6 - 循环神经网络 - 实践:基于双向LSTM模型完成文本分类任务
本文最后更新于:3 个月前
[√] 6.4 实践:基于双向LSTM模型完成文本分类任务
电影评论可以蕴含丰富的情感:比如喜欢、讨厌、等等.情感分析(Sentiment Analysis)是为一个文本分类问题,即使用判定给定的一段文本信息表达的情感属于积极情绪,还是消极情绪.
本实践使用 IMDB 电影评论数据集,使用双向 LSTM 对电影评论进行情感分析.
[√] 6.4.1 数据处理
IMDB电影评论数据集是一份关于电影评论的经典二分类数据集.IMDB 按照评分的高低筛选出了积极评论和消极评论,如果评分 $\ge 7$,则认为是积极评论;如果评分 $\le4$,则认为是消极评论.数据集包含训练集和测试集数据,数量各为 25000 条,每条数据都是一段用户关于某个电影的真实评价,以及观众对这个电影的情感倾向,其目录结构如下所示
├── train/
├── neg # 消极数据
├── pos # 积极数据
├── unsup # 无标签数据
├── test/
├── neg # 消极数据
├── pos # 积极数据
在test/neg目录中任选一条电影评论数据,内容如下:
“Cover Girl” is a lacklustre WWII musical with absolutely nothing memorable about it, save for its signature song, “Long Ago and Far Away.”
LSTM 模型不能直接处理文本数据,需要先将文本中单词转为向量表示,称为词向量(Word Embedding).为了提高转换效率,通常会事先把文本的每个单词转换为数字 ID,再使用第节中介绍的方法进行向量转换.因此,需要准备一个词典(Vocabulary),将文本中的每个单词转换为它在词典中的序号 ID.同时还要设置一个特殊的词 [UNK],表示未知词.在处理文本时,如果碰到不在词表的词,一律按 [UNK] 处理.
alec:
- LSTM 模型不能直接处理文本数据,需要先将文本中单词转为向量表示,称为词向量(Word Embedding).
- 为了提高转换效率,通常会事先把文本的每个单词转换为数字 ID
- 需要准备一个词典(Vocabulary),将文本中的每个单词转换为它在词典中的序号 ID.同时还要设置一个特殊的词 [UNK],表示未知词.在处理文本时,如果碰到不在词表的词,一律按 [UNK] 处理.
[√] 6.4.1.1 数据加载
原始训练集和测试集数据分别25000条,本节将原始的测试集平均分为两份,分别作为验证集和测试集,存放于./dataset目录下。使用如下代码便可以将数据加载至内存:
1 | |
1 | |
从输出结果看,加载后的每条样本包含两部分内容:文本串和标签。
[√] 6.4.1.2 构造Dataset类
首先,我们构造IMDBDataset类用于数据管理,它继承自paddle.io.DataSet类。
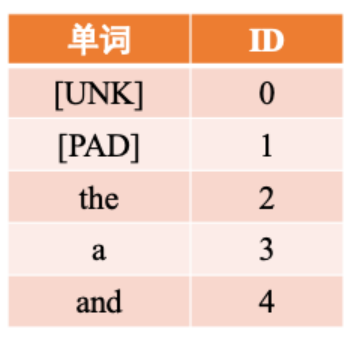
由于这里的输入是文本序列,需要先将其中的每个词转换为该词在词表中的序号 ID,然后根据词表ID查询这些词对应的词向量,该过程同第同6.1节中将数字向量化的操作,在获得词向量后会将其输入至模型进行后续计算。可以使用IMDBDataset类中的words_to_id方法实现这个功能。 具体而言,利用词表word2id_dict将序列中的每个词映射为对应的数字编号,便于进一步转为为词向量。当序列中的词没有包含在词表时,默认会将该词用[UNK]代替。words_to_id方法利用一个如图6.14所示的哈希表来进行转换。
代码实现如下:
1 | |
1 | |
alec:
- 神经网络模型通常需要同一批处理的数据的序列长度是相同的
- RNN可以处理变长的数据,因此注意这里不是把所有的数据都处理成同一长度,而是将同一批的数据处理成相同的长度
- 回调函数的意思是,写好了等着别的地方调用的工具函数
[√] 6.4.1.3 封装DataLoader
在构建 Dataset 类之后,我们构造对应的 DataLoader,用于批次数据的迭代.和前几章的 DataLoader 不同,这里的 DataLoader 需要引入下面两个功能:
- 长度限制:需要将序列的长度控制在一定的范围内,避免部分数据过长影响整体训练效果
- 长度补齐:神经网络模型通常需要同一批处理的数据的序列长度是相同的,然而在分批时通常会将不同长度序列放在同一批,因此需要对序列进行补齐处理.
对于长度限制,我们使用max_seq_len参数对于过长的文本进行截断.
