文章阅读笔记:【2019 FSSR】Frequency Separation for Real-World Super-Resolution
本文最后更新于:3 个月前
原文链接:
(1)FSSR超分辨网络 - 超分辨率重建 - 无为(link)
2021-10-22 10:14
ps:本文为依据个人日常阅读习惯,在原文的基础上记录阅读进度、记录个人想法和收获所写,关于原文一切内容的著作权全部归原作者所有。
——————————————————————————————
[√] 文章信息
论文标题:【2019 FSSR】Frequency Separation for Real-World Super-Resolution
中文标题:用于真实世界超分辨率的频率分离
论文链接:https://arxiv.org/abs/1911.07850
论文代码:https://github.com/ManuelFritsche/real-world-sr
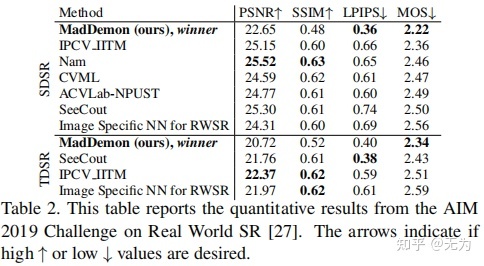
论文发表:ICCV2019,2019AIM挑战赛的冠军
论文评价:2019年的文章,Real-SR的先驱,具有启蒙作用;
——————————————————————————————
[√] 文章1
总结:
FSSR要点
【要点】
(1)核心
作者在制作数据集和生成超分辨图像两个部分,均将一副图像拆分成低频和高频两个部分进行考虑;
制作更真实的训练数据集;
考虑了自然图像的性质;
(2)数据集构建
通过提出的DSGAN,用生成对抗网络生成更真实的数据集。训练集使用DF2K,测试集用DPED,另外由于参加了AIM比赛,也用了比赛相关的数据集;
(3)超分网络backbone
ESRGAN
(4)损失函数(DSGAN和ESRGAN均使用这三个损失)
color loss(即L1 loss),perceptual loss,生成对抗损失。
其中L1损失是对低频部分计算的,生成对抗损失是对高频部分计算的,感知损失是通过vgg网络提取出来特征图计算的。
(5)主要对比方法是
ZSSR、EDSR、SRGAN、ESRGAN;
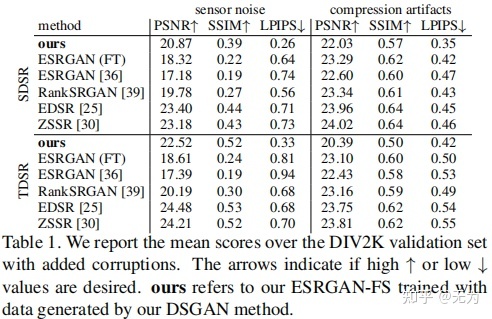
(6)图像质量评价指标
PSNR、SSIM、LPIPS、MOS。
【零碎点】
- color loss 就是 L1 loss
【看此论文自己的收获、灵感记录】
- 模型的超分模型,需要有一个backbone网络,比如本文的backbone网络是ESRGAN。自己的模型需要有一个backbone,然后可以在这个backbone的基础上进行改进,比如加入一些先进的模块。
- 本文使用了两个模型,其中DSGAN用于制作真实数据集,ESRGAN用于超分辨率重建。在制作数据集和超分的时候,均将一幅图像分成低频和高频两个部分进行考虑
- “生成网络生成的主要是图像的高频信息,而图像的低频信息在生成是几乎没有变化。”
- 本文利用超分网络主要是对高频信息进行生成,从而在通过生成对抗方式生成LR数据的时候,通过高频滤波器提取出高频信息,只对高频信息进行监督,是一个有意思的点。而对于L1损失的计算,利用低通滤波器只对低频信息进行损失计算。
- “对于图像的低频信息,作者的描述是,对于一幅低分辨图像和生成的高分辨图像在低频信息方面有一一对应的关系,因此,可以采用像素级别的损失(即作者所提到的颜色损失)来计算SR和HR之间的差异。”“而对于图像的高频部分,低分辨图像和生成的高分辨图像并不具有一一对应的关系,多幅图像可以具有同样的高频信息,因此用对抗损失来计算SR和HR之间的高频信息差异。最终,用感知损失来计算图像整体的差异”
- 无论是数据生成网路还是超分网络,都是采用了高、低频信息分别计算损失的思想。低频信息计算L1损失,高频信息计算对抗损失,原信息计算感知损失。
- 本文引入了人工噪声:高斯噪声、JPEG噪声(高斯噪声is sensor noise,JPEG噪声is压缩噪声)
- 主成分分析是否是一个可以利用的点?加入到网络中
【问题记录】
- 两种数据集的制作方法,什么是SDSR制作,什么是TDSR制作?
