2022年11月11日牛客测试题题目整理
本文最后更新于:3 个月前
1.依赖注入的方式有哪些?(√)
什么是依赖注入:依赖指的是bean需要的参数值,比如bean中的简单类型属性、引用类型属性。给bean中的属性传递值的过程叫做依赖注入。
常见的依赖注入的方式有三种,分别是set方法注入、构造方法注入、基于注解的注入
(1)参数注入方式一:set方法注入
[xml配置方式 + set方法]进行依赖注入:
在xml配置文件中,通过set进行注入:
1 | |
使用property + value进行setter注入简单类型属性
使用property + ref进行setter注入引用类型属性
对应的,UserServiceImpl 类中需要为 userDao 属性添加set方法
1 | |
注解配置方式 + set方式 进行依赖注入
1 | |
(2)参数注入方式二:构造方法注入
[xml配置方式 + 构造方法]进行依赖注入:
在xml配置文件中,通过<constructor-arg>进行构造方法方式的属性注入
1 | |
在被注入的类的定义中,添有参的构造方法用于为属性输入值:
1 | |
[注解配置方式 + 构造方法]进行依赖注入:
注解的配置方式,省去了进行xml文件配置的繁琐
1 | |
(3)参数注入方式三:注解的方式进行注入
set的方式进行依赖注入,是在 xml配置方式中 或者 注解配置方式 中通过set方法为类的属性进行传值
构造方法的方式进行依赖注入,是在 xml配置方式中 或者 注解配置方式 中通过构造方法为类的属性进行传值
而注解的方式进行依赖注入,则是直接在类中的对应属性上面打上注解,方便。
以@Autowired(自动注入)注解注入为例,修饰符有三个属性:Constructor,byType,byName。默认按照byType注入。
- constructor:通过构造方法进行自动注入,spring会匹配与构造方法参数类型一致的bean进行注入,如果有一个多参数的构造方法,一个只有一个参数的构造方法,在容器中查找到多个匹配多参数构造方法的bean,那么spring会优先将bean注入到多参数的构造方法中。
- byName:被注入bean的id名必须与set方法后半截匹配,并且id名称的第一个单词首字母必须小写,这一点与手动set注入有点不同。
- byType:查找所有的set方法,将符合符合参数类型的bean注入。
1 | |
2.spring容器的bean是线程安全的吗(√)
首先结论在这:Spring 中的单例 Bean不是线程安全的。
因为单例 Bean,是全局只有一个 Bean,所有线程共享。如果说单例 Bean,是一个无状态的,也就是线程中的操作不会对 Bean 中的成员变量执行查询以外的操作,那么这个单例 Bean 是线程安全的。比如 Spring mvc 的 Controller、Service、Dao 等,这些 Bean 大多是无状态的,只关注于方法本身。
假如这个 Bean 是有状态的,也就是会对 Bean 中的成员变量进行写操作,那么可能就存在线程安全的问题。
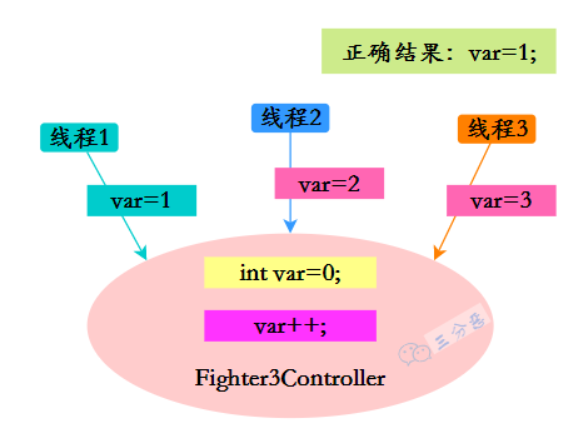
结论:Spring容器中的bean不是线程安全的
spring中没有对bean提供线程安全的策略,但是bean具体是否安全,要根据bean的具体的scope来研究
spring的bean的作用域有5种:
1、singleton:单例,默认作用域
2、prototype:原型,每次创建一个新对象
3、request:请求,每次Http请求创建一个新对象,适用于WebApplicationContext环境下
4、session:会话,同一个会话共享一个实例,不同会话使用不用的实例
5、global-session:全局会话,所有会话共享一个实例
对于原型Bean,每次创建一个新对象,也就是线程之间并不存在Bean共享,自然是不会有线程安全的问题。
对于单例Bean,所有线程都共享一个单例实例Bean,因此是存在资源的竞争。
- 如果单例Bean,是一个无状态Bean,也就是线程中的操作不会对Bean的成员执行「查询」以外的操作,那么这个单例Bean是线程安全的。比如Spring mvc 的 Controller、Service、Dao等,这些Bean大多是无状态的,只关注于方法本身。
- 线程不安全主要是因为有写操作,因此如果bean是无状态的,只涉及到读操作,那么就不会有线程安全问题
spring单例,为什么controller、service和dao确能保证线程安全?
