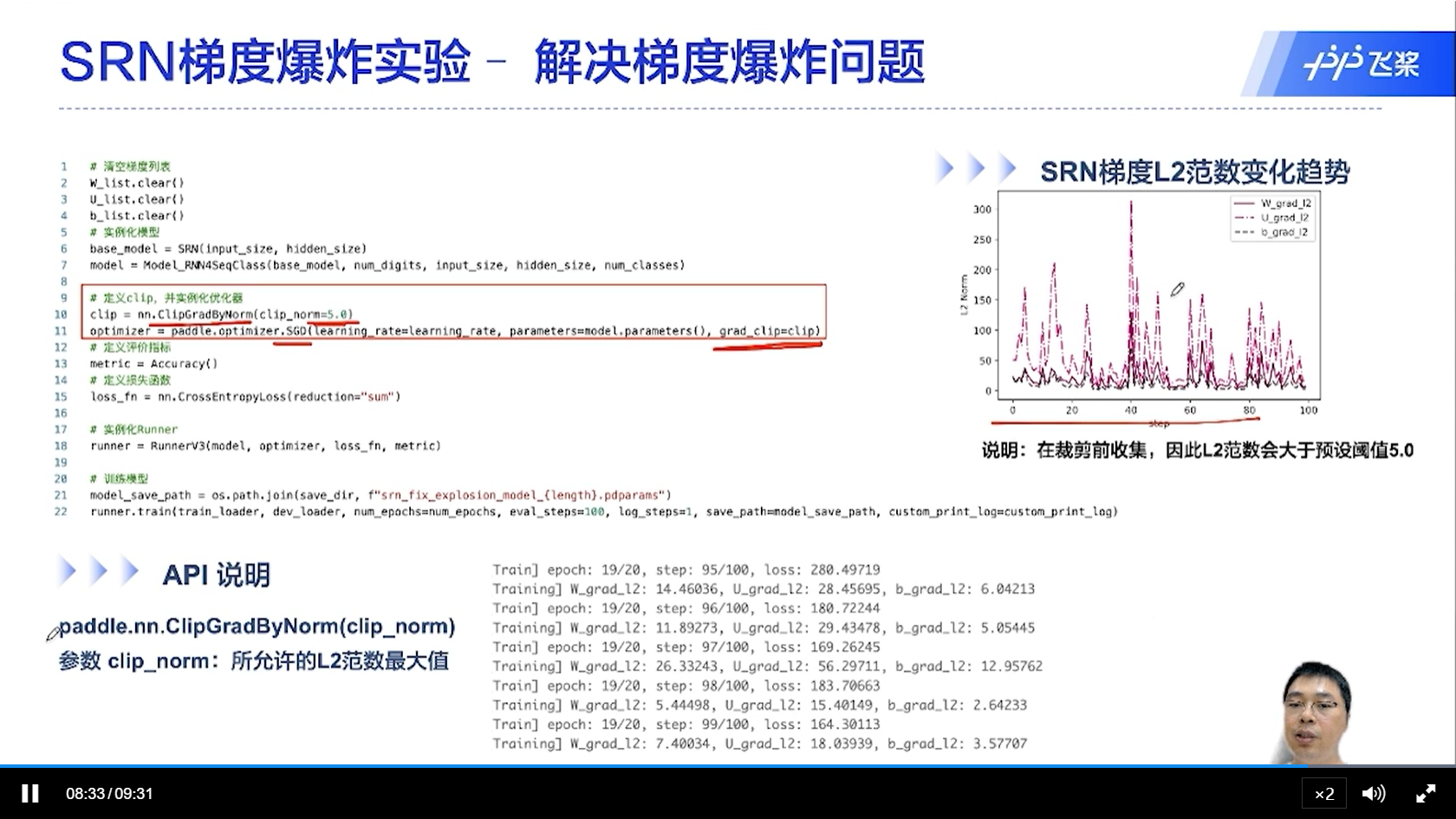
梯度爆炸相对来说容易解决,通过梯度截断的方式来解决
梯度消失问题,通过改变模型,比如通过LSTM模型来解决梯度消失问题
[√] SRN梯度爆炸实验-复现梯度爆炸实验

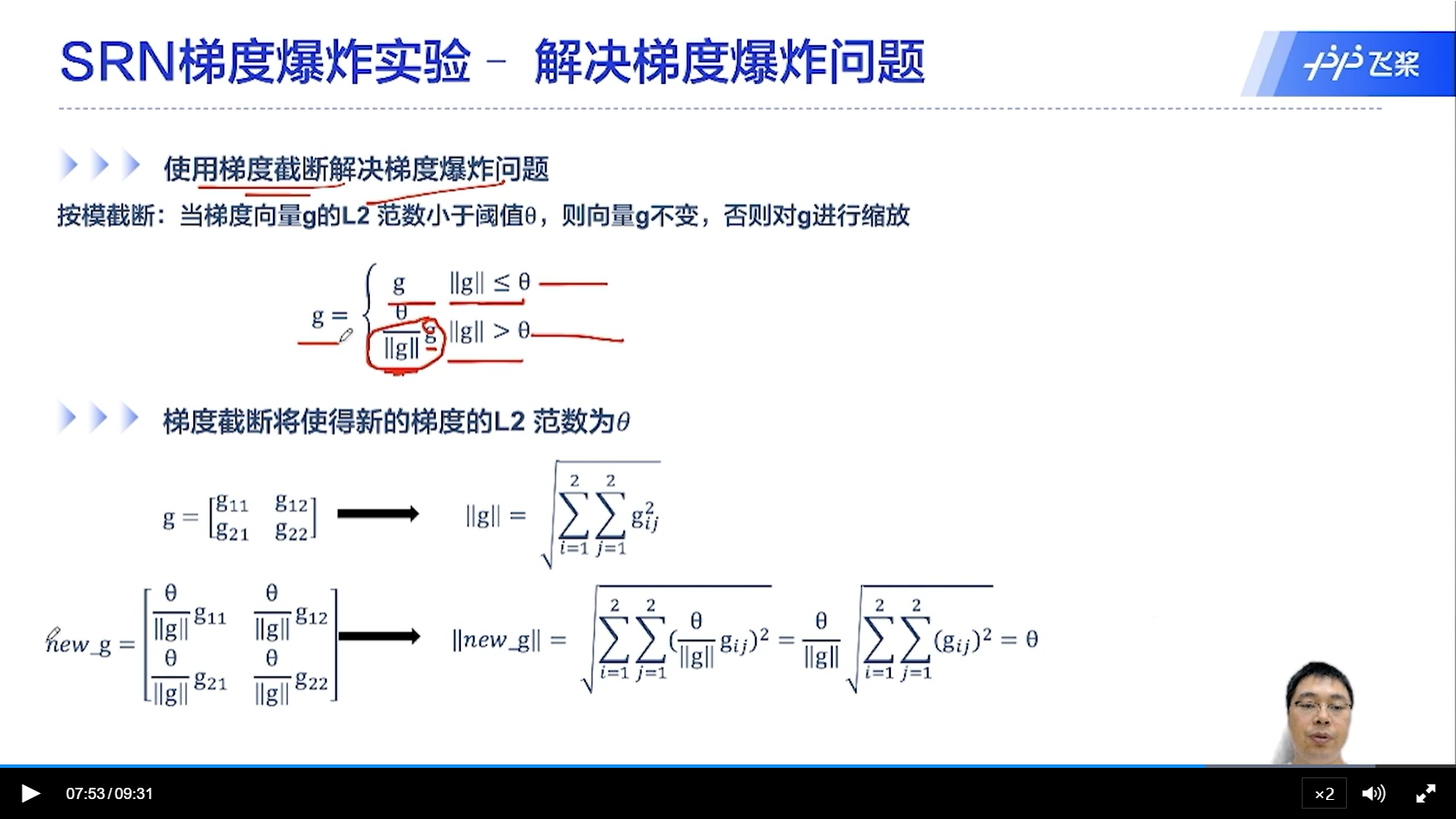
[√] SRN梯度爆炸实验-解决梯度爆炸问题
[√] 6.5 - LSTM的记忆能力实验
[√] 机器学习实践五要素

[√] LSTM记忆能力实验-实验说明

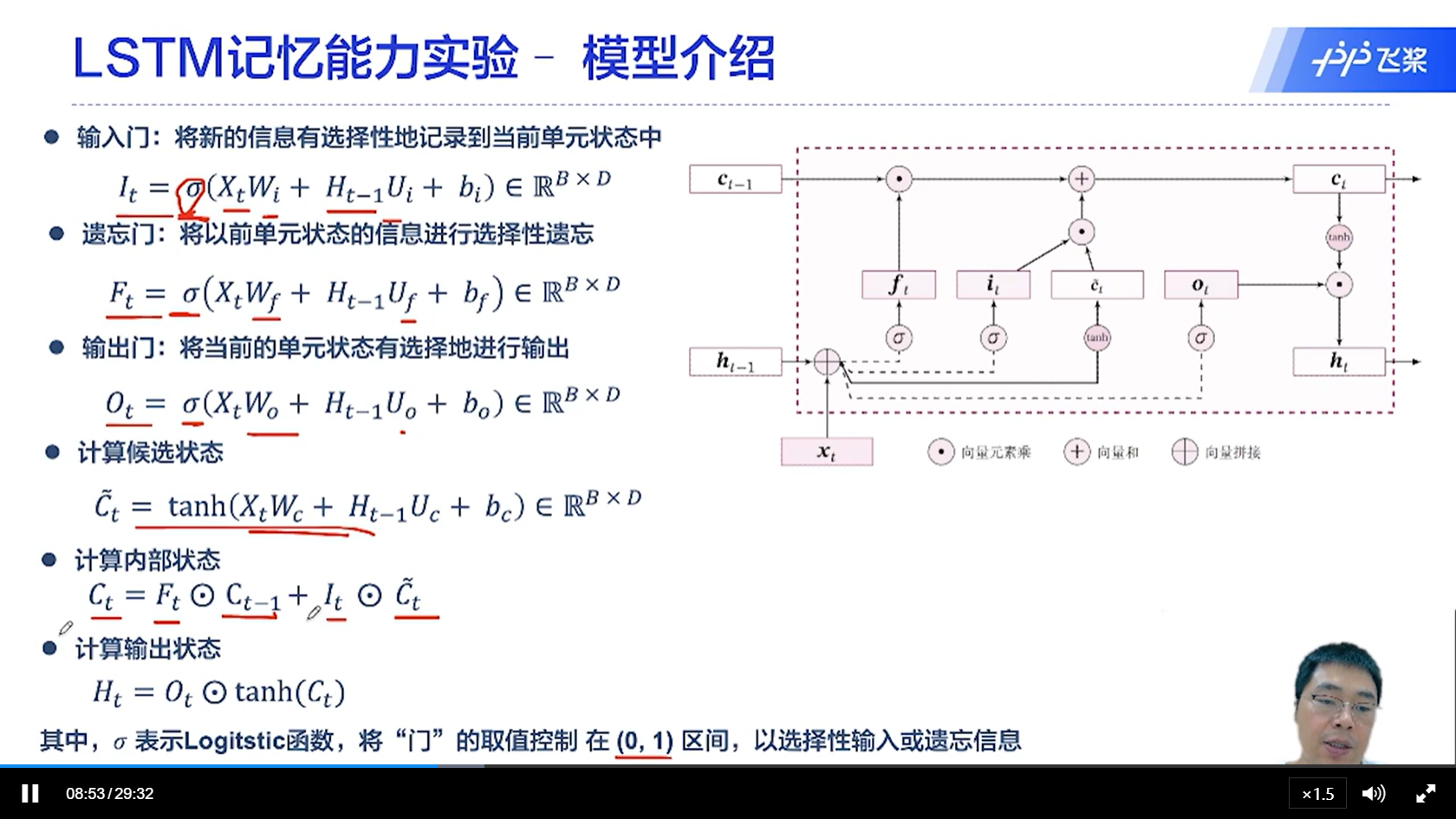
[√] LSTM记忆能力实验-模型介绍
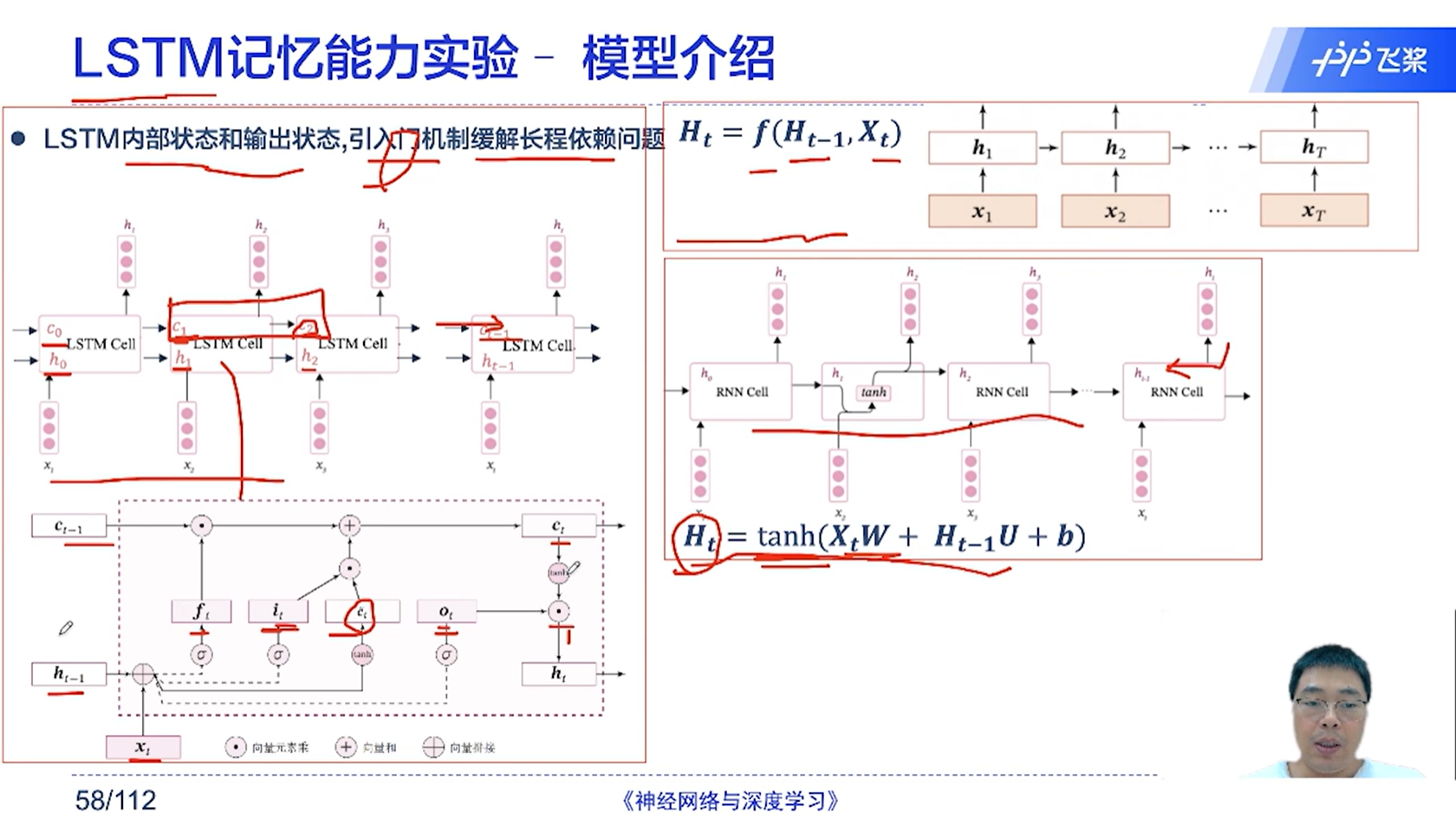
alec:
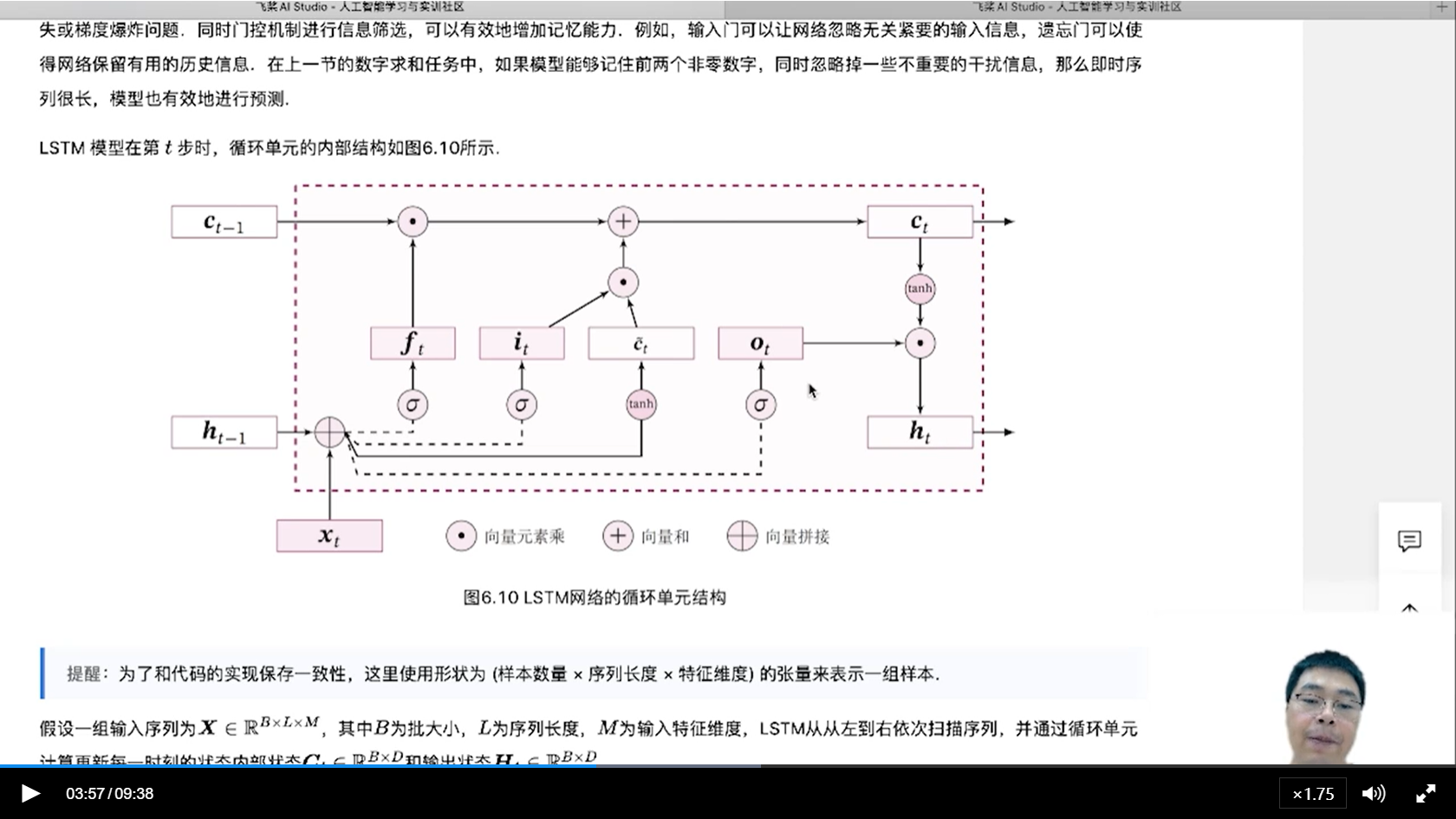
LSTM引入了内部状态C和输出状态H,同时引入了比较复杂的门控机制。
引入内部状态C是为了做序列上的记忆。
这样的好处是,一个状态用来做记忆,一个状态用来做输出。
一共有三个门控,分别是遗忘门、输入门、输出门
其中遗忘门是控制器前一个状态的C_t-1
输入门是用来控制新的tanh(x_t, h_t-1)
输出门空来控制c_t-1, h_t-1, x_t的混合计算之后的非线性输出的大小
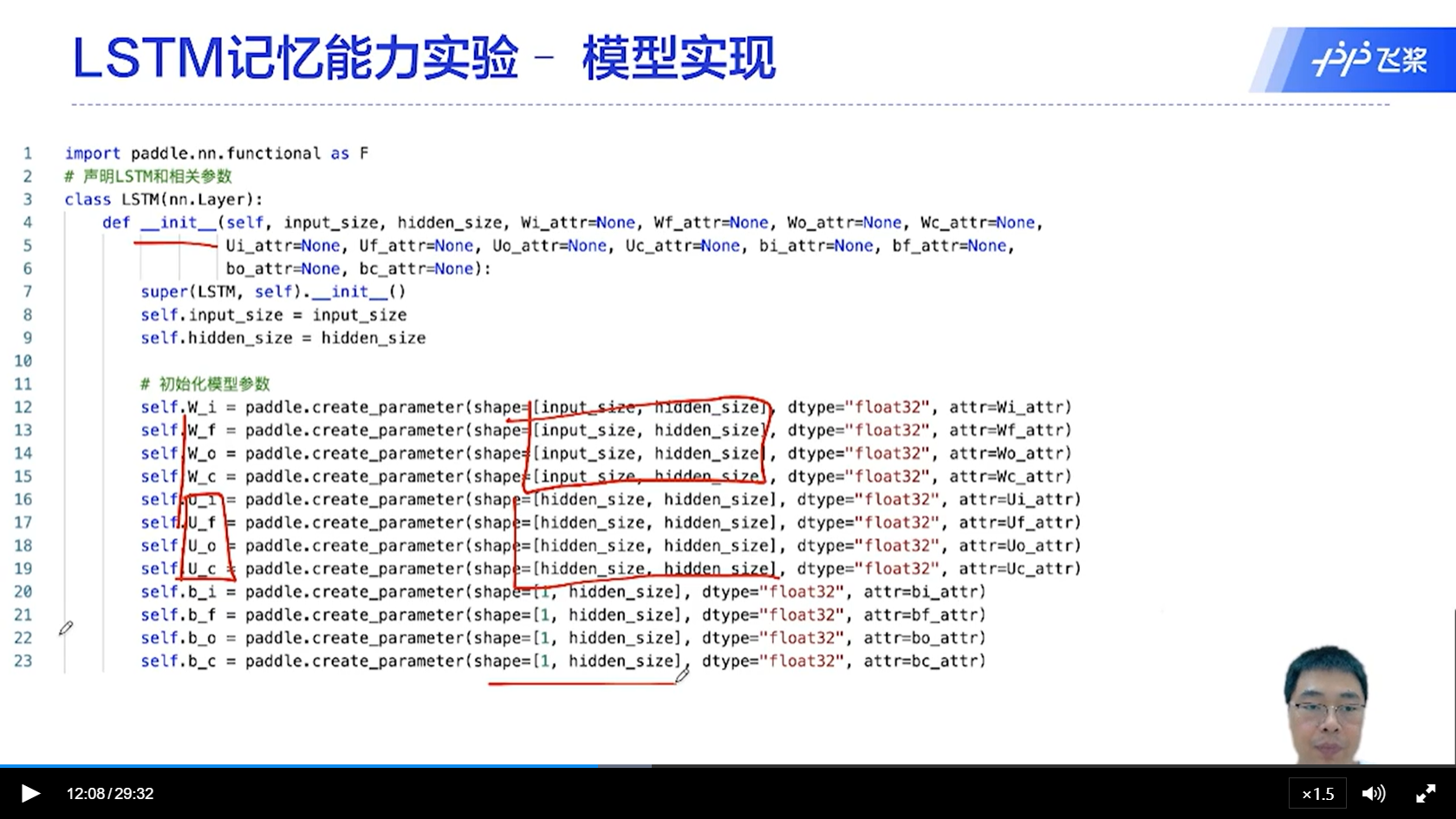
[√] LSTM记忆能力实验-模型实现

alec:
其中初始状态,可以是外面传进来,也可以是默认的初始化
[√] LSTM记忆能力实验-模型构建

其中,权重W、U、B在不同的时间步是权重共享的
[√] LSTM记忆能力实验-模型评价
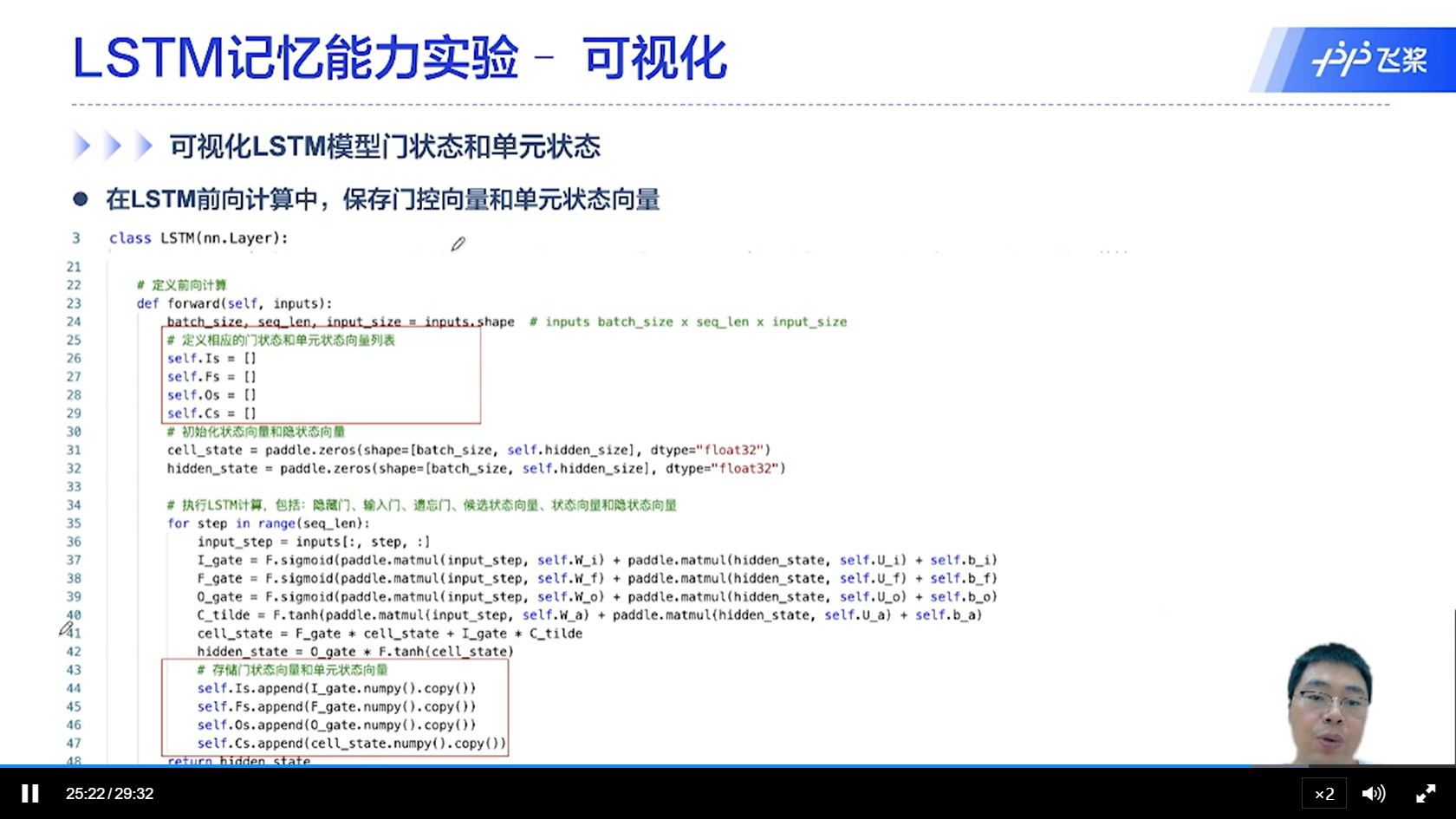
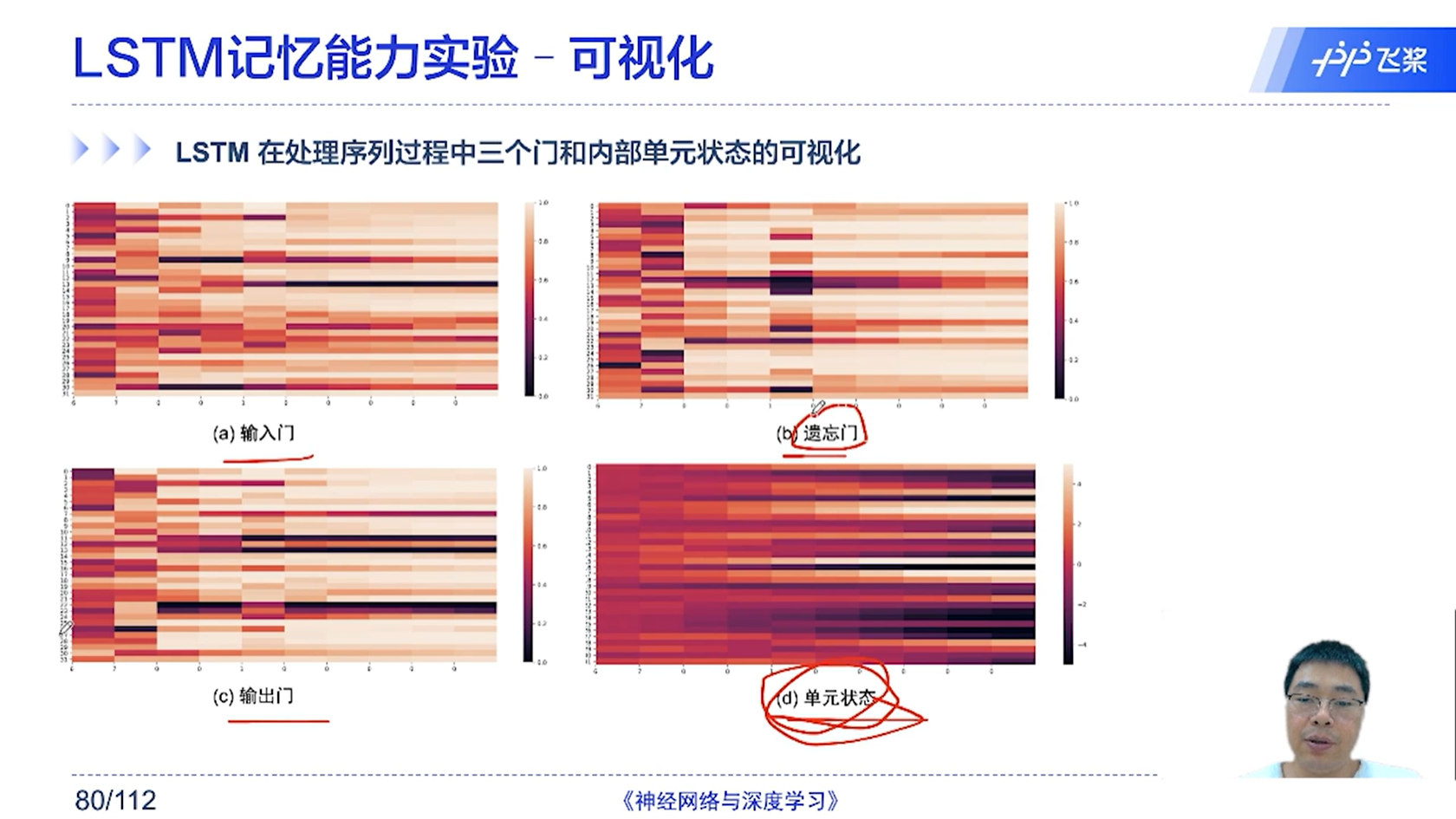
[√] LSTM记忆能力实验-可视化
[√] 6.6 - LSTM的记忆能力实验代码演示
alec:
- 三个门:
- 遗忘门、输入门、输出门
- 三个状态
- 输出状态、内部状态(记忆 )、候选状态
- 遗忘门控制t-1的内部状态、输入门控制候选状态、输出门控制当前的记忆状态
- alec: 每个时刻对应单元的内部记忆状态C_t和输出状态h_t其实是有关系,C是未激活和门控的内容,H是C经过激活和门控后的内容。将C作为记忆直接传给下一个单元用作信息参考,同时将C激活和门控之后,传给下一个单元。
- 个人理解:将未激活的C直接往后传,其实类似于残差。为了防止梯度消失问题,并且提供给深层更多的信息参考,因此通过这种类似于残差的直连边的方式给后面的层提供更多的信息。
[√] 6.7 - 双向LSTM完成文本分类任务
[√] 机器学习实践五要素

[√] 数据处理

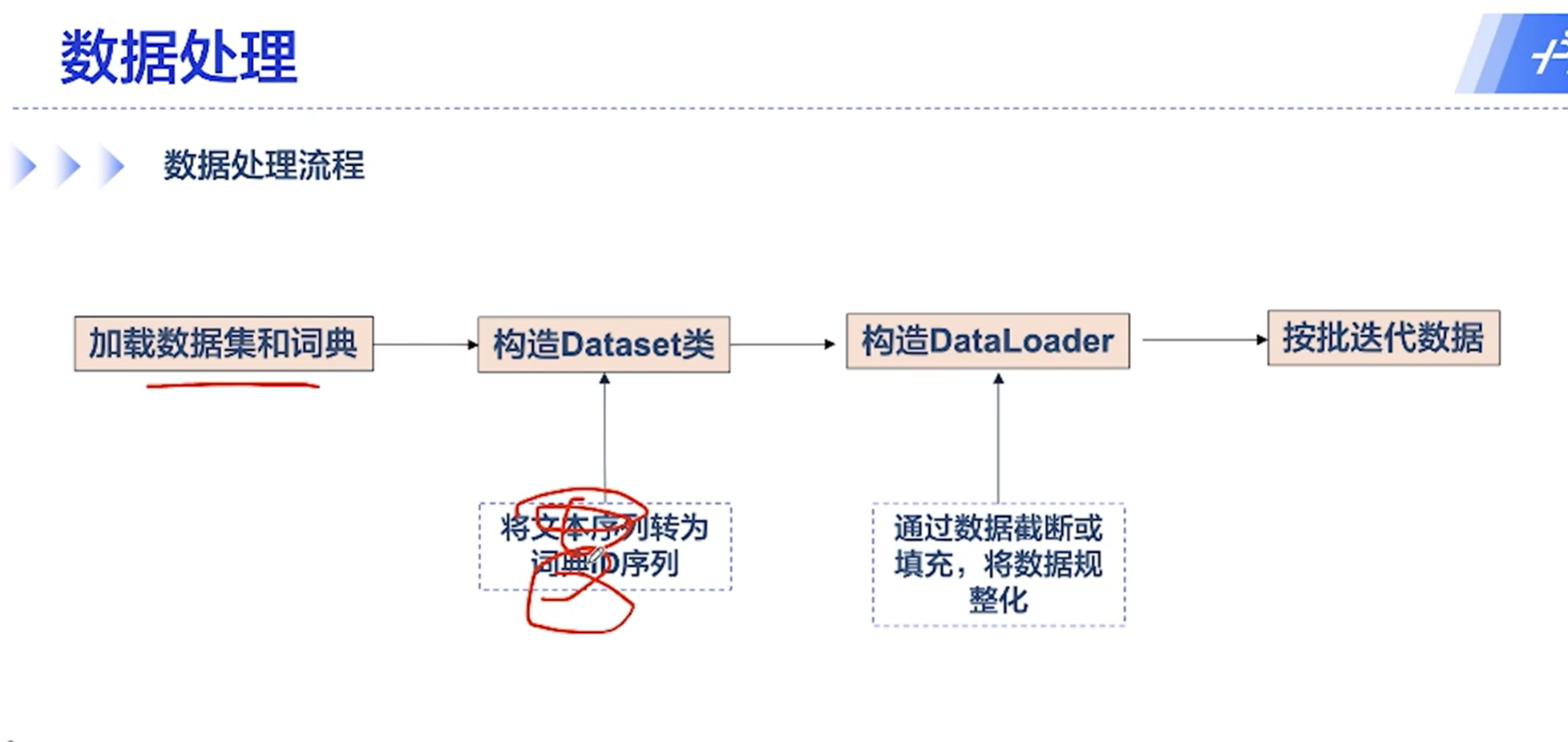


其中,词典中[PAD]和[UNK]分别是填充和unknown的意思,长度对齐的时候,会有[PAD],遇到词典中没有的、不认识的词,则表示为[UNK]

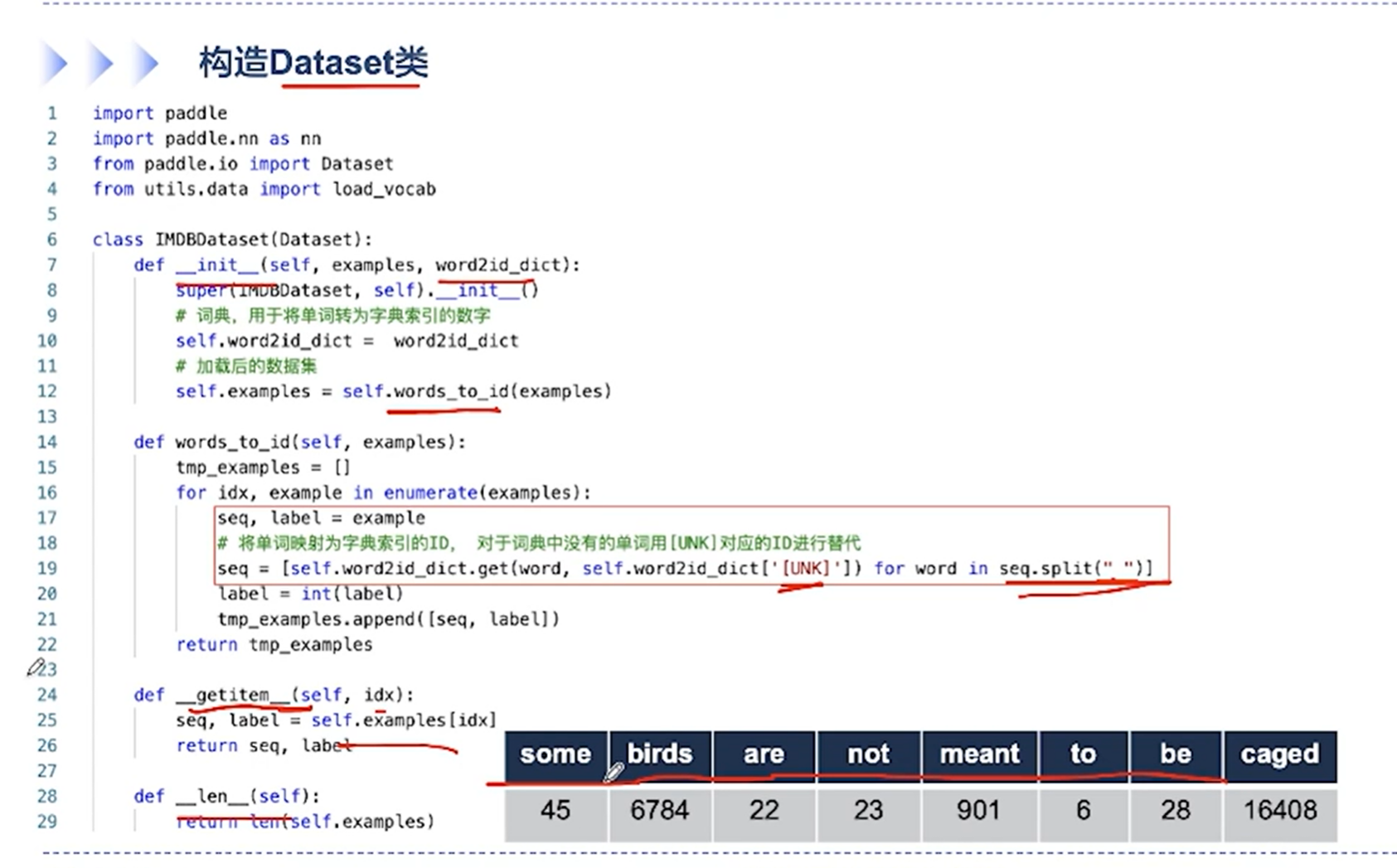
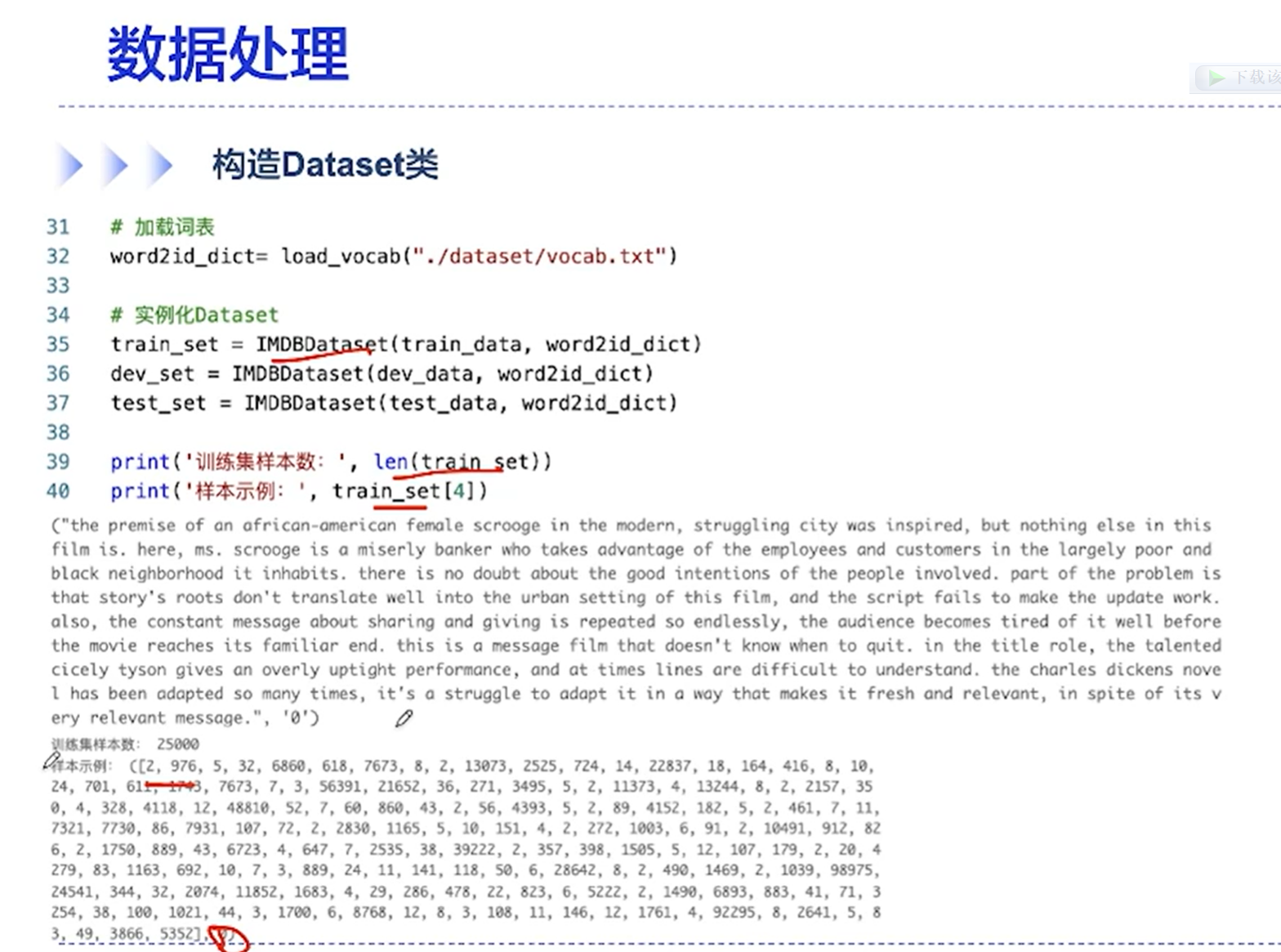
[√] 封装DataLoader
[√] 长度截断
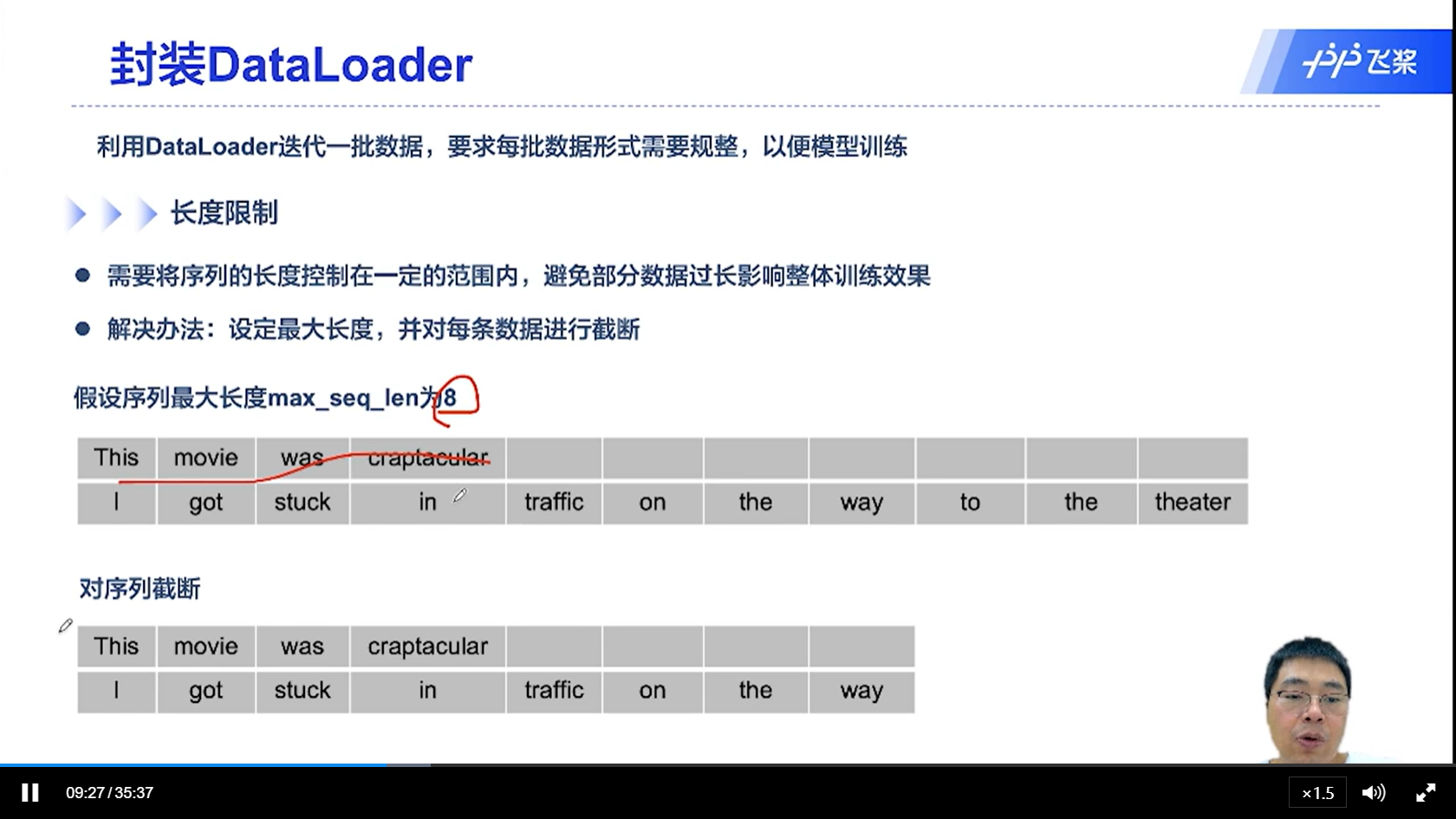
[√] 长度补齐

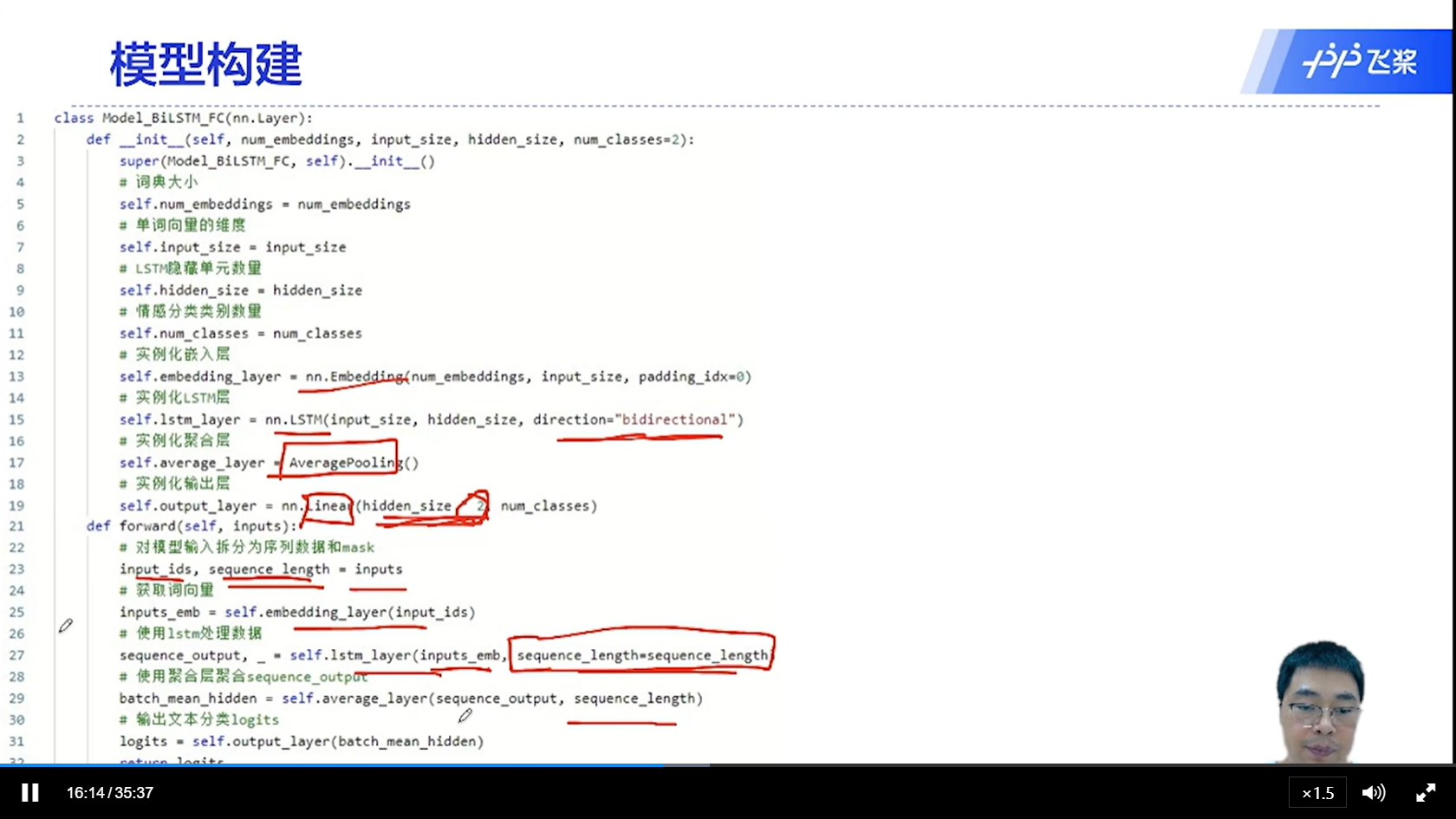
[√] 模型构建
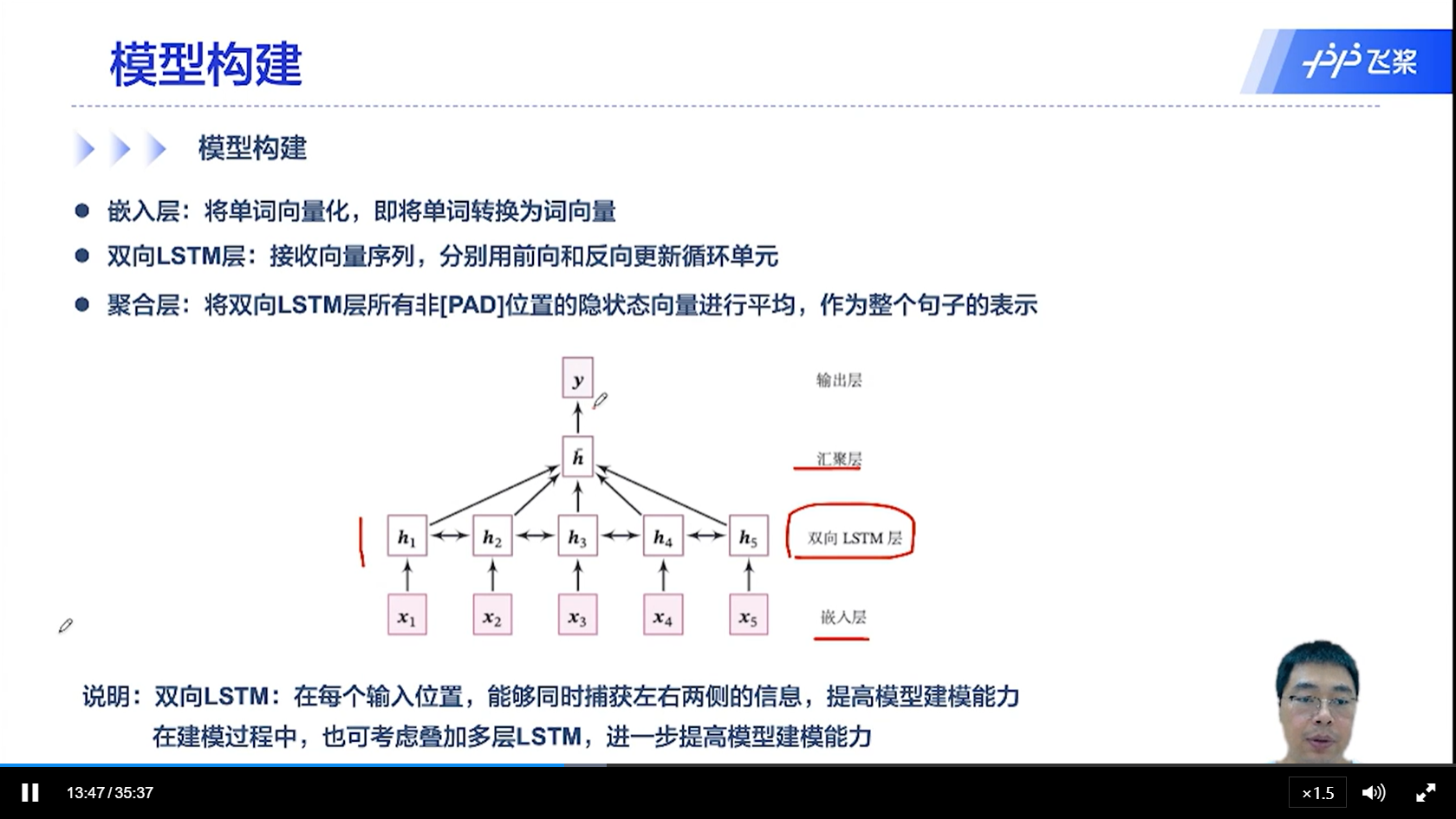
alec:
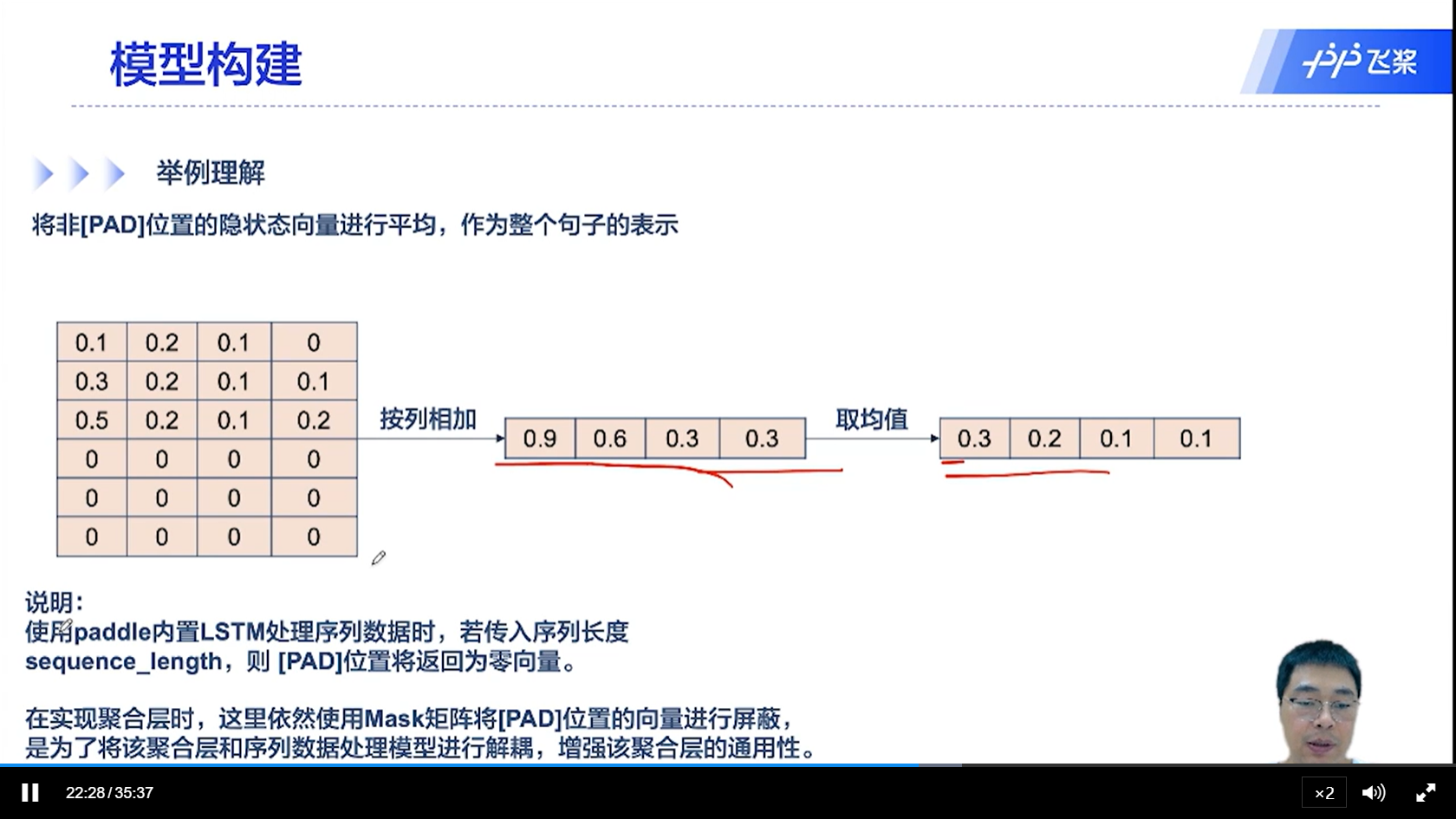
双向LSTM有一个汇聚层,将所有的时刻输出的隐状态向量汇聚(均值池化),然后传入到输出层进行分类

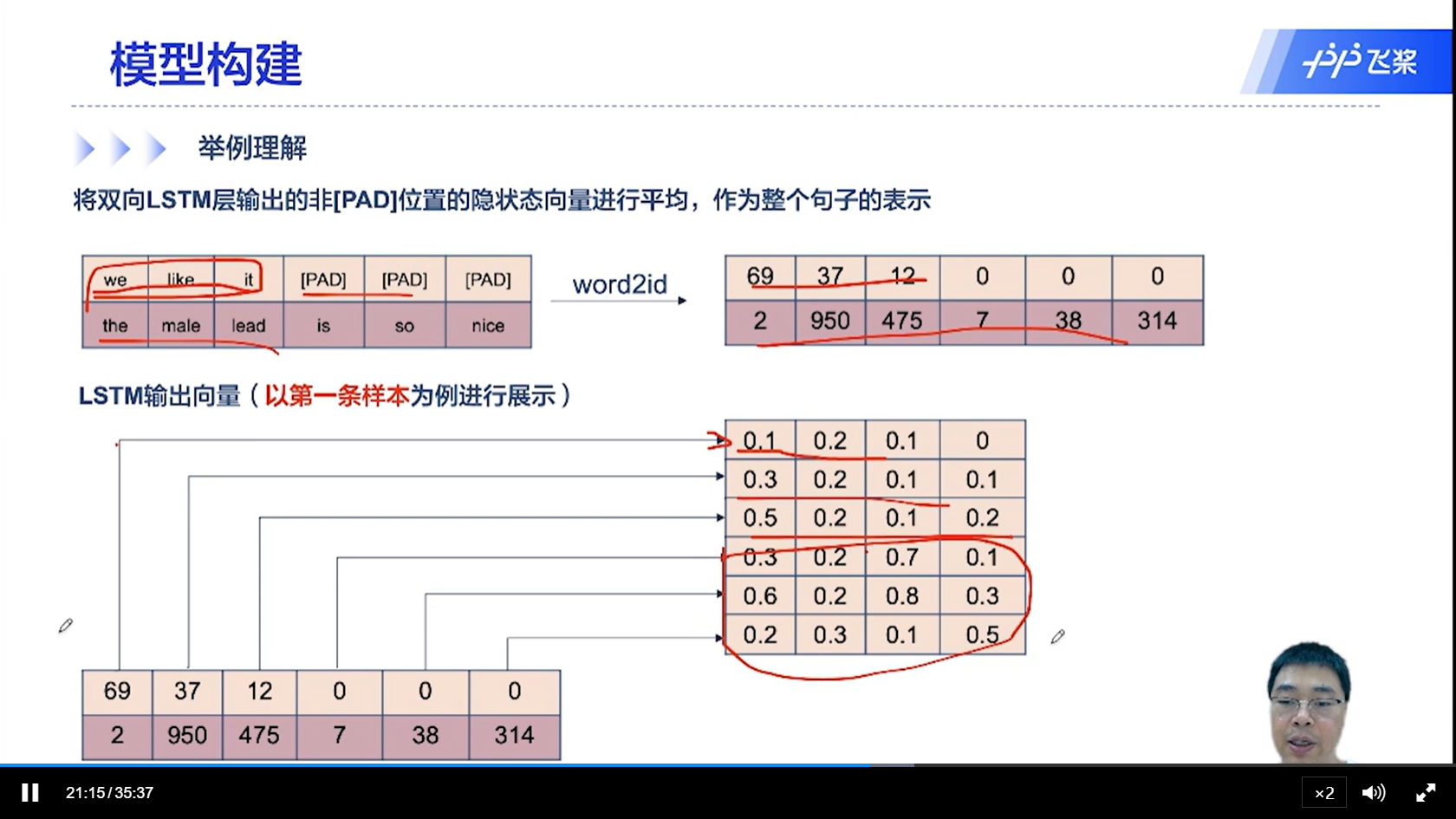
[√] 举例理解
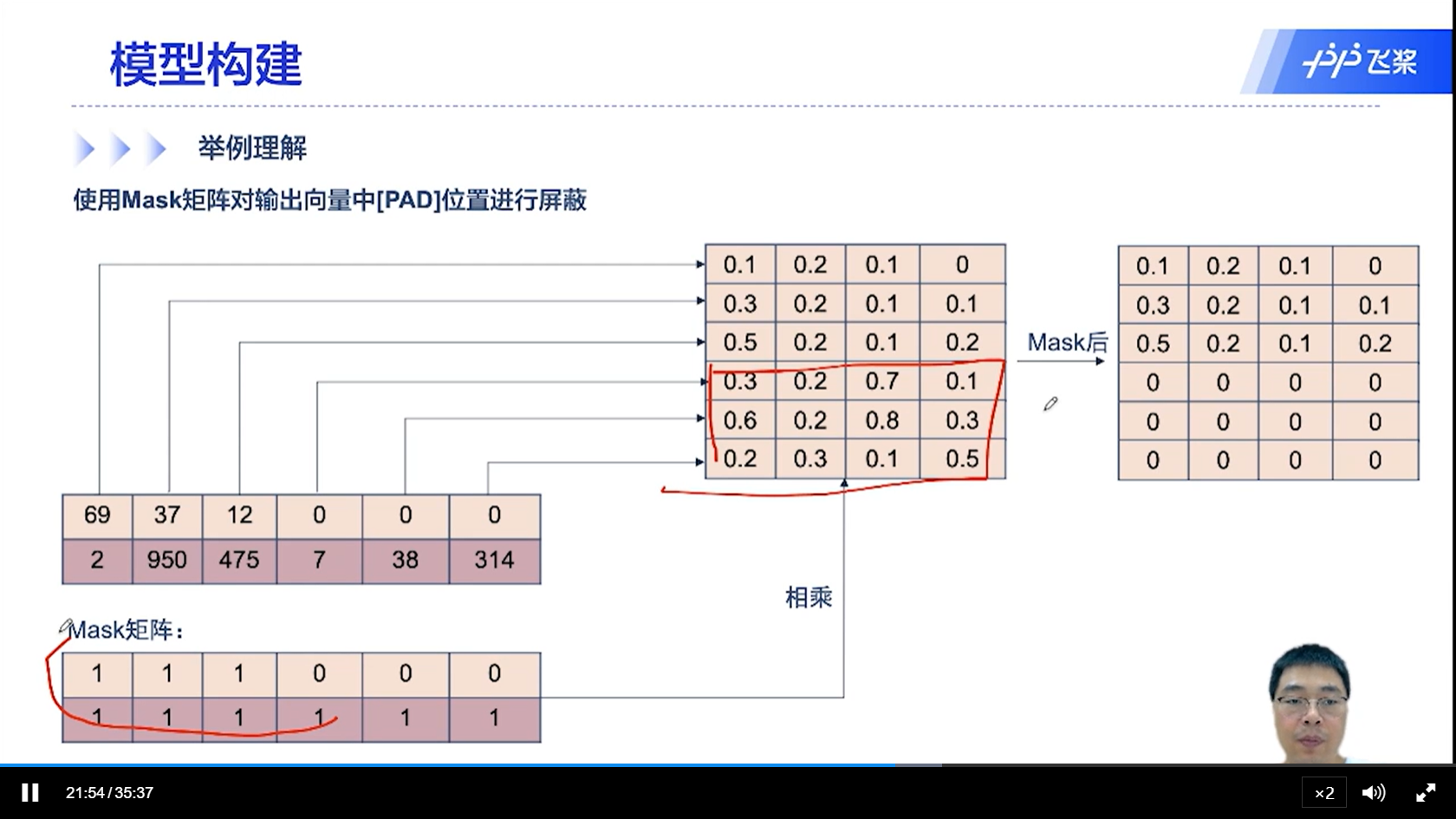
[√] 模型训练

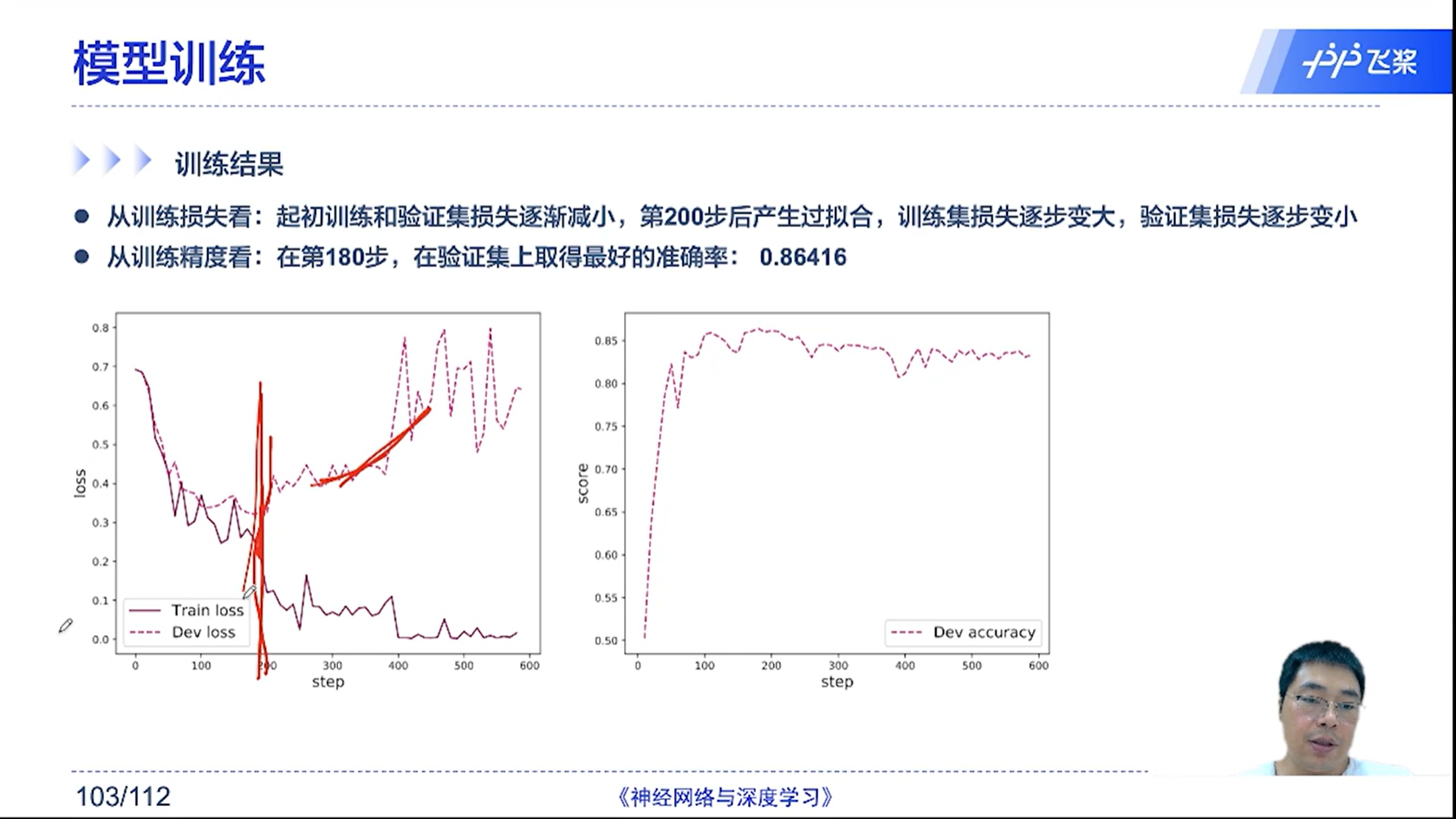
[√] 训练结果
[√] 模型评价