010 - 文章阅读笔记:图像超分辨率:SwinIR学习笔记 - 知乎 - 桃川京夏
本文最后更新于:3 个月前
链接:
图像超分辨率:SwinIR学习笔记 - 知乎 - 桃川京夏(√)
发布于 2022-08-28 20:33
论文名称:SwinIR: Image Restoration Using Swin Transformer(ICCV 2021)
[√] 一、Introduction
[√] 1 Motivation:
在图像超分辨率、图像去噪、压缩等图像修复(Image restoration)任务中,卷积神经网络目前仍然是主流。
但卷积神经网络有以下两个缺陷:(1)图像和卷积核之间的交互是与内容无关的;(2)在局部处理的原则下,卷积对于长距离依赖建模是无效的。
作为卷积的一个替代操作,Transformer设计了自注意力机制来捕捉全局信息。
但视觉Transformer因为需要划分patch,因此具有以下两个缺点:
- (1)边界像素不能利用patch之外的邻近像素进行图像恢复;
- (2)恢复后的图像可能会在每个patch周围引入边界伪影,这个问题能够通过patch overlapping缓解,但会增加计算量。
Swin Transformer结合了卷积和Transformer的优势,因此本文基于Swin Transformer提出了一种图像修复模型SwinIR。
alec:
- Swin Transformer结合了卷积和Transformer的优势
[√] 2 Contribution:
和现有的模型相比,SwinIR具有更少的参数,且取得了更好的效果。
[√] 二、原理分析
[√] 1 Network Architecture
SwinIR的整体结构如下图所示,可以分为3个部分:shallow feature extraction、deep feature extraction、highquality (HQ) image reconstruction modules。对所有的复原任务采用相同的feature extraction modules,针对不同的任务采用不同的reconstruction modules。
