039 - 文章阅读笔记:AIM2020-ESR 冠军方案解读:引入注意力模块 ESA,实现高效轻量的超分网络(附代码实现) - 极市平台 - ExtremeMart
本文最后更新于:3 个月前
AIM2020-ESR 冠军方案解读:引入注意力模块 ESA,实现高效轻量的超分网络(附代码实现) - 极市平台 - ExtremeMart
2020-09-30
[√] 文章信息
本文首发自公众号极市平台(微信公众号ID:extrememart),作者 @Happy,转载需获授权。
导读:该文是南京大学提出的一种轻量&高效图像超分网络,它获得了AIM20-ESR竞赛的冠军。它在IMDN的基础上提出了两点改进,并引入RFANet一种的ESA注意力模块。如果从结果出发来看RFDN看上去很简单,但每一步的改进却能看到内在的一些思考与尝试。值得初入图像复原领域的同学仔细研究一下该文。

paper: https://arxiv.org/abs/2009.11551
code: https://github.com/njulj/RFDN(预训练模型未开源)
论文标题:用于轻量级图像超分的残差特征蒸馏网络
[√] Abstract
受益于CNN强大的拟合能力,图像超分取得了极大的进展。尽管基于CNN的方法取得了极好的性能与视觉效果,但是这些模型难以部署到端侧设备(高计算量、高内存占用)。
为解决上述问题,已有各种不同的快速而轻量型的CNN模型提出,IDN(Information Distillation Network, IDN)是其中的佼佼者,它采用通道分离的方式提取蒸馏特征。然而,我们并不是很清晰的知道这个操作是如何有益于高效SISR的。
该文提出一种等价于通道分离操作的特征蒸馏连接操作(Feature Distillation Connection, FDC),它更轻量且更灵活。基于FDC,作者对IMDN(Information Multi Distillation Network, IMDN)进行了重思考并提出了一种称之为RFDN(Residual Feature Distillation Network, RFDN)的轻量型图像超分模型,RFDN采用多个FDC学习更具判别能力的特征。与此同时,作者还提出一种浅层残差模块SRB(Shallow Residual Block, SRB)作为RFDB的构件模块,SRB即可得益于残差学习,又足够轻量。
最后作者通过实验表明:所提方法在性能与模型复杂度方面取得了更多的均衡。更进一步,增强型的RFDN(Enhanced RFDN, E-RFDN)获得了AIM2020 Efficient Super Resolution竞赛的冠军。
该文的主要贡献包含以下几点:
- 提出一种轻量型残差特征蒸馏网络用于图像超分并取得了SOTA性能,同时具有更少的参数量;
- 系统的分析了IDM并对IMDN进行重思考,基于思考发现提出了FDC;
- 提出了浅层残差模块,它无需引入额外参数即可提升超分性能。
[√] Method
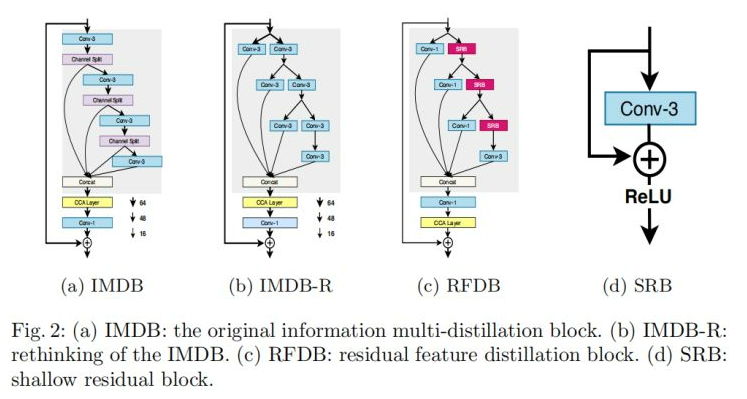
alec:
- 蒸馏操作中,将通道特征图分为两部分,一部分保留,直接在后端concat,另一部分则融入到下一阶段的蒸馏操作,递归的蒸馏。最后将所有的保留部分concat,即完成了渐进式蒸馏。
