008 - 文章阅读笔记:图像超分辨率学习总结 - 知乎 - 桃川京夏
本文最后更新于:3 个月前
链接:
编辑于 2022-09-20 19:50
图像超分辨率学习总结
本文对图像超分辨率的主要发展历程进行梳理,并对超分辨率中其他的一些进展做了简单概述,最后总结归纳了未来发展趋势。
[√] 一、主要发展历程
基于深度学习的图像超分辨率(Super-resolution)这一方向大体上随着主流分类模型的结构一起发展,大致的推进过程如下。
1、随着AlexNet的提出,卷积神经网络同样开始应用于图像超分辨率。
代表论文:
Image super-resolution using deep convolutional networks(SRCNN)
2、VGGNet采用连续的几个3×3的卷积核代替AlexNet中的较大卷积核,在保证感受野的情况下提升了网络的深度。与之对应,图像超分辨率网络也开始使用更小的卷积核和使用更多的映射层。
代表论文:
Accelerating the super-resolution convolutional neural network(FSRCNN)
3、随着ResNet的提出,残差结构开始在超分辨率网络中普及。
代表论文:
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network(SRResNet)
Accurate Image Super-Resolution Using Very Deep Convolutional Networks(VDSR)
Deeply-Recursive Convolutional Network for Image Super-Resolution(DRCN)
Image Super-Resolution via Deep Recursive Residual Network(DRRN)
4、继ResNet之后,各类变体层出不穷,比较有代表性的有DenseNet。DenseNet所提出的密集连接思想,能够充分利用所有的多级特征,在图像超分辨率中获得了不错的效果。
代表论文:
Image Super-Resolution Using Dense Skip Connections(SRDenseNet)
Residual Dense Network for Image Super-Resolution(RDN)
此外,针对ResNet的其他各种改进也被应用于超分辨率网络,包括多路径结构、各种卷积的变体等。
5、批量规范化的考虑
在所有的改进中,Batch Norm的使用在超分辨率网络和通用分类网络中有较大的不同Batch Norm会忽略图像像素(或者特征)之间的绝对差异(因为均值归零,方差归一),而只考虑相对差异,所以在不需要绝对差异的任务中(比如分类),有锦上添花的效果。而对于图像超分辨率这种需要利用绝对差异的任务,Batch Norm只会添乱。
在论文Enhanced Deep Residual Networks for Single Image Super-Resolution(EDSR)中,作者移除残差网络中的批归一化,把残差层的数量从16增加到32。EDSR最有意义的模型性能提升是去除掉了SRResNet多余的模块,从而可以扩大模型的尺寸来提升结果质量。