alec:
- 整体结构分为三个部分:浅层特征提取、深层特征提取、高质量图像重建
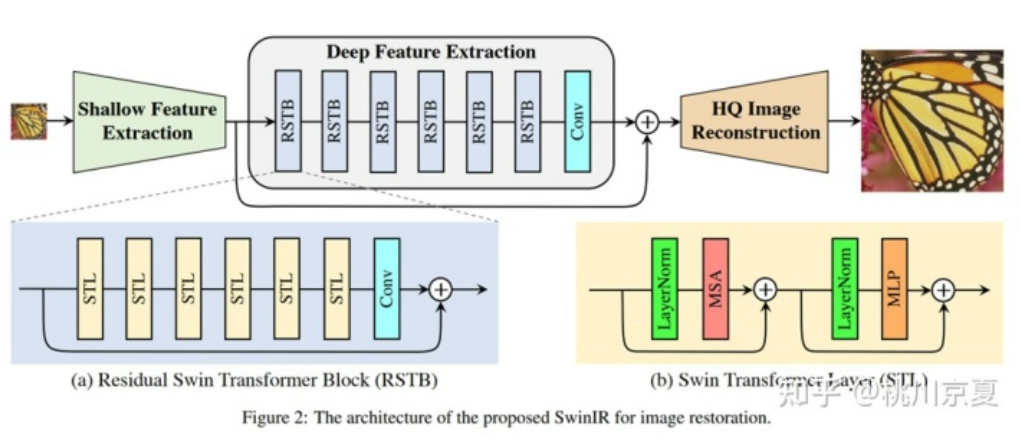
[√] 1)shallow feature extraction
首先用一个3×3卷积HSF提取浅层特征F0
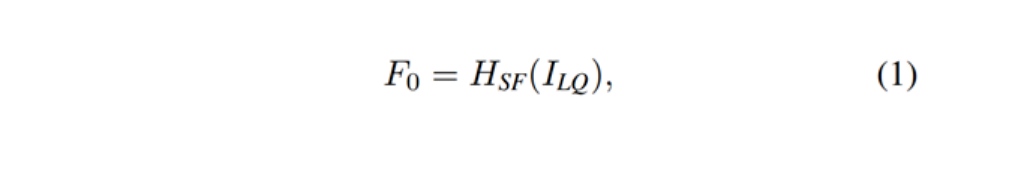
[√] 2)deep feature extraction
将提取到的浅层特征F0,使用深层特征提取模块HDF进一步提取特征。深层特征提取模块由K个residual Swin Transformer blocks(RSTB)和一个3×3卷积构成。
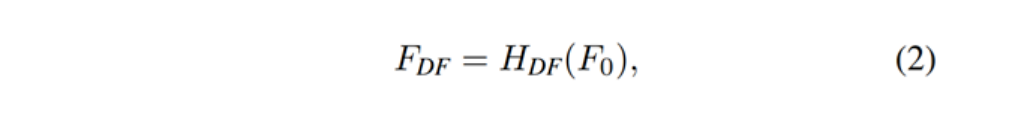
每个RSTB的输出F1,F2,FK,以及输出的深层特征FDK如式(3)所示,式中HRSTBi表示第i个RSTB模块,HCONV表示最终的卷积层。卷积层能够将卷积的归纳偏置(inductive bias)引入基于Transformer的网络,为后续浅层、深层特征的融合奠定基础。
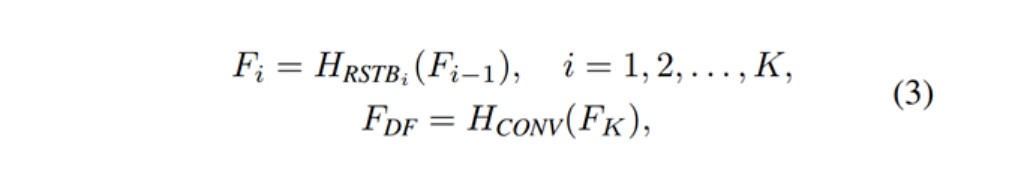
[√] 3)image reconstruction modules
以图像超分辨率为例,通过融合浅层特征F0和深层特征FDK来重建高质量图片IRHQ,式中HREC为重建模块。
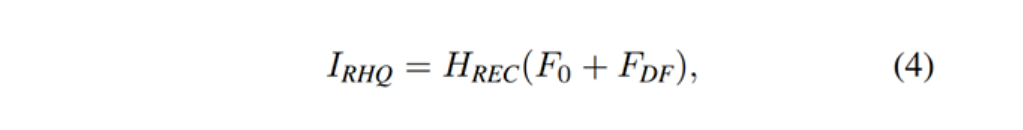
浅层特征F0主要包含低频信息,而深层特征则专注于恢复丢失的高频信息。SwinIR采用一个长距离连接,将低频信息直接传输给重建模块,可以帮助深度特征提取模块专注于高频信息,稳定训练。在图像超分辨率任务中,通过sub-pixel convolution layer将特征上采样,实现重建。在其他任务中,则是采用一个带有残差的卷积操作,如公式(5)所示。
