038 - 文章阅读笔记:(CVPR 2022 阅读笔记)Residual Local Feature Network for Efficient Super-Resolution - CSDN - 专栏:单图像超分辨 - 南妮儿
本文最后更新于:3 个月前
转载自:
于 2022-06-29 22:06:08 发布
[√] 论文信息
论文地址:Residual Local Feature Network for Efficient Super-Resolution
摘要:目前高效SISR主要关注减少参数的数量,它们通过复杂的连接来聚合更多的特征。这些结构不适合在资源有限的平台上部署。基于此,作者提出了新的残差局部特征网络(RLFN)。这个思想主要是使用三个卷积层去聚合局部的特征,这个操作在模型性能和效率方面做到了平衡。作者重现了对抗损失,发现特征提取器提取的中间特征对最后结构影响很大。此外,作者提出了新的多阶段热启动训练策略。在每一个阶段,前一阶段的预训练模型被利用提高模型的性能。结合改进的对抗损失和训练策略,提出的RLFN模型胜于其他模型。
[√] 引言
作者说大多数的SR先进方法需要相当多计算时间,这很难引用到现实生活中,因此,设计一个轻量级的模型是至关重要的。
关于设计轻量级模型的工作已经有很多人做过了。但是其中大部分方法都是倾向于减少模型的参数量。比如说共享参数策略的递归神经网络。但是这种方法没有减少操作的数量和推理时间。为了减少模型的推理时间,使用深度可分离卷积,特征分离和打乱这样策略是必要的。
为此,作者复现优秀SR方法RFDN,并且尝试改进,获得更好的重建质量和推理时间。首先,作者重新思考了RFDN残差特征蒸馏网络模块中几个组件的有效性。作者发现尽管特征蒸馏模块极大的减少了参数量,但是这个模块对硬件很不好并且限制了模型的推理速度。为了改进这,作者提出了新的残差局部特征网络。为了进一步提高模型的性能,作者利用了对抗损失。
作者发现,特征提取器中间特征的选取对模型的性能影响很大。作者做了对中间特征进行全面的研究得出结论从浅层提取的特征有更好的细节和纹理。基于这,作者改进了特征提取器,这可以有效的提取边缘和细节。为了加速模型的收敛,作者提出了多阶段热启动策略。具体来说,就是在每个阶段,SR模型可以得到所有前面阶段的预训练权重。
结合改进的对抗损失和新的训练策略,模型得到了很好的性能并且保持很好的推理速度。

上图介绍了作者了主要贡献。作者是在RFDN的基础上提出了新的网络结构。首先作者思考了RFDN各个模块的有效性。作者提出了RLFN。作者为了使模型的性能更好,作者分析了对抗损失的特征提取器中间特征对模型的影响,得出结论浅层特征更好对于PSNR。作者提出了新的训练策略。
总的来说,作者在别人的基础上改进了网络结构,提出了新的损失函数,提出了一种新的训练策略。
[√] 相关工作
在资源有限的设备上实现实时超分有着巨大的商业价值。
SRCNN是第一个将深度学习应用到SR领域。它有三层网络,使用双三次插值上采样,但是这样增加了网络的计算。为了解决这,FSRCNN在模型的最后使用反卷积。
DRCN通过引入深度递归网络去减少模型的参数量
LapSRN通过提出拉普拉斯超分模块去重建HR图像的。
CARN通过组卷积提出了级联残差网络。
IMDN通过构建信息级联蒸馏网络
RFDN微调了IMDN。
上面这些方法倾向于使用各种不同的内部连接技术,但是这影响了推理速度。这篇文章作者通过简单的网络结构增强训练策略在性能和速度上达到了一个平衡。

上面介绍了模型的性能受三个方面的影响:结构,数据,优化策略。以前的工作大多关注于模型的结构,忽视了优化策略的影响。最近,一些其他方面的研究证明了用先进的训练策略去训练一个旧的网络可能会有更好的效果。
[√] 方法
作者在这一部分主要介绍了模型的网络结构,改进的对抗损失,新的训练策略。
网络结构
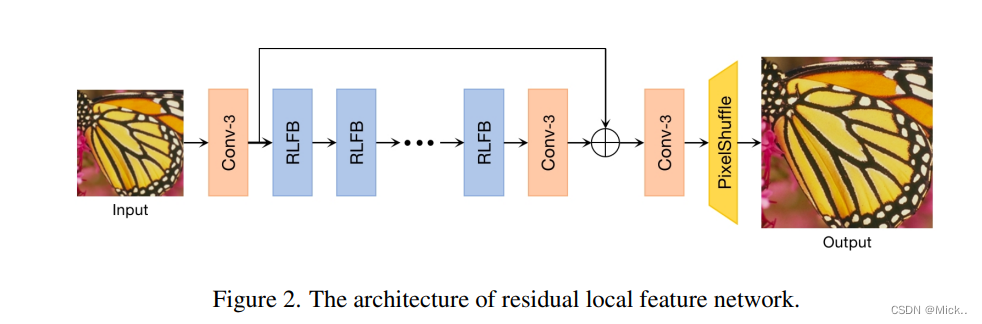
模型结构主要有三部分组成:特征提取,多个堆叠的残差局部特征模块,重建模块
特征提取作者用一个3*3的卷积去提取粗特征。
alec:
- denote,表示、指示
- coarse、粗略的、粗糙的

上图介绍了各个结构
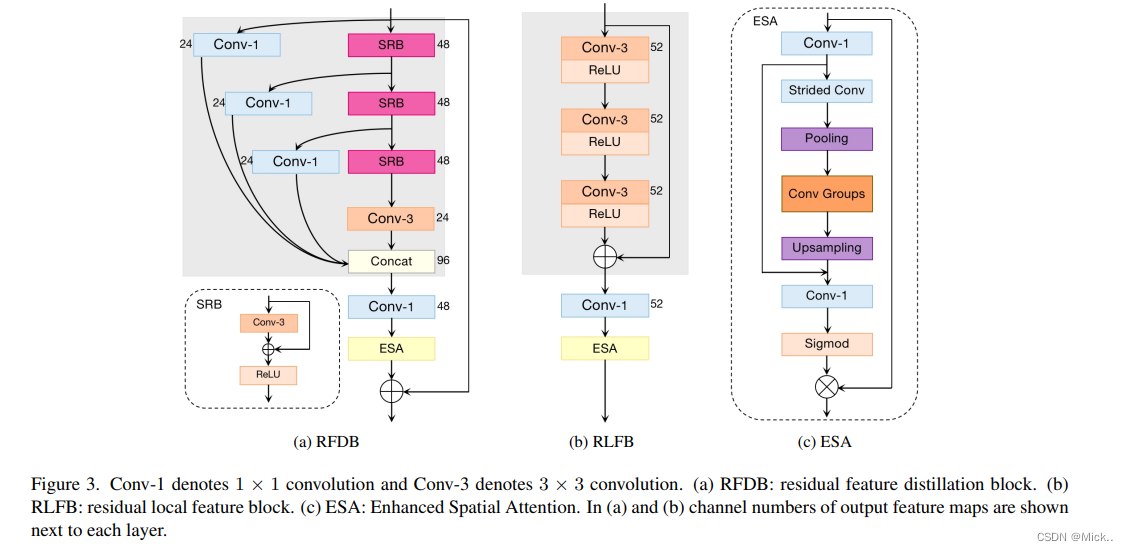
alec:
- ESA = enhanced spatial attention,增强的空间注意力
- 蒸馏之后,使用空间注意力模块来整理空间信息

alec:
- RFDB中1x1的卷积是用于蒸馏特征的
- SRB分支是用于优化特征的,称为RM;1x1卷积分支是用于蒸馏特征的,称为DM
- 蒸馏分支出来的保留、最后合并;优化分支出来的,逐层的往后传
上面主要介绍了RFDN中的RFDB模块。作者在这个基础上重新设计了两种新的RFDB。

alec:
- 模型轻量化:将之前的一个模型中的模块,改简单、但是效果不失。将蒸馏模块去除,换成一个简单的模块。
作者通过去除了部分连接改进了RFDB模块,然后又分析了ESA模块的冗余性。
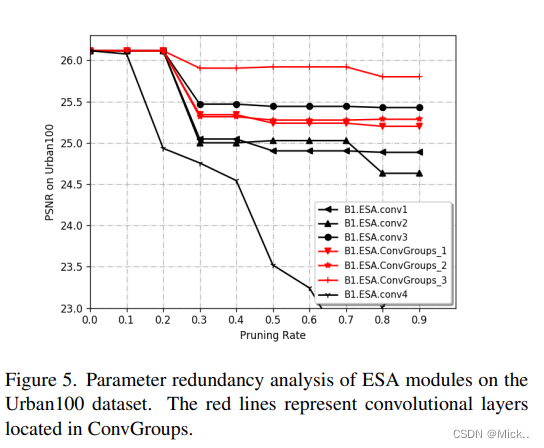
这里没有看懂。这里作者通过one-shot structured pruning算法分析了ESA模块的冗余性。
[√] 重新思考对比损失

alec:
- 实验中发现,当使用了对比损失之后,效果下降了。
上面介绍了对抗损失的定义。对抗损失是为了使正样本更加靠近参照物,负样本更加远离参照物。

alec:
- 模型的深层提取的特征主要是语义信息,而浅层提取的特征主要是纹理细节。
- 来自于深层的特征能够提升真实的感知质量,因为这个深层特征能够提供语义引导。
- 来自于浅层的特征能够提高以PSNR指标为中心的模型。
- 因此我们应该充分利用浅层特征去提高模型的PSNR指标。
作者在这一部分提出,深层提取的特征更加抽象,但是缺少具体细节。比如说,在第一层提取的特征边缘和纹理更加清晰。深层则不一样。

作者在这一部分提出了改进对抗损失的原因。因为原始的对抗损失是比较在ReLU激活函数之后的特征,作者认为这将导致信息的丢失。因为ReLU激活之后将导致特征稀疏,所以作者使用tanh激活函数代替。作者在这里说,一个好的网络结构随机初始化后也可以提取足够的感知细节。
alec:
- 之前的改进是将使用激活函数之后的特征图改为使用激活函数之前的特征图
- 此处则是将激活函数ReLU替换为激活函数tanh,因为激活函数ReLU的输出是稀疏的,而激活函数tanh的输出是紧凑的
[√] 热启动策略
对于大尺度因子的SR任务,通常使用2倍尺度因子作为预训练模型。预训练模型提供好的初始化权重,可以加速模型的收敛。但是,作者认为预训练的模型和目标模型的尺度因子是不一样的。
为了解决这一问题,作者提出了新的多阶段的热启动训练策略,这可以根据经验提高模型的性能。
[√] 实验部分


alec:
- 随机的裁剪256x256的图像。
- 训练过程有三步,第三步中使用了对比损失。
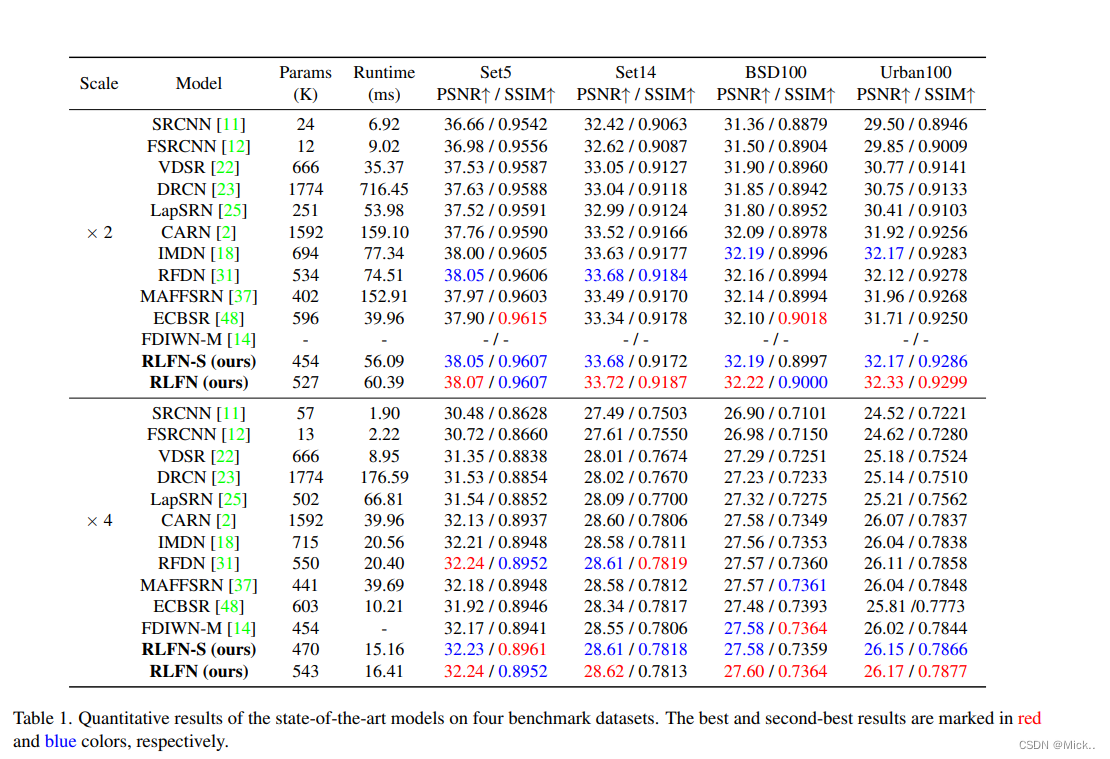
后面实验部分没具体看
作者在别人的网络进行改进提出新的网络结构。提出了改进的对抗损失。训练策略没怎么看懂。