6、以SENet(Channel Attention)、Non-Local Attention为代表的注意力机制被提出,各种注意力机制的应用、魔改涌入图像超分辨率方向。
代表论文:
Image Super-Resolution Using Very Deep Residual Channel Attention Networks(RCAN)
Second-order Attention Network for Single Image Super-Resolution(SAN)
Single Image Super-Resolution via a Holistic Attention Network(HAN)
Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining(CSNLN)
Context Reasoning Attention Network for Image Super-Resolution(CRAN)
由于注意力机制相对简单、比较容易采用,因此这一阶段的论文非常多。也是从这一阶段开始,超分辨率模型的提升开始变小,一方面是因为基数较高,另一方面也是因为注意力机制在超分辨率模型中的收益本就并不高。以最先采用了通道注意力机制的RCAN为例,其网络结构如下图所示:
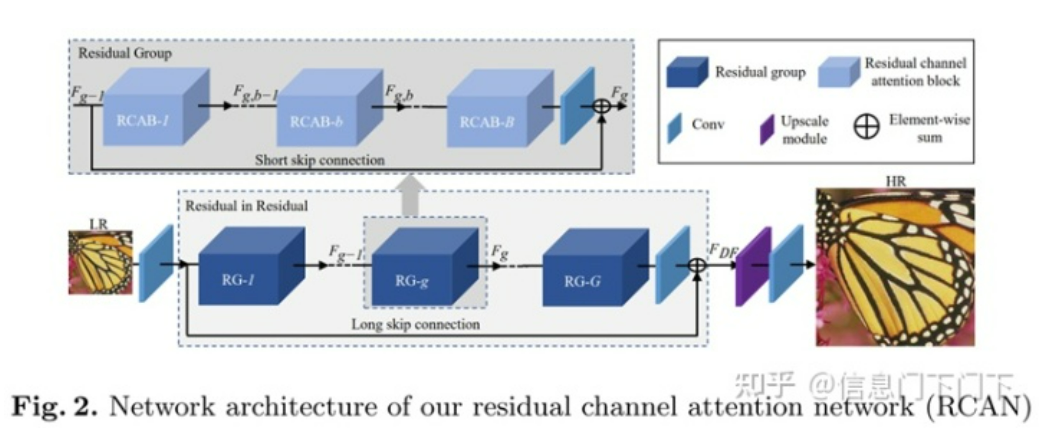
该论文中通道注意力机制Channel Attention(CA)也是一个主要创新点,但从消融实验结果来看,Channel Attention的效果非常一般,单独使用提升了0.07,配合两种残差结构LSC、SSC一起使用仅提升了0.03,效果明显小于两种残差连接(LSC和SSC),还得考虑Channel Attention增加的计算量。

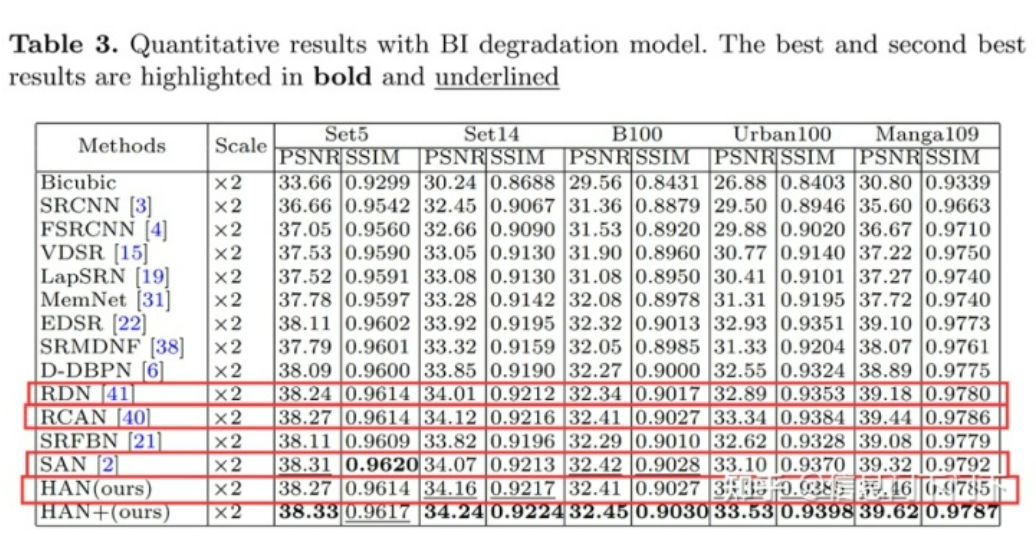
个人认为,Channel Attention在超分辨率中效果一般的原因在于:超分网络每个子模块的通道数保持不变,不会像分类网络/backbone那样随着网络的加深,特征图分辨率变小,通道数变多。通道注意力机制需要在通道数较多时,才能提取足够的信息来建立通道间的关系。而RCAN的每个子模块通道数为64,明显少于一般backbone的256、512、1024,因此失效。同理,由于输入图片的分辨率较低,空间注意力机制Spatial Attention的效果应该也不会太好,理论上Spatial Attention不太适用于RCAN这类后端上采样的超分网络。从下表更能看出,各种注意力机制的堆叠(RCAN/SAN/HAN)相比于只采用密集连接+残差的RDN提升并不明显。
7、随着ViT的提出,Transformer开始应用于计算机视觉。
代表论文:
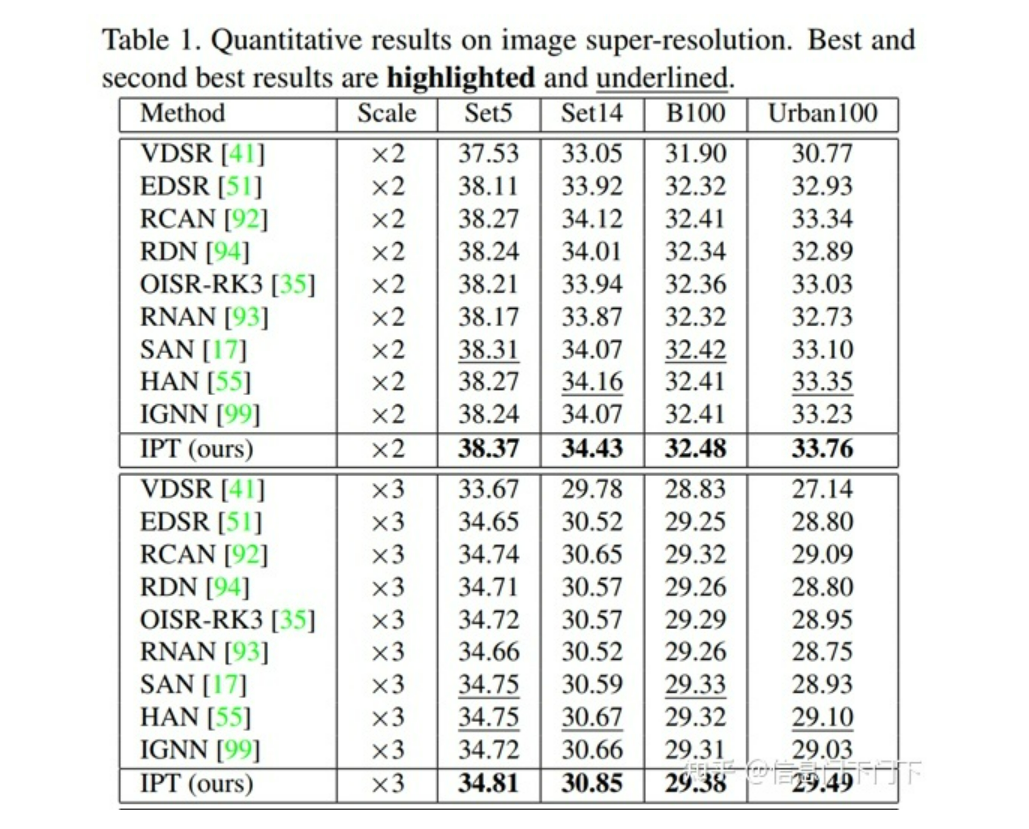
Pre-Trained Image Processing Transformer(IPT,CVPR 2021)
IPT采用了原版的Transformer,模型的参数量很大(116M),因此模型训练的难度会比较大,作者利用ImageNet作为基线数据集来预训练模型。