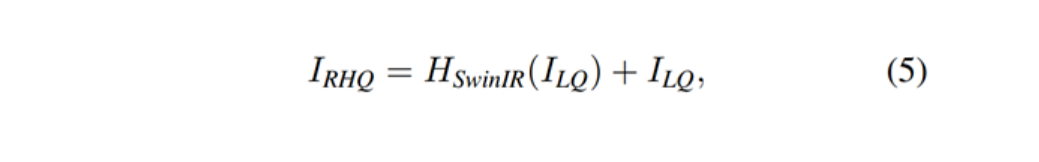
[√] 4)损失函数
图像超分辨率任务采用L1损失,通过优化SwinIR生成的高质量图像IRHQ及其对应的标签IHQ的来优化模型。
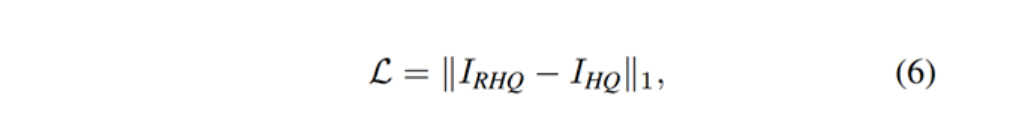
图像去噪任务和压缩任务采用Charbonnier loss,式中ɛ通常设置为10-3。
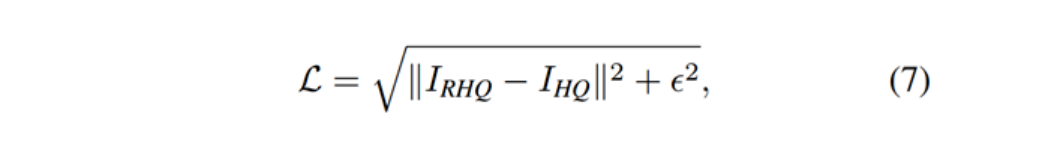
[√] 2 Residual Swin Transformer Block
如下图所示,residual Swin Transformer block (RSTB)由残差块、Swin Transformer layers (STL)、卷积层构成。卷积操作有利于增强平移不变性,残差连接则有利于模型融合不同层级的特征。
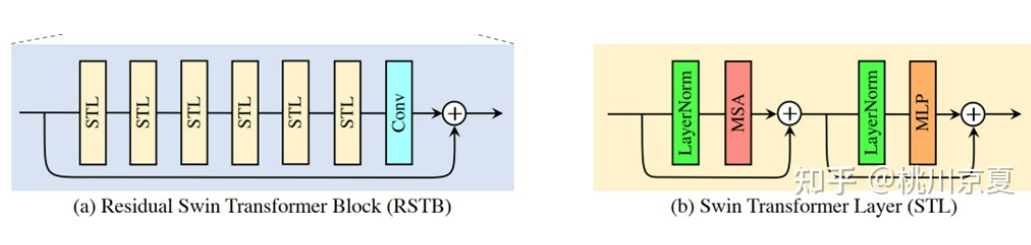
Swin Transformer layer (STL)取自论文:Swin transformer: Hierarchical vision transformer using shifted windows,和原版Transformer中multi-head self-attention的不同之处主要有局部注意力(local attention)和滑动窗口机制(shifted window mechanism)。首先,将大小为H×W×C的输入特征reshape为(HW/M2)×M2×C,即将其划分为HW/M2个M×M的local windows,然后对每个windows计算自注意力,具体如式(10)、(12)所示。第一个式子表示Query、Key、Value的计算过程,三个权重在不同的window间共享参数;第二个式子表示multi-head self-attention以及add and norm;第三个式子表示feed forward network以及add and norm。
