032 - 文章阅读笔记:【图像超分辨率重建】——SwinIR论文精读笔记 - CSDN - Zency_SUN
本文最后更新于:3 个月前
转载自:
【√】【图像超分辨率重建】——SwinIR论文精读笔记 - CSDN - Zency_SUN
于 2022-12-29 11:53:56 发布
2021-SwinIR: Image Restoration Using Swin Transformer (SwinIR)
[√] 基本信息
作者: Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, Radu Timofte
期刊: ICCV
引用: 123
摘要: 图像恢复是一个长期存在的低级视觉问题,旨在从低质量图像(例如,缩小、噪声和压缩图像)中恢复高质量图像。虽然最先进的图像恢复方法是基于卷积神经网络,但很少有人尝试使用在高级视觉任务上表现出令人印象深刻的性能的 Transformers。在本文中,我们提出了一种基于 Swin Transformer 的用于图像恢复的强基线模型 SwinIR。
SwinIR由三部分组成:浅层特征提取、深层特征提取和高质量图像重建。特别地,深度特征提取模块由几个残差 Swin Transformer 块 (RSTB) 组成,每个残差块都有几个 Swin Transformer 层和一个残差连接。我们对三个代表性任务进行了实验:图像超分辨率(包括经典、轻量级和真实世界图像超分辨率)、图像去噪(包括灰度和彩色图像去噪)和 JPEG 压缩伪影减少。实验结果表明,SwinIR 在不同任务上优于最先进的方法高达 0.14 0.45dB,而参数总数最多可减少 67%。
[√] 1.简介
图像恢复(超分、去噪、JPEG压缩)旨在退化图像中重建高质量图像,目前CNN是主力方法。多数CNN侧重于精细的架构设计(残差学习、密集连接)与传统的基于模型的方法相比,性能有了显着提高,但它们通常会遇到两个源于基本卷积层的基本问题。首先,图像和卷积核之间的交互与内容无关。使用相同的卷积核来恢复不同的图像区域可能不是最好的选择。其次,在局部处理的原则下,卷积对于远程依赖建模是无效的。
作为 CNN 的替代方案,Transformer设计了一种自我注意机制来捕获上下文之间的全局交互,并在多个视觉问题中表现出了良好的性能。然而,用于图像恢复的视觉 Transformers通常将输入图像分成固定大小(例如 48 48)的块,并独立处理每个块。这种策略不可避免地会带来两个缺点。首先,边界像素不能利用补丁外的相邻像素进行图像恢复。其次,恢复后的图像可能会在每个补丁周围引入边界伪影。虽然这个问题可以通过补丁重叠来缓解,但它会带来额外的计算负担。
最近,Swin Transformer显示出巨大的潜力,因为它集成了 CNN 和 Transformer 的优点。一方面,由于局部注意机制,它具有 CNN 处理大尺寸图像的优势。另一方面,它具有 Transformer 的优势,可以使用移位窗口方案对远程依赖进行建模。