这篇论文第一个提出将Transformer应用于底层视觉任务,且不止做图像超分辨率一个任务,而是同时做去噪、去雨、超分三个任务。通过构建一个基于Transformer的预训练模型,利用上它强大的表征能力,以Transformer为核心,配上不同的Head和Tails,以完成相对应的底层视觉任务。在超分任务中,IPT的效果比起各种注意力机制也要明显一些。
8、在这一阶段,分类模型的优化基本演变为了Transformer的魔改,主要改进方向有两个:(1)对Transformer本身的优化,包括模型结构优化、轻量化等;(2)CNN和Transformer的结合,以Swin Transformer为典型代表。这些Transformer的魔改同样被搬到了底层视觉任务。
代表论文:
SwinIR: Image Restoration Using Swin Transformer(SwinIR,ICCV 2021)
Image super-resolution with non-local sparse attention(NLSA,CVPR 2021)
Efficient Non-Local Contrastive Attention for Image Super-Resolution(ENLCA,AAAI 2022)
Rich CNN-Transformer Feature Aggregation Networks for Super-Resolution(ACT)
这些模型的创新不是很足,有些甚至可以说是Transformer变体在底层视觉任务中的应用,如SwinIR套用了Swin Transformer,NLSA套用了ReFormer。但像SwinIR等基本都会做多个底层视觉任务,工作量都很大。
在这一阶段的魔改中,Swin Transformer算是一个非常成功的改进,创造性的提出了局部注意力计算模块LSA,即仅仅在窗口内计算自注意力,相比ViT性能也有极大的提升,将Transformer 实用性提升了一大步。而更多的论文则是对Transformer引入CNN的局部信息来提升性能和收敛速度,虽然多少有些效果,但这种混合CNN和Transformer的做法我觉得违背了设计初衷。但是从目前来看,CNN和Transformer本身就没啥好特意区分的,两者在某个角度上甚至是等价的。
9、和上一阶段基本是同步的,属于对Transformer的进一步探索,通过挖掘预训练(Pre-training)策略进一步提升网络性能。
代表论文:
On Efficient Transformer-Based Image Pre-training for Low-Level Vision(EDT)
Activating More Pixels in Image Super-Resolution Transformer(HAT)
EDT论文中指出:预训练在不同low-level任务中起不同的作用。比如,在超分任务中,预训练可以为更高层引入更多局部信息,进而产生显著性能提升;与此同时,预训练几乎不会影响降噪网络的内部特征表达,故而产生了轻微的性能提升。更进一步,通过探索了不同的预训练方法并证实:多任务预训练更有效且数据高效。