因为这几个bean是无状态的,不会保存数据,因此不存在线程安全问题。
如果自己需要的bean是有状态的,那么就需要开发人员自己动手进行线程安全的保证。其中一个最简单的办法就是将单例bean改为原型bean,这样每次请求bean都会创建一个新的bean,因此就可以保证线程安全。
controller、service和dao层本身并不是线程安全的,只是如果只是调用里面的方法,而且多线程调用一个实例的方法,会在内存中复制变量,这是自己的线程的工作内存,是安全的。
所以其实任何无状态单例都是线程安全的。Spring的根本就是通过大量这种单例构建起系统,以事务脚本的方式提供服务。
首先问@Controller @Service是不是线程安全的?
答:默认配置下不是的。为啥呢?因为默认情况下@Controller没有加上@Scope,没有加@Scope就是默认值singleton,单例的。意思就是系统只会初始化一次Controller容器,所以每次请求的都是同一个Controller容器,当然是非线程安全的。
分析各种情况是否是线程安全的?
(1)单例模式 + 简单类型属性:不是线程安全的
(2)单例模式 + ThreadLocal:线程安全
(3)原型模式 + 简单类型属性:线程安全
(4)原型模式 + 引用类型属性:不是线程安全的
(5)原型模式 + 静态变量:不是线程安全的
小结:
1.在 @Controller/@Service 等容器中,默认情况下,scope值是单例-singleton的,也是线程不安全的。
2.尽量不要在@Controller/@Service 等容器中定义静态变量,不论是单例(singleton)还是多实例(prototype)他都是线程不安全的。
3.默认注入的Bean对象,在不设置scope的时候他也是线程不安全的。
4.一定要定义变量的话,用ThreadLocal来封装,这个是线程安全的。
子问题:单例 Bean 线程安全问题怎么解决呢?
常见的有这么些解决办法:
(1)将 Bean 定义为多例
这样每一个线程请求过来都会创建一个新的 Bean,但是这样容器就不好管理 Bean,不能这么办。
(2)在 Bean 对象中尽量避免定义可变的成员变量
削足适履了属于是,也不能这么干。
(3)将 Bean 中的成员变量保存在 ThreadLocal 中 ⭐
我们知道 ThredLoca 能保证多线程下变量的隔离,可以在类中定义一个 ThreadLocal 成员变量,将需要的可变成员变量保存在 ThreadLocal 里,这是推荐的一种方式
3.用了哪些注解以及自动装配的原理(√)
3.1 - 自动装配的原理(√)
【参考】
黑马程序员 - P15 Spring-13-自动装配(√)
3.1.1 自动装配的步骤
(1)被装配的类为被装配的属性提供set方法
1 | |
(2)实现自动装配的配置
1 | |
3.1.2 细节 注意事项
自动装配内部其实是调用的被注入属性值的类的set方法,因此set方法不能省略,如果省略则无法完成自动装配。
被注入的对象必须要被Spring的IOC容器管理,即需要将被注入的类作为bean注册到容器中
按照类型在Spring的IOC容器中如果找到多个对象,会报NoUniqueBeanDefinitionException
按照类型装配,连被注入的bean的名字都可以不起,即省去bean定义的id属性:
1 | |
3.1.3 自动装配 注意事项
- 自动装配用于引用类型依赖注入,不能对简单类型进行操作
- 使用按类型装配时(byType)必须保障容器中相同类型的bean唯一,推荐使用
- 使用按名称装配时(byName)必须保障容器中具有指定名称的bean,因变量名与配置耦合,不推荐使用
- 自动装配优先级低于setter注入与构造器注入,同时出现时自动装配配置失效
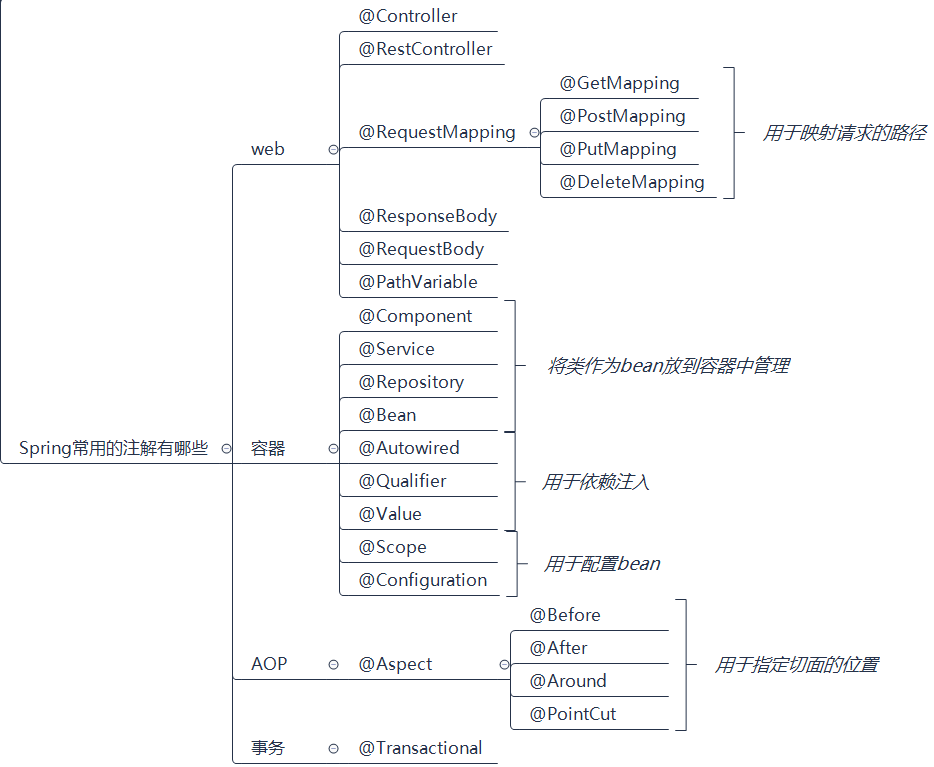
3.2 - Spring常用的注解有哪些?(√)
【参考】
简略的介绍:
(1)Web:
==@Controller:==组合注解(组合了@Component 注解),应用在 MVC 层(控制层)
==@RestController:==该注解为一个组合注解,相当于@Controller 和@ResponseBody 的组合,注解在类上,意味着,该 Controller 的所有方法都默认加上了@ResponseBody。
==@ResponseBody:==支持将返回值放在 response 内,而不是一个页面,通常用户返回 json 数据。
==@RequestMapping:==用于映射 Web 请求,包括访问路径和参数。如果是 Restful 风格接口,还可以根据请求类型使用不同的注解:
- ==@GetMapping==
- ==@PostMapping==
- ==@PutMapping==
- ==@DeleteMapping==
==@RequestBody:==允许 request 的参数在 request 体中,而不是在直接连接在地址后面。
==@PathVariable:==用于接收路径参数,比如 @RequestMapping(“/hello/{name}”)申明的路径,将注解放在参数中前,即可获取该值,通常作为 Restful 的接口实现方法。
(2)容器:
==@Component:==表示一个带注释的类是一个“组件”,成为 Spring 管理的 Bean。当使用基于注解的配置和类路径扫描时,这些类被视为自动检测的候选对象。同时@Component 还是一个元注解。
==@Service:==组合注解(组合了@Component 注解),应用在 service 层(业务逻辑层)。
==@Repository:==组合注解(组合了@Component 注解),应用在 dao 层(数据访问层)。
==@Bean:==注解在方法上,声明当前方法的返回值为一个 Bean。返回的 Bean 对应的类中可以定义 init()方法和 destroy()方法,然后在@Bean(initMethod=”init”,destroyMethod=”destroy”)定义,在构造之后执行 init,在销毁之前执行 destroy。
==@Autowired:==Spring 提供的工具(由 Spring 的依赖注入工具(BeanPostProcessor、BeanFactoryPostProcessor)自动注入)。