对于长度补齐,我们先统计该批数据中序列的最大长度,并将短的序列填充一些没有特殊意义的占位符 [PAD],将长度补齐到该批次的最大长度,这样便能使得同一批次的数据变得规整.比如给定两个句子:
- 句子1: This movie was craptacular.
- 句子2: I got stuck in traffic on the way to the theater.
将上面的两个句子补齐,变为:
- 句子1: This movie was craptacular [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
- 句子2: I got stuck in traffic on the way to the theater
具体来讲,本节定义了一个collate_fn函数来做数据的截断和填充. 该函数可以作为回调函数传入 DataLoader,DataLoader 在返回一批数据之前,调用该函数去处理数据,并返回处理后的序列数据和对应标签。
另外,使用[PAD]占位符对短序列填充后,再进行文本分类任务时,默认无须使用[PAD]位置,因此需要使用变量seq_lens来表示序列中非[PAD]位置的真实长度。seq_lens可以在collate_fn函数处理批次数据时进行获取并返回。需要注意的是,由于RunnerV3类默认按照输入数据和标签两类信息获取数据,因此需要将序列数据和序列长度组成元组作为输入数据进行返回,以方便RunnerV3解析数据。
代码实现如下:
1 | |
下面我们自定义一批数据来测试一下collate_fn函数的功能,这里假定一下max_seq_len为5,然后定义序列长度分别为6和3的两条数据,传入collate_fn函数中。
1 | |
1 | |
可以看到,原始序列中长度为6的序列被截断为5,同时原始序列中长度为3的序列被填充到5,同时返回了非[PAD]的序列长度。
接下来,我们将collate_fn作为回调函数传入DataLoader中, 其在返回一批数据时,可以通过collate_fn函数处理该批次的数据。 这里需要注意的是,这里通过partial函数对collate_fn函数中的关键词参数进行设置,并返回一个新的函数对象作为collate_fn。
在使用DataLoader按批次迭代数据时,最后一批的数据样本数量可能不够设定的batch_size,可以通过参数drop_last来判断是否丢弃最后一个batch的数据。
alec:
- 在使用DataLoader按批次迭代数据时,最后一批的数据样本数量可能不够设定的batch_size,可以通过参数drop_last来判断是否丢弃最后一个batch的数据。
1 | |
1 | |
[√] 6.4.2 模型构建
本实践的整个模型结构如图6.15所示.
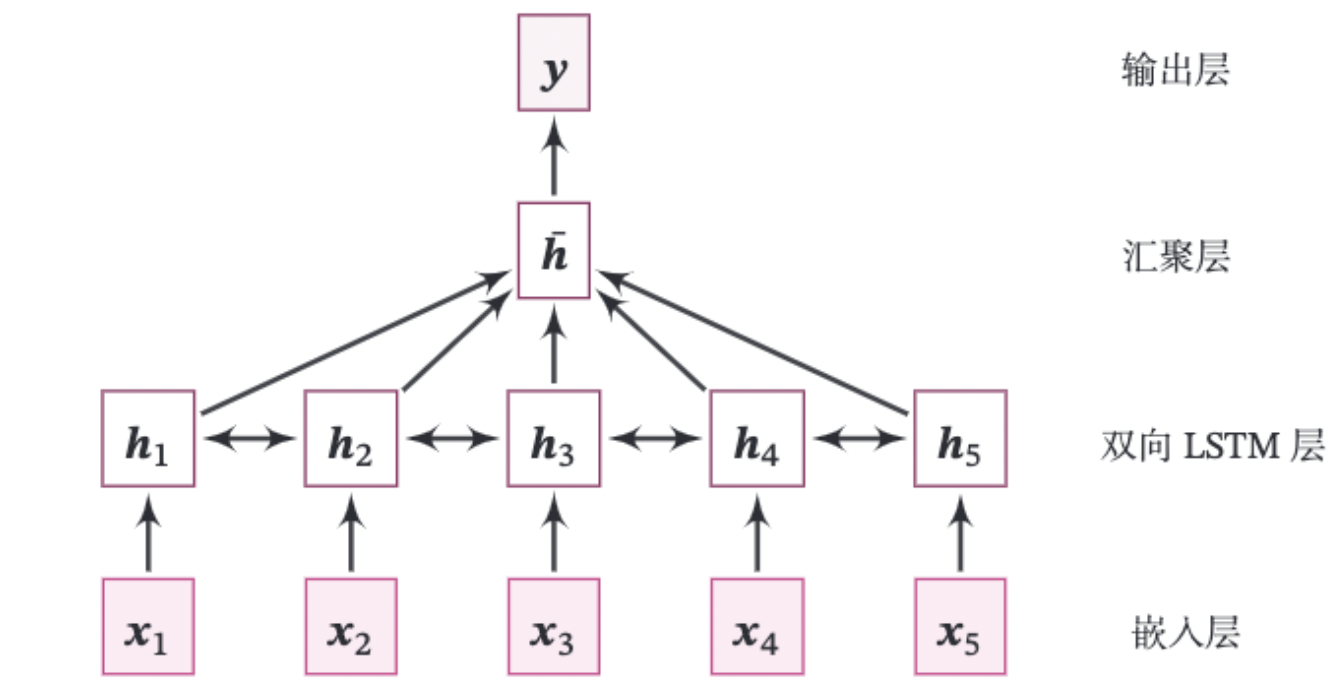
由如下几部分组成:
(1)嵌入层:将输入的数字序列进行向量化,即将每个数字映射为向量。这里直接使用飞桨API:paddle.nn.Embedding来完成。