10、受Transformer兴起的启发,多层感知机MLP也再度兴起,例如MLP-Mixer、gMLP等,MLP也同样被应用于底层视觉任务中。
代表论文:
MAXIM: Multi-Axis MLP for Image Processing(MAXIM,CVPR 2022)
MAXIM这篇论文实际上没有做图像超分辨率,而是做了去噪、去模糊、去雨、去雾、增强五个任务。超分任务一般用单尺度的架构,而这篇文章采用了UNet作为基础算法,具有多尺度结构,所以没有做超分(一样的情况还有Uformer: A General U-Shaped Transformer for Image Restoration,也是采用了UNet结构,做了其他底层视觉任务但没有做超分)。但实际上,把MAXIM或者其他MLP变体的主要block搬到单尺度的超分拓扑中,应该也是完全行得通的。
小结:
在2019年的综述Deep Learning for Image Super-resolution: A Survey中,将图像超分辨率的结构分为以下四种:(a) 前端上采样Pre-upsampling SR;(b) 后端上采样Post-upsampling SR;(c) 渐进式上采样Progressive upsampling SR;(d) 升降采样迭代Iterative up-and-down Sampling SR。
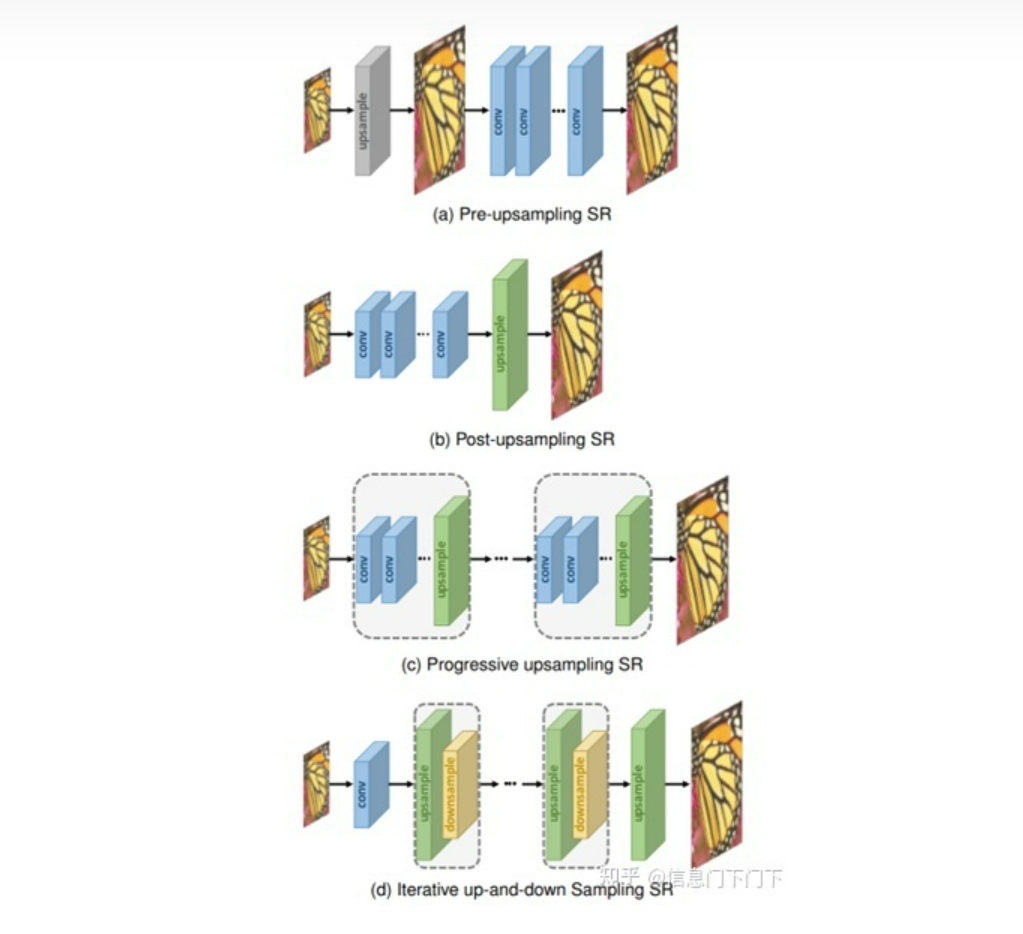
在发展过程中,后端上采样的结构具有引入噪声少、速度快的优点,逐渐成为主流。目前,图像超分辨率这一领域已趋于成熟,不再区分上述四种形式,基本已经统一为先修复、再放大的结构,即后端上采样。模型基本都遵循相同的定式:浅层特征提取(head)+深层特征提取(body)+重建模块(tail)。随着分类模型的推进,图像超分辨率的改进目前大多都是在以上定式之下,改进网络的body(CNN/Transformer/MLP)。
[√] 二、其他进展
这部分是对主要发展历程做的一个补充,包括GAN/轻量级图像超分/任意倍数缩放这些更小的方向。
[√] 1、GAN
代表论文:
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network(SRGAN)
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks(ESRGAN,模型上的改进和超分网络的主要发展历程一致,同样是+密集链接-BN)
Designing a Practical Degradation Model for Deep Blind Image Super-Resolution(BSRGAN)
Best-Buddy GANs for Highly Detailed Image Super-Resolution(AAAI 2022)
[√] 2、轻量级图像超分
代表论文:
Fast, accurate, and lightweight super-resolution with cascading residual network(CARN)