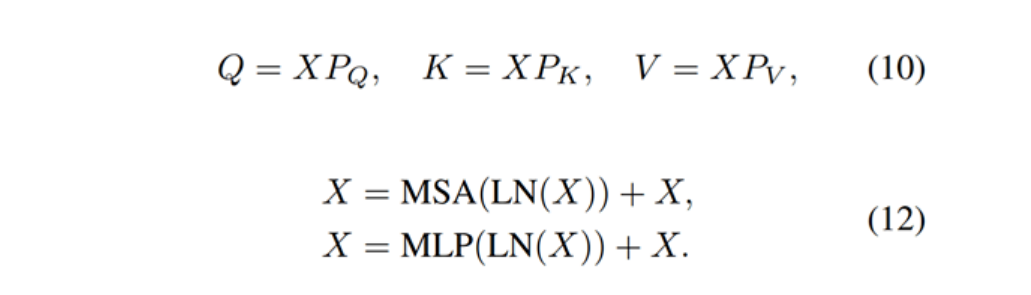
由于在local windows之间没有信息交互,因此本文交替使用常规窗口划分和滑动窗口划分来实现window间的信息交互。
[√] 三、实验结果
部分实验结果如下所示(仅选取了图像超分辨率相关的实验结果),包括经典图像超分辨率(Classical image SR)、轻量级图像超分辨率(Lightweight image SR)、真实世界图像超分辨率(Real-world image SR)。
[√] 1)经典图像超分辨率(Classical image SR)
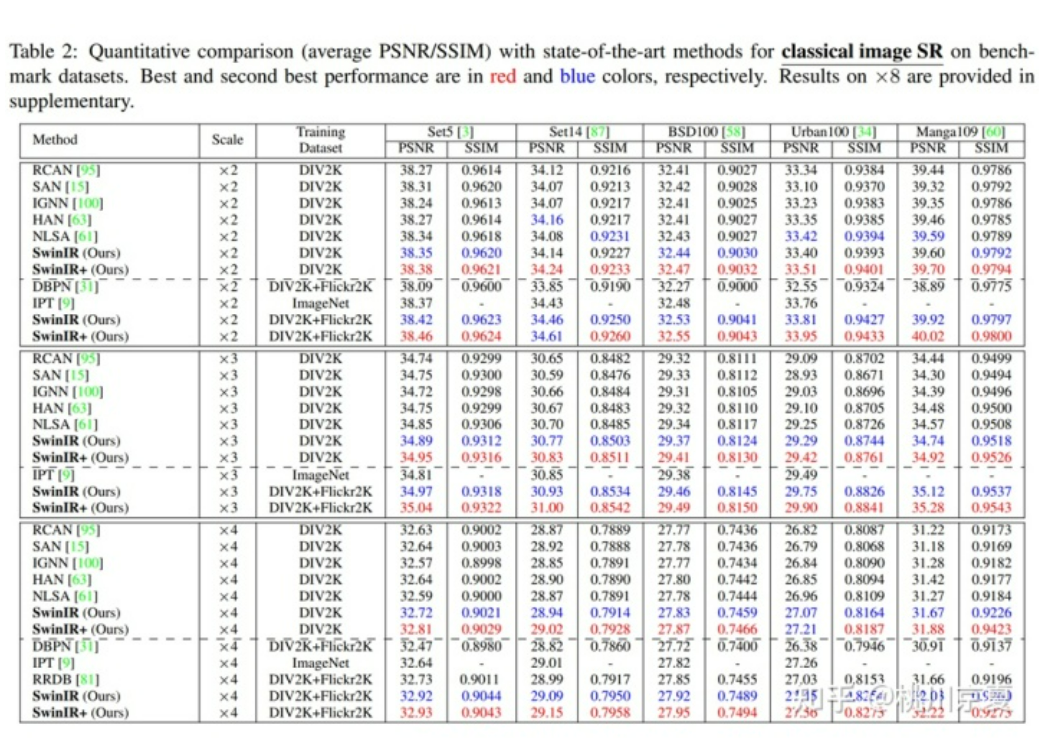
作者对比了基于卷积神经网络的模型(DBPN、RCAN、RRDB、SAN、IGNN、HAN、NLSA IPT)和最新的基于transformer的模型(IPT)。得益于局部窗口自注意力机制和卷积操作的归纳偏置,SwinIR的参数量减少至11.8M,明显少于IPT的115.5M,甚至少于部分基于卷积神经网络的模型;模型的训练难度也随之减少,不再需要ImageNet那样的大数据集来训练模型。仅使用DIV2K数据集训练时,SwinIR的精度就超过了卷积神经网络模型;再加上Flickr2K数据集后,精度就超越了使用ImageNet训练、115.5M参数的IPT模型。
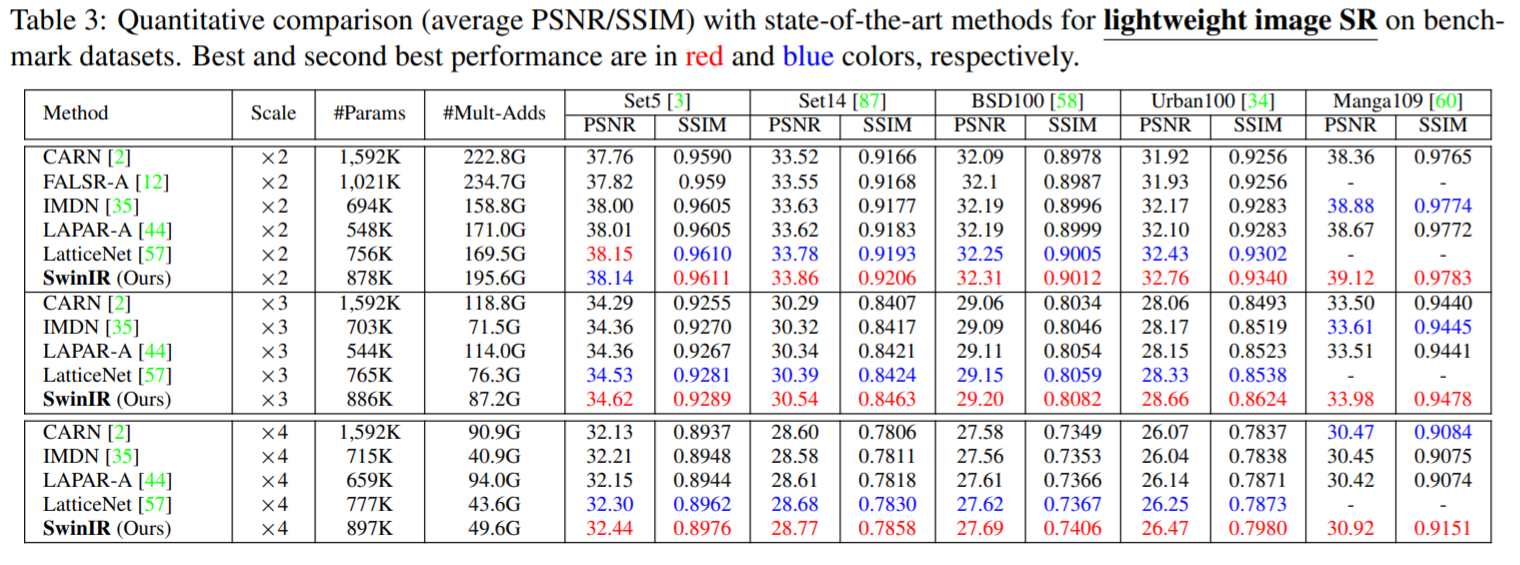
[√] 2)轻量级图像超分辨率(Lightweight image SR)
作者对比了几个轻量级的图像超分模型(CARN、FALSR-A、IMDN、LAPAR-A、LatticeNet),如下图所示,在相似的计算量和参数量的前提下,SwinIR超越了诸多轻量级超分模型,显然SwinIR更加高效。