class paddle.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, sparse=False, weight_attr=None, name=None)
该API有两个重要的参数:num_embeddings表示需要用到的Embedding的数量。embedding_dim表示嵌入向量的维度。
paddle.nn.Embedding会根据[num_embeddings, embedding_dim]自动构造一个二维嵌入矩阵。参数padding_idx是指用来补齐序列的占位符[PAD]对应的词表ID,那么在训练过程中遇到此ID时,其参数及对应的梯度将会以0进行填充。在实现中为了简单起见,我们通常会将[PAD]放在词表中的第一位,即对应的ID为0。
alec收获/总结:
- 辨析:嵌入层,是将输入的数字序列进行向量化。注意嵌入层这里,不是指的将单词转为数字,将单词转为数字这个步骤在嵌入层之前的数据处理阶段已经完成了。嵌入层,是将单个数字,通过一定的方法,转为M维的向量,方便神经网络运算。
(2)双向LSTM层:接收向量序列,分别用前向和反向更新循环单元。这里我们直接使用飞桨API:paddle.nn.LSTM来完成。只需要在定义LSTM时设置参数direction为bidirectional,便可以直接使用双向LSTM。
思考: 在实现双向LSTM时,因为需要进行序列补齐,在计算反向LSTM时,占位符[PAD]是否会对LSTM参数梯度的更新有影响。如果有的话,如何消除影响?
注:在调用paddle.nn.LSTM实现双向LSTM时,可以传入该批次数据的真实长度,paddle.nn.LSTM会根据真实序列长度处理数据,对占位符[PAD]进行掩蔽,[PAD]位置将返回零向量。
(3)聚合层:将双向LSTM层所有位置上的隐状态进行平均,作为整个句子的表示。
(4)输出层:输出层,输出分类的几率。这里可以直接调用paddle.nn.Linear来完成。
动手练习6.5:改进第6.3.1.1节中的LSTM算子,使其可以支持一个批次中包含不同长度的序列样本。
上面模型中的嵌入层、双向LSTM层和线性层都可以直接调用飞桨API来实现,这里我们只需要实现汇聚层算子。需要注意的是,虽然飞桨内置LSTM在传入批次数据的真实长度后,会对[PAD]位置返回零向量,但考虑到汇聚层与处理序列数据的模型进行解耦,因此在本节汇聚层的实现中,会对[PAD]位置进行掩码。
[√] 汇聚层算子
汇聚层算子将双向LSTM层所有位置上的隐状态进行平均,作为整个句子的表示。这里我们实现了AveragePooling算子进行隐状态的汇聚,首先利用序列长度向量生成掩码(Mask)矩阵,用于对文本序列中[PAD]位置的向量进行掩蔽,然后将该序列的向量进行相加后取均值。代码实现如下:
将上面各个模块汇总到一起,代码实现如下:
1 | |
1 | |
[√] 模型汇总
将上面的算子汇总,组合为最终的分类模型。代码实现如下:
alec收获/总结:
- num_embeddings是指的词典的大小
- num_classes是指的分类的数量
- 嵌入层的作用是,将输入的每个时间点上的一个数字,转为一个向量,这个向量可以更加充分的表达这个单词的信息。总体的过程是,输入一个单词,通过词典将单词转为一个数字,然后再嵌入层将这个数字转为一个向量。
1 | |
1 | |
1 | |
如上所示,嵌入层,将单词对应的5098这个数字,转为了一个长度input_size为256的向量,以更加充分的表达信息。
[√] 6.4.3 模型训练
本节将基于RunnerV3进行训练,首先指定模型训练的超参,然后设定模型、优化器、损失函数和评估指标,其中损失函数使用paddle.nn.CrossEntropyLoss,该损失函数内部会对预测结果使用softmax进行计算,数字预测模型输出层的输出logits不需要使用softmax进行归一化,定义完Runner的相关组件后,便可以进行模型训练。代码实现如下。
1 | |
1 | |
绘制训练过程中在训练集和验证集上的损失图像和在验证集上的准确率图像:
1 | |
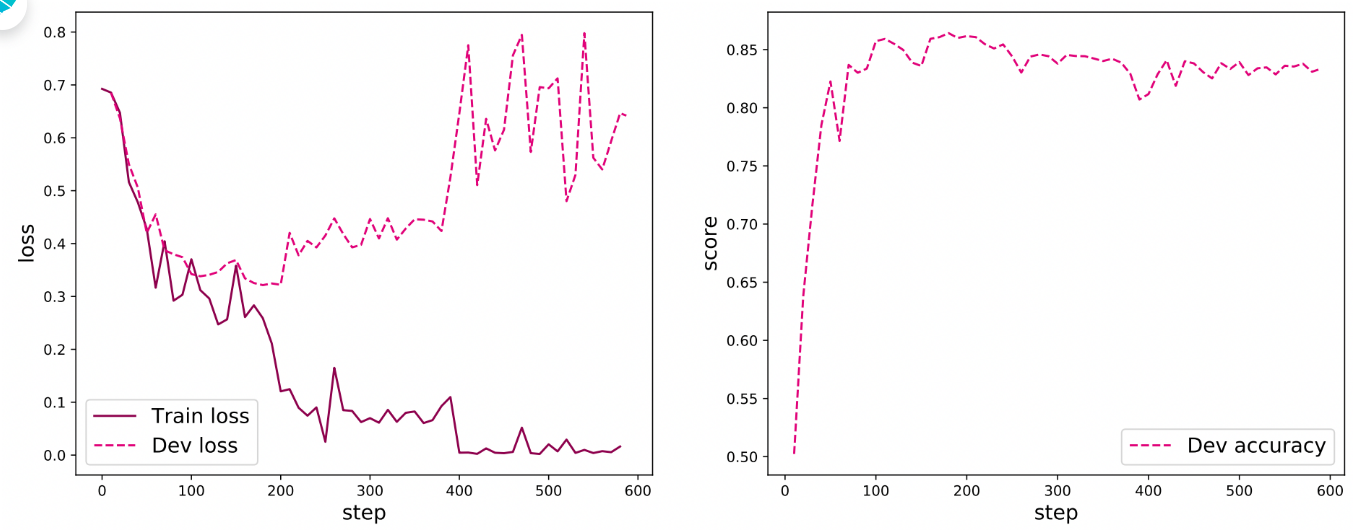
图6.16 展示了文本分类模型在训练过程中的损失曲线和在验证集上的准确率曲线,其中在损失图像中,实线表示训练集上的损失变化,虚线表示验证集上的损失变化. 可以看到,随着训练过程的进行,训练集的损失不断下降, 验证集上的损失在大概200步后开始上升,这是因为在训练过程中发生了过拟合,可以选择保存在训练过程中在验证集上效果最好的模型来解决这个问题. 从准确率曲线上可以看到,首先在验证集上的准确率大幅度上升,然后大概200步后准确率不再上升,并且由于过拟合的因素,在验证集上的准确率稍微降低。
[√] 6.4.4 模型评价
加载训练过程中效果最好的模型,然后使用测试集进行测试。
1 | |
1 | |
[√] 6.4.5 模型预测
给定任意的一句话,使用训练好的模型进行预测,判断这句话中所蕴含的情感极性。
1 | |
1 | |
[√] 6.5 拓展实验
[√] 6.6.1 使用Paddle内置的单向LSTM进行文本分类实验
首先,修改模型定义,将nn.LSTM中的direction设置为forward以使用单向LSTM模型,同时设置线性层的shape为[hidden_size, num_classes]。
1 | |
接下来,基于Paddle的单向模型开始进行训练,代码实现如下:
1 | |
基于Paddle的单向LSTM进行模型评价,代码实现如下:
1 | |
[√] 6.6.2 使用Paddle内置的单向LSTM进行文本分类实验
由于之前实现的LSTM默认只返回最后时刻的隐状态,然而本实验中需要用到所有时刻的隐状态向量,因此需要对自己实现的LSTM进行修改,使其返回序列向量,代码实现如下:
1 | |
接下来,修改Model_BiLSTM_FC模型,将nn.LSTM换为自己实现的LSTM模型,代码实现如下:
1 | |
1 | |
基于Paddle的单向LSTM进行模型评价,代码实现如下:
1 | |
[√] 6.6 小结
本章通过实践来加深对循环神经网络的基本概念、网络结构和长程依赖问题问题的理解.我们构建一个数字求和任务,并动手实现了 SRN 和 LSTM 模型,对比它们在数字求和任务上的记忆能力.在实践部分,我们利用双向 LSTM 模型来进行文本分类任务:IMDB 电影评论情感分析,并了解如何通过嵌入层将文本数据转换为向量表示.