Fast, accurate and lightweight superresolution with neural architecture search(FALSR-A)
Lightweight image super-resolution with information multi-distillation network(IMDN)
Lapar: Linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond(LAPAR-A)
Latticenet: Towards lightweight image super-resolution with lattice block(LatticeNet)
查表:
Practical Single-Image Super-Resolution Using Look-Up Table(SR-LUT)
Learning Series-Parallel Lookup Tables for Efficient Image Super-Resolution(ECCV 2022)
[√] 3、任意倍数缩放
代表论文:
Meta-SR: A Magnification-Arbitrary Network for Super-Resolution(Meta-SR)
Learning Continuous Image Representation with Local Implicit Image Function(LIIF)
Local Texture Estimator for Implicit Representation Function(LTE,CVPR 2022)
Towards Bidirectional Arbitrary Image Rescaling: Joint Optimization and Cycle Idempotence(BAIRNet,CVPR 2022)
[√] 4、无监督SR
[√] 5、盲图像超分
[√] 三、未来发展趋势
[√] 趋势一:
后续的图像超分辨率算法大体上还是会套用通用分类网络,因此随着分类模型的推进,超分辨率算法算法也会随之发展。
在分类模型中,目前的主流观点是:不论是Transformer/MLP/CNN(深度可分离卷积),只要设计的模型能够实现Token Mixing和Channel Mixing,同样的计算量下不同模型应该性能是接近的。在该观点下,各种分类模型层出不穷。
[√] 趋势二:
大模型+自监督学习(Self-Supervised Learning)
大模型往往能带来更好的效果,成功训练一个大模型的关键因素之一是对大规模数据集的使用。但与图像分类相比,用于超分辨率任务的可用数据数量相对较少。因此超分辨率将来同样可以会采用大模型+自监督学习的可能。
[√] 趋势三:
同时应用于多个底层的视觉任务
目前IPT/SwinIR/EDT等已经实现同时处理多个底层的视觉任务,且EDT证实:多种任务预训练更有效且数据高效。因此,模型的统一将来也可能成为趋势。
[√] 趋势四:
在2022年的CVPR/ECCV/AAAI中,除了主要方向的推进,更多论文集中在任意倍数缩放、轻量级图像超分这些更小的方向上。