alec:
- 可以看出,在参数量和计算量相近的前提下,SwinIR的效果超越了许多轻量级的超分模型。
[√] 3)Real-world image SR
图像超分辨率的最终目的是应用于真实世界。由于真实世界图像超分任务没有GT图像,因此作者对比了几种真实世界图像超分模型的可视化结果(ESRGAN、RealSR、BSRGAN、Real-ESRGAN)。SwinIR能够产生锐度高的清晰图像。

[√] 四、小结
alec:
- IPT仿照ViT,把Transformer运用到了图像处理任务中。
- Transformer在视觉领域魔改至今,Swin Transformer当属其中最优、运用最多的变体。
- 因此SwinIR进一步把Swin Transformer中的block搬到了图像处理任务里,模型则仍然遵循目前超分网络中head+body+tail的通用结构,改进相对比较小。
ViT算不算一个纯transformer模型本身就存在争议(因为划分patch +embeddings操作实际上就是一个卷积卷积),IPT更是直接就用的卷积做head和tail,因此SwinIR进一步在body中引入卷积也是非常合理的。
alec:
- IPT在head和tail中用的就是卷积,SwinIR是进一步在body中引入了卷积。
另一方面,Swin Transforme把卷积神经网络中常用的多尺度结构用在了基于Transforme的模型中,但图像超分辨率中一般不用多尺度结构,这或许就是SwinIR不如Swin Transforme效果好的原因。
alec:
- 在超分任务中,一般不用多尺度结构。
alec:
- 一开始超分结构归类为前端上采样、后端上采样、渐进式上采样、升降采样迭代四种,后两者就不是单一尺度
- 但后端上采样的结构具有引入噪声少、速度快的优点,所以慢慢就成了主流