==@Qualifier:==该注解通常跟 @Autowired 一起使用,当想对注入的过程做更多的控制,@Qualifier 可帮助配置,比如两个以上相同类型的 Bean 时 Spring 无法抉择,用到此注解
==@Value:==可用在字段,构造器参数跟方法参数,指定一个默认值,支持 #{} 跟 ${} 两个方式。一般将 SpringbBoot 中的 application.properties 配置的属性值赋值给变量。
==@Scope:==定义我们采用什么模式去创建 Bean(方法上,得有@Bean) 其设置类型包括:Singleton 、Prototype、Request 、 Session、GlobalSession。
==@Configuration:==声明当前类是一个配置类(相当于一个 Spring 配置的 xml 文件)
(3)AOP:
==@Aspect==:声明一个切面(类上) 使用@After、@Before、@Around 定义建言(advice),可直接将拦截规则(切点)作为参数。
==@After==:在方法执行之后执行(方法上)。
==@Before==:在方法执行之前执行(方法上)。
==@Around== :在方法执行之前与之后执行(方法上)。
==PointCut==:声明切点 在 java 配置类中使用@EnableAspectJAutoProxy 注解开启 Spring 对 AspectJ 代理的支持(类上)。
(4)事务:
==@Transactional==:在要开启事务的方法上使用@Transactional 注解,即可声明式开启事务。
4.queue线程安全的集合了解吗(整理每个集合线程对应安全的集合)(√)
Java 提供的线程安全的 Queue 可以分为阻塞队列和非阻塞队列,其中阻塞队列的典型例子是 BlockingQueue,非阻塞队列的典型例子是 ConcurrentLinkedQueue。
4.1 - 队列线程安全版本之阻塞队列
【参考】
1 - BlockingQueue 简介
队列的高性能非阻塞版本是:ConcurrentLinkedQueue
队列的阻塞版本是:BlockingQueue
阻塞队列(BlockingQueue)被广泛使用在“生产者-消费者”问题中,其原因是 BlockingQueue 提供了可阻塞的插入和移除的方法。当队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。
BlockingQueue 是一个接口,继承自 Queue 接口;同时 Queue 接口继承自 Collection 接口。
下面是BlockingQueue的相关实现类:
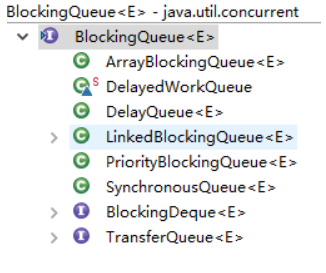
常见的 BlockingQueue 有 ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue。
2 - ArrayBlockingQueue
随手记:
ArrayBlockingQueue 是有界队列实现类
LinkedBlockingQueue 是无界队列实现类
ArrayBlockingQueue 是 BlockingQueue 接口的有界队列实现类,底层采用数组来实现。
1 | |
ArrayBlockingQueue 一旦创建,容量不能改变。容量是有限的,有界的。
使用 ReentrantLock 进行并发控制
其并发控制采用可重入锁 ReentrantLock ,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。
当队列容量满时,尝试将元素放入队列将导致操作阻塞;尝试从一个空队列中取一个元素也会同样阻塞。
ReentrantLock 默认是非公平的,因为绝对的公平性会降低吞吐量。因此 ArrayBlockingQueue 默认也是非公平的阻塞队列。即最先阻塞的队列元素,不一定最先获得锁。
ArrayBlockingQueue 默认情况下不能保证线程访问队列的公平性,所谓公平性是指严格按照线程等待的绝对时间顺序,即最先等待的线程能够最先访问到 ArrayBlockingQueue。而非公平性则是指访问 ArrayBlockingQueue 的顺序不是遵守严格的时间顺序,有可能存在,当 ArrayBlockingQueue 可以被访问时,长时间阻塞的线程依然无法访问到 ArrayBlockingQueue。如果保证公平性,通常会降低吞吐量。如果需要获得公平性的 ArrayBlockingQueue,可采用如下代码:
1 | |
3 - LinkedBlockingQueue
数据结构:
【辨析】
ArrayBlockingQueue 的底层是数组,是有界的。
LinkedBlockingQueue 的底层是单向链表,可以是有界的,也可以是无界的。
LinkedBlockingQueue 与 ArrayBlockingQueue 相比起来具有更高的吞吐量
单向链表实现的阻塞队列,可以是有界的,也可以是无界的。
有界指的是:为了防止 LinkedBlockingQueue 容量迅速增,损耗大量内存。通常在创建 LinkedBlockingQueue 对象时,会指定其大小。
无界指的是:如果未指定,容量等于 Integer.MAX_VALUE,那么就是无界的。
相关的构造方法代码:
1 | |
4 - PriorityBlockingQueue
ArrayBlockingQueue 是有界阻塞队列,LinkedBlockingQueue 和 PriorityBlockingQueue 是无界阻塞队列
PriorityBlockingQueue 是一个支持优先级的无界阻塞队列。
默认采用自然顺序进行排序,也可以自定义排序规则
PriorityBlockingQueue 并发控制采用的是可重入锁 ReentrantLock
该队列为无界队列,PriorityBlockingQueue 只能指定初始的队列大小,后面插入元素的时候,如果空间不够的话会自动扩容
简单地说,它就是 PriorityQueue 的线程安全版本。不可以插入 null 值,同时,插入队列的对象必须是可比较大小的(comparable),否则报 ClassCastException 异常。它的插入操作 put 方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
4.2 - 队列线程安全版本之非阻塞队列
Java 提供的线程安全的 Queue 可以分为阻塞队列和非阻塞队列,其中阻塞队列的典型例子是 BlockingQueue,非阻塞队列的典型例子是 ConcurrentLinkedQueue,在实际应用中要根据实际需要选用阻塞队列或者非阻塞队列。 阻塞队列可以通过加锁来实现,非阻塞队列可以通过 CAS 操作实现。
从名字可以看出,ConcurrentLinkedQueue这个队列使用链表作为其数据结构.ConcurrentLinkedQueue 应该算是在高并发环境中性能最好的队列了。它之所有能有很好的性能,是因为其内部复杂的实现。
ConcurrentLinkedQueue 内部代码我们就不分析了,大家知道 ConcurrentLinkedQueue 主要使用 CAS 非阻塞算法来实现线程安全就好了。
ConcurrentLinkedQueue 适合在对性能要求相对较高,同时对队列的读写存在多个线程同时进行的场景,即如果对队列加锁的成本较高则适合使用无锁的 ConcurrentLinkedQueue 来替代。
4.3 - List的线程安全的版本 CopyOnWriteArrayList
1 - CopyOnWriteArrayList 简介
==类的声明:==
1 | |
==思想:==
在多数的场景中,读操作远远多于写操作,并且读操作不会修改数据,因此如果无论读或者写都加锁,那么就太浪费资源和性能了。因此应该允许并发进行读操作,这是线程安全的。
这种思想和 ReentrantReadWriteLock 读写锁的思想非常类似,也就是读读共享、写写互斥、读写互斥、写读互斥。但是JDK 中提供的 CopyOnWriteArrayList 类比相比于在读写锁的思想又更进一步。
为了将读取的性能发挥到极致,CopyOnWriteArrayList 读取是完全不用加锁的,并且更厉害的是:写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。这样一来,读操作的性能就会大幅度提升。
ReentrantReadWriteLock 无论在写写、读写、写读的时候,都需要加锁;但是 CopyOnWriteArrayList 只需要在写写的时候进行阻塞,其它的时候完全不用阻塞。
2 - CopyOnWriteArrayList 是如何做到只在 写-写 的时候,阻塞?
CopyOnWriteArrayList 类的所有可变操作(add,set 等等)都是通过创建底层数组的新副本来实现的。当 List 需要被修改的时候,我并不修改原有内容,而是对原有数据进行一次复制,将修改的内容写入副本。写完之后,再将修改完的副本替换原来的数据,这样就可以保证写操作不会影响读操作了。
但是在写写的时候,因此两个线程都要修改数据,那么这个时候就要排队一个一个来了,不然就会产生线程安全问题。
从 CopyOnWriteArrayList 的名字就能看出 CopyOnWriteArrayList 是满足 CopyOnWrite 的。所谓 CopyOnWrite 也就是说:在计算机,如果你想要对一块内存进行修改时,我们不在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后呢,就将指向原来内存指针指向新的内存,原来的内存就可以被回收掉了。
3 - CopyOnWriteArrayList 读取和写入源码简单分析
3.1 - 读取操作的实现
读取操作没有任何同步控制和锁操作,理由就是内部数组 array 不会发生修改,只会被另外一个 array 替换,因此可以保证数据安全。
1 | |
3.2 - 写入操作的实现
CopyOnWriteArrayList 写入操作 add()方法在添加集合的时候加了锁,保证了同步,避免了多线程写的时候会 copy 出多个副本出来。
add方法:加锁,然后拷贝出一个新的数组,新的数组的长度是原来的长度 + 1,然后在新数组的末尾添加元素,并将指针指向新的数组。
1 | |
4.4 - ConcurrentHashMap
==直接加锁存在严重的性能问题==
我们知道 HashMap 不是线程安全的,在并发场景下如果要保证一种可行的方式是使用 Collections.synchronizedMap() 方法来包装我们的 HashMap。但这是通过使用一个全局的锁来同步不同线程间的并发访问,因此会带来不可忽视的性能问题。
==HashMap 的线程安全版本==
所以就有了 HashMap 的线程安全版本—— ConcurrentHashMap 的诞生。
在 ConcurrentHashMap 中,无论是读操作还是写操作都能保证很高的性能:在进行读操作时(几乎)不需要加锁,而在写操作时通过锁分段技术只对所操作的段加锁而不影响客户端对其它段的访问。
读操作的时候几乎不需要加锁,在写操作的时候,使用分段锁技术,细粒度地只对操作的位置进行加锁,其它的问题仍然可以继续访问。
5.newFixedThreadPool梳理(√)
(1)newFixedThreadPool
固定的n个核心线程,多余的任务去阻塞队列排队,阻塞队列是LinkedBlockingQueue,是无限的队列,有内存溢出风险。
(2)SingleThreadExecutor(只有一个核心线程)
当 newFixedThreadPool 的核心线程数量为 1 的时候,为 SingleThreadExecutor 。
(3)newCachedThreadPool
线程线程数量为0,任务先放到阻塞队列中,如果有空闲的最大线程,则复用,没有的话则创建。可以创建无限个线程。阻塞队列中不存储任务。
使用了SynchronousBlockingQueue作为任务队列,不存储元素,吞吐量高于 LinkedBlockingQueue 。