基于 Transformer 的 SwinIR 比CNN有几个好处:
alec:
- 最近,Swin Transformer显示出巨大的潜力,因为它集成了 CNN 和 Transformer 的优点。一方面,由于局部注意机制,它具有 CNN 处理大尺寸图像的优势。另一方面,它具有 Transformer 的优势,可以使用移位窗口方案对远程依赖进行建模。
- 图像内容和注意力权重之间基于内容的交互,可以解释为空间变化的卷积
- 移动窗口机制支持远程依赖建模
- 用更少的参数获得更好的性能
[√] 2.相关工作
- 图像修复
- 视觉Transformer
最近,自然语言处理模型 Transformer在计算机视觉社区中广受欢迎。当用于图像分类、对象检测、分割和人群等视觉问题时计数,它通过探索不同区域之间的全局交互来学习关注重要的图像区域。由于其令人印象深刻的性能,Transformer 也被引入用于图像恢复。IPT 和 VSR-Transformer 都是 patch-wise attention,可能不适用于图像恢复。
[√] 3.SwinIR模型
[√] 3.1.网络架构
浅层特征提取(低频)——深度特征提取(高频)——高质量(HQ)图像重建模块
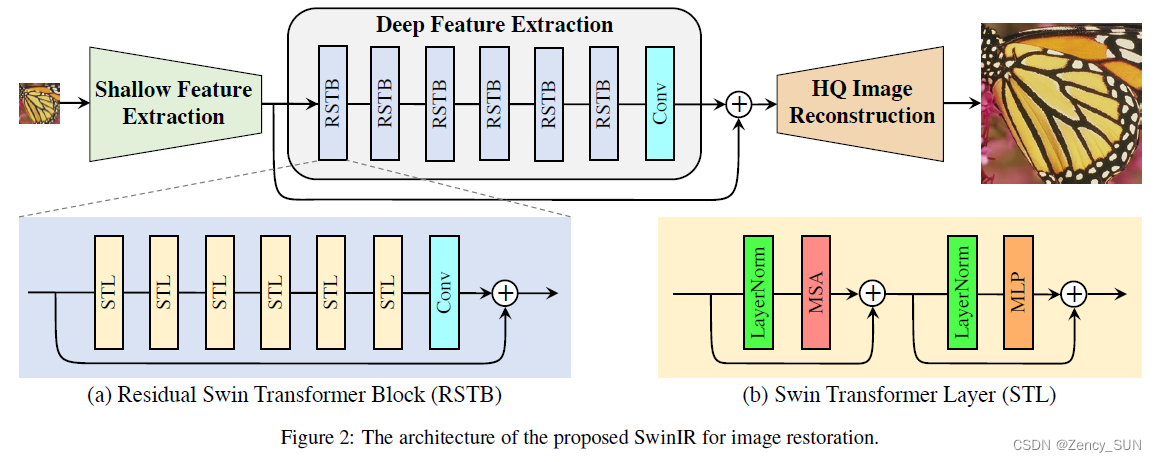
alec:
- STL = Swin Transformer Layer,这个模块的结构是 LN + MSA + 跳跃连接 + LN + MLP + 跳跃连接。
- RSTB = 多个STL模块 + 残差连接
[√] 3.2.残差Swin-Transformer块(RSTB)
alec:
- Transformer 可以被视为空间变化卷积的特定实例
- CNN则是空间不变性的卷积
在RSTB最后设计卷积有两个好处:
- Transformer 可以被视为空间变化卷积的特定实例,但具有空间不变滤波器的卷积层可以增强 SwinIR 的平移等方差
- 残差连接提供了从不同块到重建模块的基于身份的连接,允许聚合不同级别的特征
STL层的解释:Swin Transformer 层 (STL)基于原始 Transformer 层的标准多头自注意力。主要区别在于局部注意力和转移窗口机制。
- 输入H×W×C,STL先使用M×M窗口将其转成HW/M2×M2×C,HW/M2是窗口总数
- 为每个窗口计算标准自注意力(局部注意力),对于一个局部局部窗口特征X(M2×C),query,key,value计算为:Q = XPQ;K= XPK;V=XPV,其中 PQ、PK 和 PV 是在不同窗口之间共享的投影矩阵。一般来说Q,K,V(M2×d)
- 注意力矩阵由局部窗口中的自注意力机制计算为
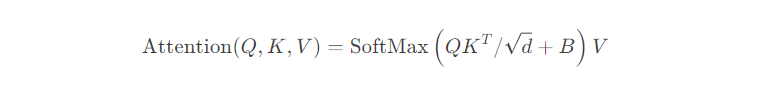
其中 B 是可学习的相对位置编码。本文并行执行 h 次注意力函数,并将结果连接起来用于多头自注意力 (MSA)。
alec:
- STL中的MSA指的是多头自注意力
- STL = 层规范化 + 多头自注意力 + 层规范化 + MLP
- 计算注意力的方式是将特征图分为多个块,计算每个块的自注意力
- 多头自注意力就是指的用多个自注意力
[√] 4.实验
[√] 4.1.实验设置
- RSTB为6个,STL为6个,窗口大小为8,通道数为180,注意力头数为6
- 对于轻量级图像 SR,我们将 RSTB 数量和通道数量分别减少到 4 和 60
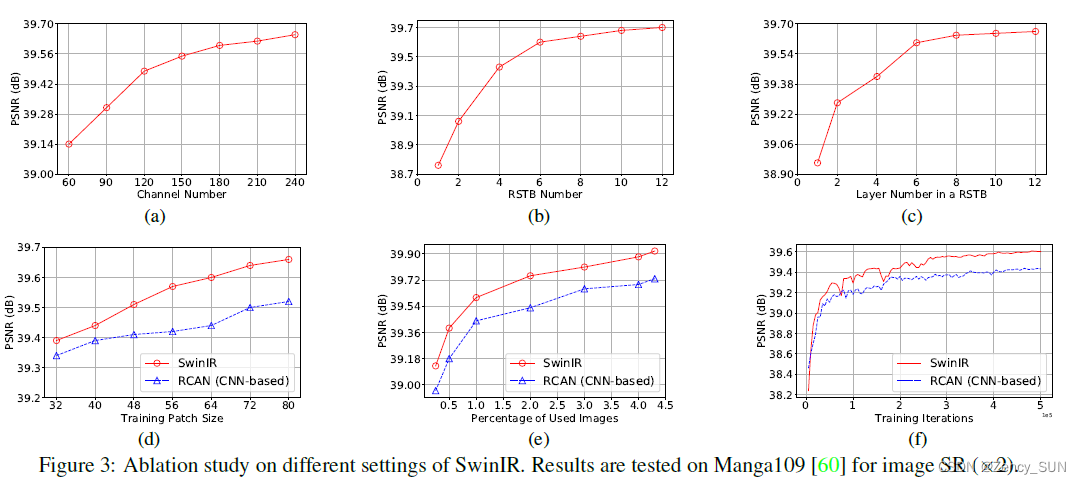
[√] 4.2.消融实验
- 1.通道数、RSTB数、STL数的影响
- 2.补丁大小和训练图像数量的影响;模型收敛比较
对于e,首先,正如预期的那样,SwinIR 的性能随着训练图像数量的增加而提高。其次,与 IPT 中观察到的基于 Transformer 的模型严重依赖大量训练数据不同,SwinIR 比使用相同训练数据的基于 CNN 的模型取得了更好的结果,即使数据集很小(即 25%, 200 张图像)。
对于f,SwinIR 比 RCAN 收敛得更快更好,这与之前的观察相矛盾,即基于 Transformer 的模型经常遭受模型收敛缓慢的困扰
3.RSTB 中残差连接和卷积层的影响
首先,RSTB 中的残余连接很重要,因为它将 PSNR 提高了 0.16dB。
其次,使用 1 ×1 卷积带来的改进很小,可能是因为它不能像 3 ×3 卷积那样提取局部邻近信息。
第三,虽然使用三个3 × 3卷积层可以减少参数数量,但是性能略有下降

[√] 4.3.超分辨结果
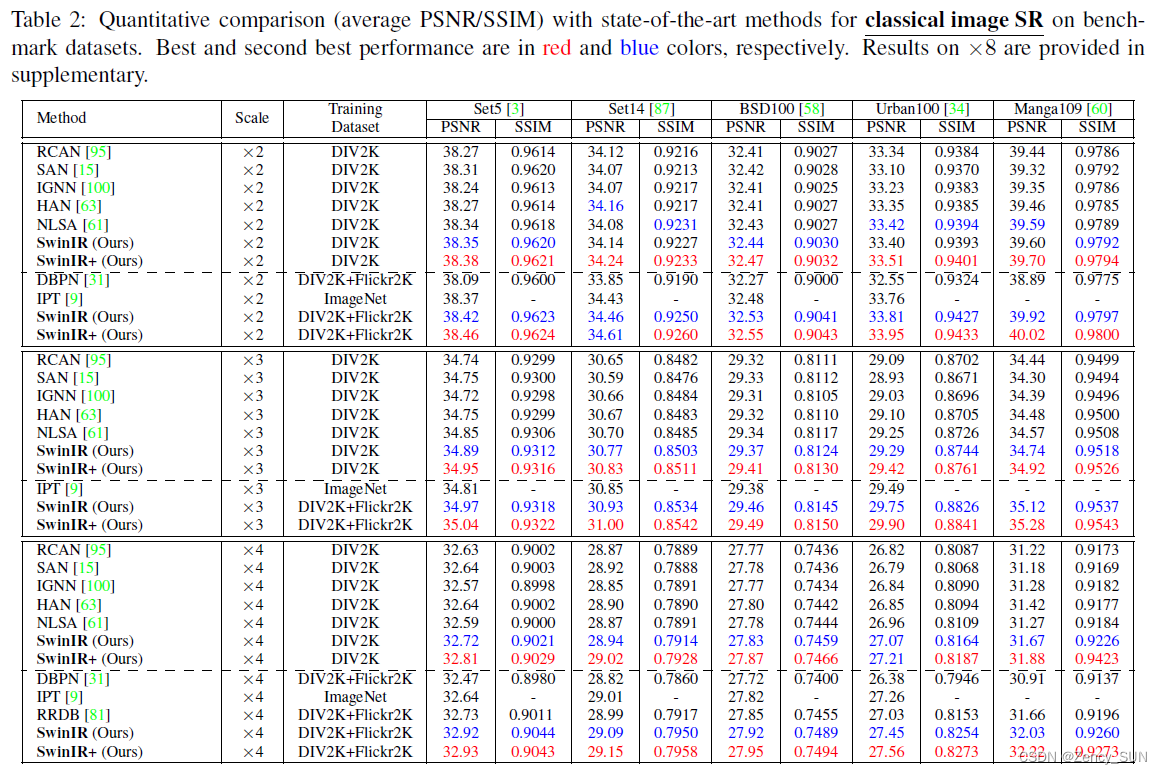
1.经典图像SR
- 轻量级图像SR
- 真实世界SR
[第2,3部分见原文]
[√] 4.4.JPEG 压缩伪影减少的结果
[见原文]
[√] 4.5.图像去噪结果
[见原文]
[√] 5.结论
在本文中,我们提出了一种基于 Swin Transformer 的图像恢复模型 SwinIR。该模型由三部分组成:浅层特征提取、深层特征提取和HR重建模块。特别是,我们使用一堆残差 Swin Transformer 块 (RSTB) 进行深度特征提取,每个 RSTB 由 Swin Transformer 层、卷积层和残差连接组成。大量实验表明,SwinIR 在三个代表性图像恢复任务和六个不同设置上实现了最先进的性能:经典图像 SR、轻量级图像 SR、真实世界图像 SR、灰度图像去噪、彩色图像去噪和 JPEG 压缩伪影减少,这证明了所提出的 SwinIR 的有效性和普遍性。未来,我们会将模型扩展到图像去模糊和去雨等其他恢复任务。
[√] 代码实现
https://github.com/JingyunLiang/SwinIR
[√] 个人总结
- 本文是将Transformer引入到超分辨领域的一个重要突破(Transformer本质也是注意力机制)
- 不仅用于超分,还可以用在图像去噪、JPEG减少伪影等图像恢复领域