- ESRGAN-FT,FT是什么意思?
【网络结构】
[√] 重点摘要:
目的:解决真实场景下图像的超分问题。
核心:作者在制作数据集和生成超分辨图像两个部分,均将一副图像拆分成低频和高频两个部分进行考虑;制作更真实的训练数据集;考虑了自然图像的性质;
数据集的构建:通过提出的DSGAN,用生成对抗网络生成更真实的数据集。训练集使用DF2K,测试集用DPED,另外由于参加了AIM比赛,也用了比赛相关的数据集;
超分网络backbone:ESRGAN
损失函数(DSGAN和ESRGAN均使用这三个损失):color loss(即L1 loss),perceptual loss,生成对抗损失。
主要对比方法是:ZSSR、EDSR、SRGAN、ESRGAN;
图像质量评价指标:PSNR、SSIM、LPIPS、MOS。
[√] 数据集构建:
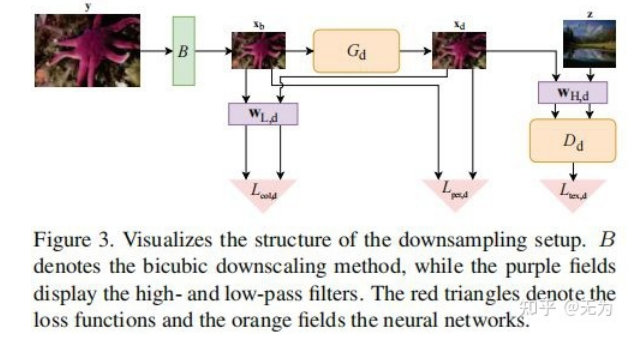
不同于传统构建数据集的方式,FSSR是通过网络生成LR图像,进而形成LR-HR对训练数据。如下图所示:
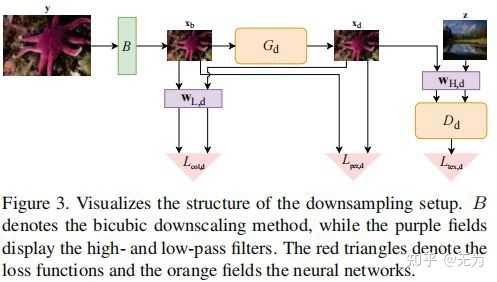
首先,我们需要了解低通滤波器和高通滤波器提取图像的低频高频信息过程。提取低频信息的实质是通过一个滤波核在图像上进行卷积,便可提取到图像的低频信息(类似于模糊核),然后用原图像减去低频图像,便可得到图像的高频信息,如下式(其中Xd表示原图像):
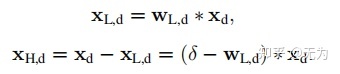
具体的,一副HR图像先经过bicubic操作,进行4倍降采样。此时获得了与LR相同尺寸的图像,然后经过生成网络便生成了LR图像。需要指出的是,生成网络生成的主要是图像的高频信息,而图像的低频信息在生成是几乎没有变化。
接着就是判别器及对抗损失的高频监督问题。作者将一副图像视为由高频和低频信息共同构成,而判别器监督的(或者说判别的),应该是图像的高频细节部分。高频细节不是一种可以明显可视化的东西,而是图像的一种抽象特征。也许一种低频信息只能对应一副图像,而一种高频信息往往能对应多幅图像。因此,可以通过将真实域的图像(通过高通滤波器)提取高频信息,同时将生成的LR图像(通过高通滤波器)提取高频信息,然后用判别器判别,计算对抗损失(即Ltex,d)。