上图a给出了IMDN的核心模块IMDB的网路架构图,它是一种渐进式模块(Progressive Refinement Module),PRM部分(图中灰色背景区域)采用3times3卷积从输入特征通过多个蒸馏步骤提取特征。在每个步骤,采用通道分离操作将特征分成两部分:一部分保留,一个融入到下一阶段的蒸馏步骤。假设输入特征表示为F**in,该过程可以描述为:
F_{distilled_1}, F_{coarse_1} = Split_1(L_1(F_{in})) \$$\ F_{distilled_2}, F_{coarse_2} = Split_2(L_2(F_{coarse_1})) \$$\ F_{distilled_3}, F_{coarse_3} = Split_2(L_2(F_{coarse_2})) \$$\ F_{distilled_4} = L_4(F_{coarse_3})
其中L**j表示第j个卷积模块(包含激活单元),Split**j表示第j个通道分离操作。最后所有的蒸馏特征通过Concat进行融合得到输出:
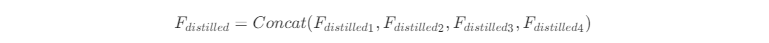
alec:
- RFDB的修改,也是将IMDB中的蒸馏模块的保留的那部分加上了一个1x1的卷积。
- 然后又在RFDB中搞了一个所谓的浅层残差模块,也就是一个1层的残差连接,模块中有一个3x3的卷积。
[√] Rethinking the IMDB
尽管PRM获得显著的提升,但不够高效且因为通道分离操作引入了某些不灵活性。通过3×3卷积生成的特征存在许多冗余参数;而且特征蒸馏是通过通道分离达成,导致其无法有效利用恒等连接。作者对通道分离操作进行了重思考并提出了一种新的等价架构以避免上述问题。
以Fig2b为例,3×3卷积后接通道分离可以拆解成两个3×3卷积DL和RL,此时改进的架构可以描述如下:
F_{distilled_1}, F_{coarse_1} = DL_1(F_{in}), RL_1(F_{in}) \$$\ F_{distilled_2}, F_{coarse_2} = DL_2(F_{coarse_1}), RL_2(F_{coarse_1}) \$$\ F_{distilled_3}, F_{coarse_3} = DL_3(F_{coarse_2}), RL_3(F_{coarse_2}) $$\ F_{distilled_4} = DL_4(F_{coarse_3}) \
也就是说每一次的通道分离操作可以视作两个卷积的协同作用,我们将这种改进称之为IMDB-R,它比IMDB更为灵活,且具有更好的解释性。
[√] Residual Feature Distillation Block
基于前述思考,作者引入该文的核心RFDB(见Fig2c),一种比IMDB更轻量更强的模块。从Fig2可以看到:信息蒸馏操作是通过3×3卷积以一定比例压缩特征通道实现。在诸多CNN模型中,采用1×1卷积进行进行通道降维更为高效,故得到Fig2c中的1×1卷积设计,采用这种替换还可以进一步降低参数量。
除了前面提到的改进外,作者还引入一种更细粒度的残差学习到RFDB。作者设计了一种浅层残差学习模块SRB(见Fig2d),它仅包含一个3×3卷积核一个恒等连接分支以及一个激活单元。SRB在不引入额外参数的前提下,还可以从残差学习中受益。
原始的IMDN仅仅包含一个粗粒度的残差连接,网络从残差连接的受益比较有限;而SRB可以耕细粒度的残差连接,可以更好的利用参数学习的能力。
[√] Framework
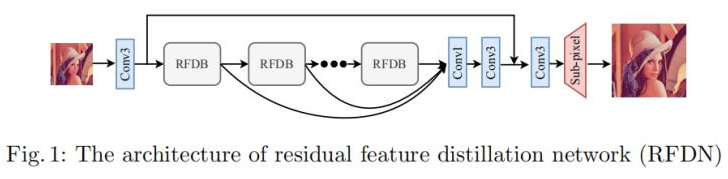
上图给出了RFDN的全局网络架构图,很明显这是一种RDN的网络结构。它包含四个部分:特征提取、堆叠RFDB,特征融合,重建上采样。
特征提取目前基本都是采用3×3卷积提取初始特征,该过程可以描述如下:
F0=h(x)
alec:
- 特征提取目前基本都是采用一个3x3的卷积,来进行提取初始特征。
- 所有的RFDB模块计算出来的特征图,最后有一个concat操作,然后通过1x1的卷积进行特征融合。

alec:
- 特征重建一般采用3x3的卷积和PixelShuffle操作相组合
[√] Experiments
训练数据:DIV2K;测试数据:Set5、Set14、BSD100、Urban100、Manga109。度量指标PSNR、SSIM。
优化器Adam,初始学习率5×10−4,每200000次迭代折半,Batch=64,随机水平、随机90度旋转。x2模型从头开始训练,其他尺度模型则以x2模型参数进行初始化。
作者实现了两个尺寸的模型:RFDN和RFDN-L。RFDN的通道数为48,模块数为6;而RFDN-L的通道数为52,模块数为6。先来看所提方法与其他SOTA方法的对比,见下表。

接下来,我们看一下消融实验部分的一些对比。为更好的说明RFDB的优势,作者设计了三组对标模块,见下图。其中FDC则是前述在IMDB之处的改进的一个版本。
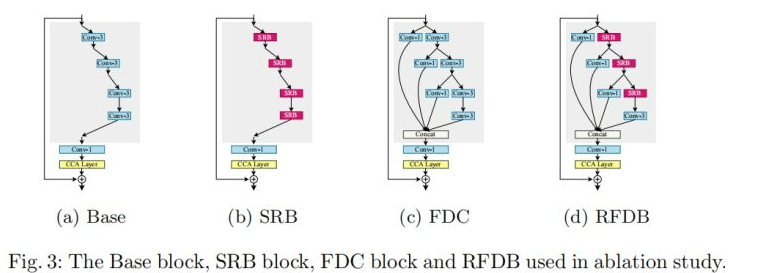
alec:
- 残差能够提升性能,且不会引入额外的参数
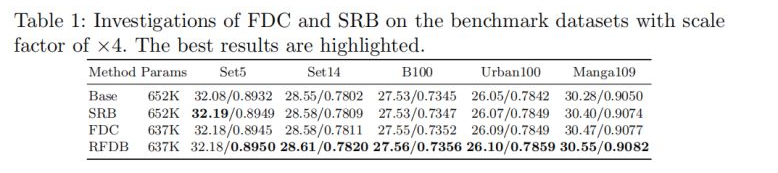
下表给出了上述四个模块构成的模型的性能与参数量对比。可以看到:(1)相比标准卷积,SRB可以提升0.12dB模型性能,且不会引入额外参数;(2)在FDC与RFDB的对比中也可以看到类似的性能提升;(3)FDC模块可以提升0.19dB模型性能;(4)FDC与SRB的组合得到了0.27dB的性能提升。
alec:
- 将提升性能的残差连接,替换原来的模块中的conv3x3,从而提升性能。
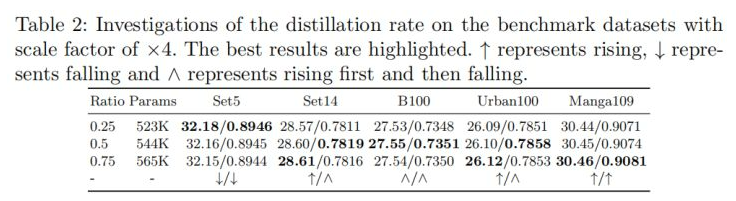
与此同时,作者探讨了蒸馏比例的影响,见下表。总而言之:从参数量与模型性能角度来看,蒸馏比例为0.5是一种比较的均衡。而这也是RFDN中采用的蒸馏比例,笔者在复现RFDN的过程中也曾疑惑过这个参数的设置,因为按照IMDN中的0.25设置的话无论如何都得不到竞赛中的那个参数量、FLOPs。
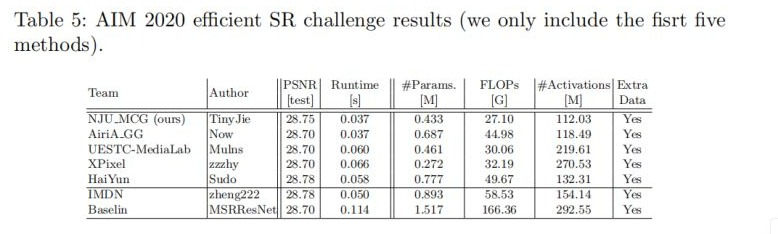
最后,作者在RFDN的基础上进行了又一次改进,引入了ESA模块,称之为Enhanced RFDN(E-RFDN)。该模型获得了AIM2020 Efficient Super Resolution竞赛的冠军,见下表。需要注意的是:E-RFDN训练数据集为DF2K,模块数为4。从表中数据可以看到:所提方法以较大的优势超越其他参赛方案。
全文到此结束,对该文感兴趣的同学建议去查看原文。
[√] 后记
事实上,在这篇论文放出之前,笔者已经在尝试进行RFDN的复现工作。当然实现方面有一点点的出入,见下面的笔者实现code,注:ESA模块是源自作者RFANet一文的代码。笔者参照E-RFDN的网络结构进行的复现,在DIV2K-val上训练200000次迭代达到了PSNR:30.47dB(YCbCr)。也就是说,这个方法看起来简单,复现起来也非常简单,关键是轻量&高效。为什么不去尝试一把呢?
1 | |