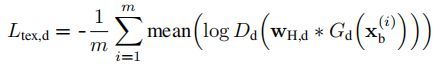
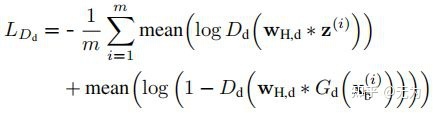
而对于低频信息的损失计算,通过使用低通滤波器,提取生成前后图像的低频信息,用L1损失(即Lcol,d)计算得出。可以这样执行的原因是生成网络只负责高频信息的生成,不生成低频信息。
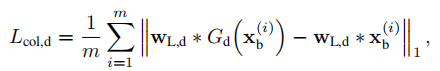
最后,生成的LR图像还需要同生成前的图像计算感知相似度,进一步指导图像生成。类似于超分网络,图像降级网络的感知损失(即Lper,d)也是通过vgg网络和L1损失协同完成的。
最终整个生成对抗网络的损失函数,通过上述三种损失的加权得到,如下式:
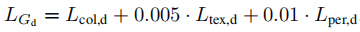
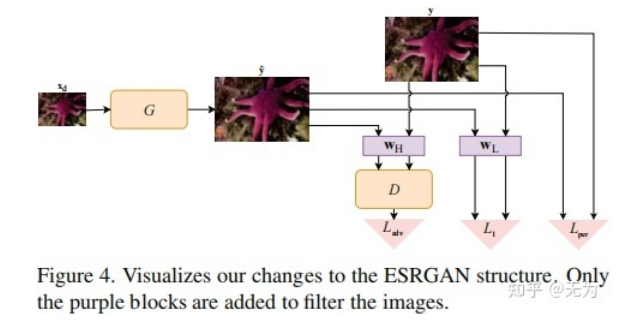
[√] 超分网络构建:
超分网络的构建仍然是用了频率分离的思想。
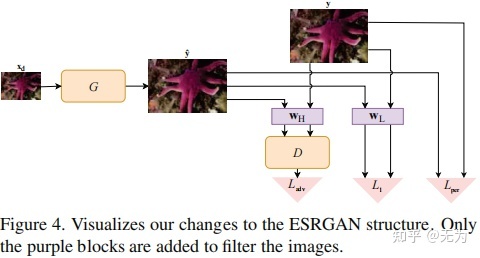
对于图像的低频信息,作者的描述是,对于一幅低分辨图像和生成的高分辨图像在低频信息方面有一一对应的关系,因此,可以采用像素级别的损失(即作者所提到的颜色损失)来计算SR和HR之间的差异。
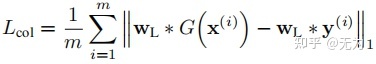
而对于图像的高频部分,低分辨图像和生成的高分辨图像并不具有一一对应的关系,多幅图像可以具有同样的高频信息,因此用对抗损失来计算SR和HR之间的高频信息差异。最终,用感知损失来计算图像整体的差异,整体损失如下:
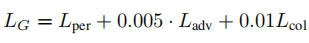
[√] 实验中的几个关键点:
- 作者采用了两种制作数据集的方法。SDSR制作时,源域和目标域相同;TDSR制作时,需要先对源域进行x2倍降采样以清除噪声;
- 加入人工噪声(高斯、JPEG)。
- 引入了LPIPS。
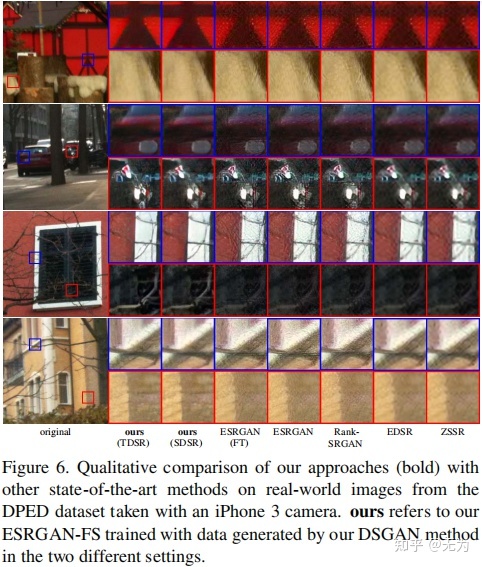
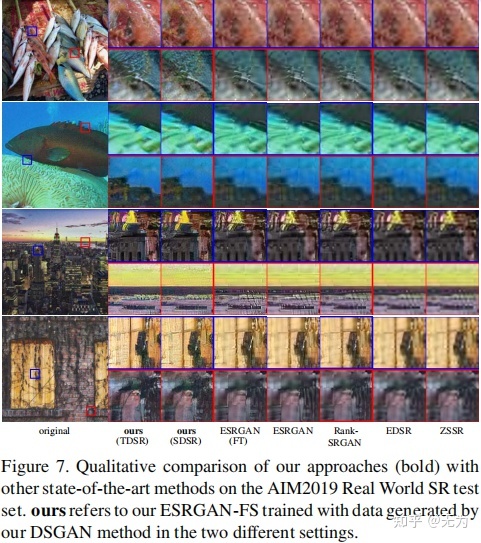
[√] 结果图: