058 - 文章阅读笔记:ICCV2021-【FBCNN】超灵活且强度可控的盲压缩伪影移除新思路 - 微信公众号 - AIWalker
本文最后更新于:3 个月前
原文链接:
ICCV2021 FBCNN: 超灵活且强度可控的盲压缩伪影移除新思路 - 微信公众号 - AIWalker
2021-09-23 22:15
ps:本文为依据个人日常阅读习惯,在原文的基础上记录阅读进度、记录个人想法和收获所写,关于原文一切内容的著作权全部归原作者所有。
[√] 文章信息
因为最近一年甚少看到图像压缩伪影移除相关的paper,就下意识的以为该问题已经解决了,基本上现有方案完全可以商用。
到上次看到BSRGAN与Real-ESRGAN后也曾想到过二次JPEG压缩问题,但下意识的认为跟一次压缩没太大区别,真的从来没有想到二次JPEG压缩之间的非对齐现象。
本文又是ETH团队在low-level方面的工作,同样也被ICCV2021接收。
本文对JPEG压缩伪影问题进行了探索,尤其是针对真实场景中的非对齐二次JPEG压缩问题进行分析。
从现有方案的不灵活性、对非对齐二次JPEG压缩的失效等问题入手,提出了一种更为灵活、支持交互的盲压缩伪影移除方案。
与此同时,作者还提出了一种新的退化模型(很有BSRGAN的味道)以生成非对齐二次JPEG压缩伪影训练数据。

ICCV2021:https://github.com/jiaxi-jiang/FBCNN/releases/download/v1.0/FBCNN_ICCV2021.pdf
code:https://github.com/jiaxi-jiang/FBCNN
[√] Abstract
因其方便实用,单模型处理不同质量的JPEG压缩伪影移除已受到了广泛关注。然而,现有盲方案往往直接进行重建而未考虑质量因子,因此会像非盲方案一样缺乏灵活性。
为缓解上述问题,本文提出了FBCNN(Flexible Blilnd Convolutional Neural Network, FBCNN),它预测质量因子并控制伪影移除与细节保留之间的均衡。具体来说,FBCNN通过decoupler模块将质量因子从JPEG图像中解耦合,然后将预测的质量因子通过质量因子注意力模块嵌入到后续重建模块中以进行更灵活的控制。此外,我们发现:现有方案在非对齐(哪怕仅存在一个像素偏差)二次JPEG压缩图像上会失效 。为此,我们提出了一种二次JPEG退化模型进行训练数据增强。
实验结果表明:在JPEG图像、更广义的二次压缩JPEG图像以及真实JPEG图像上,无论是定量还是定性评价,所提方案均优于已有方案 。
[√] 背景说明
因其简单性与快速编解码速度,JPEG是一种常见的图像压缩方案,它将图像拆分为8x8非重叠图像块,然后对每个图像块执行DCT变换,所得DCT系数通过量化表进行量化。量化表中的元素控制了压缩比例,系数的量化会导致了信息损失,也是整个过程仅有的有损操作。量化表通常由QF表示,越低表示信息损失越多。
现有JPEG压缩伪影移除存在以下四点局限性:
- 现有DNN方案往往对每个QF训练一个模型,缺乏灵活性;
- 基于DCT的方案需要事先获得DCT系数或者量化表,而这些信息仅见诸于JPEG格式;此外,当图像进行多次压缩时,只有最近一次的压缩信息得以保留;
- 为解决第一个问题,近期一些方案对大范围QF训练一个模型,然而这些方案仅能提供确定性重建结果,而忽视了用户偏好;
- 现有方案大多基于合成数据训练,且仅压缩一次;而实际中的图像往往压缩多次。
二次图像压缩(double JPEG Compression)在图像取证领域已被研究很长时间,二次压缩检测可以为图像复原提供重要信息。已有盲方案在面对二次压缩图像时往往失效。
[√] Method
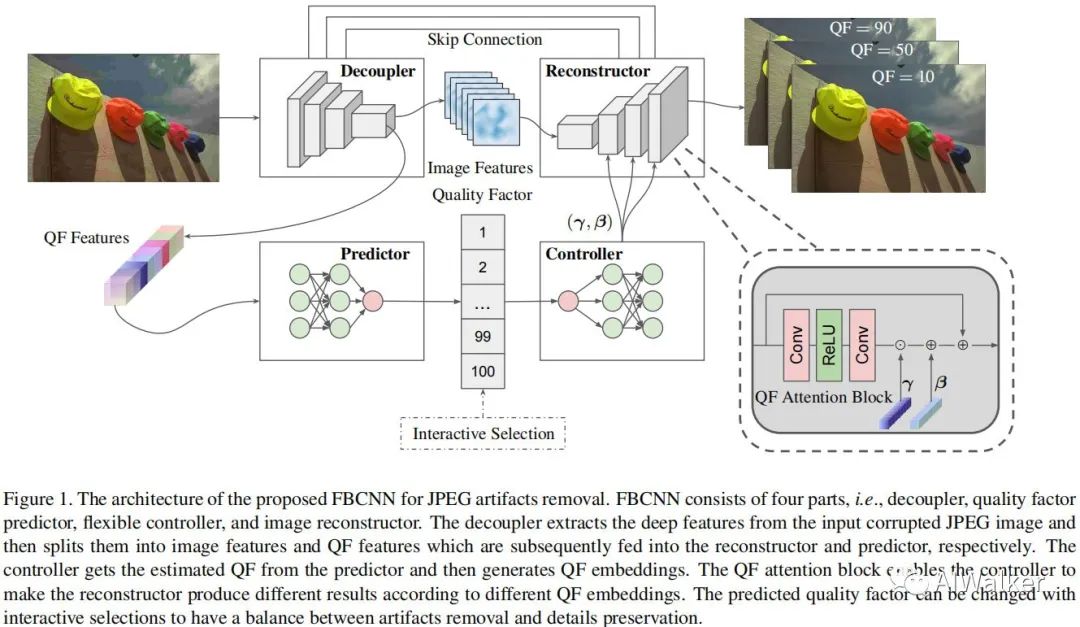
上图给出了所提方案整体架构示意图,它以JPEG图像作为输入,直接生成重建图像。具体来说,FBCNN包含以下四个模块:
decoupler:该模块旨在从输入图像中提取深层特征并解耦隐含质量因子。它包含四个尺度,每个尺度均提供一个跳过连接到重建模块。每个尺度的通道数分别为64、128、256以及512.
QF predictor:该模块是一个3层MLP,它以512维QF特征作为输入,并输出所估计的质量因子。在训练过程中,由于块尺寸较小可能导致估计的质量因子不够精确,进而导致训练不稳定。因此,我们引入了损失进行监督
flexible controller:该模块是一个4层MLP,它以质量因子作为输入,体现了目标图像的压缩度。该模块旨在根据给定质量因子学习一种嵌入信息并融合到重建中以提供更灵活的控制。整体思想类似于SFT,最近看到了好几篇paper都提到了SFT层 。
image reconstructor:图像重建模块包含三个尺度,它接收来自decoupler与嵌入信息
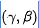 以生成干净图像。QF注意力模块是重建模块的重要成分。每个尺度的QF注意力模块数设置为4,所学习超参数对
以生成干净图像。QF注意力模块是重建模块的重要成分。每个尺度的QF注意力模块数设置为4,所学习超参数对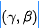 能够通过SFT自适应影响输出。处理过程可以描述如下(注:SFT一般被用于ResBlock的残差分支):
能够通过SFT自适应影响输出。处理过程可以描述如下(注:SFT一般被用于ResBlock的残差分支):
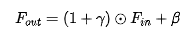
看到这里,不得不提一下:SFT真乃神器也 !最近在多篇非常赞的文章中看到其身影,比如IKC、MANet、DAN、CResMD以及本文。SFT最早见诸于XinTao大佬的SFTGAN,原文是这样描述:SFT基于某些先验条件学习一对调制参数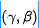
,所学习的参数对通过对特征执行仿射变换达到自适应调整输出的目的 ,该过程描述如下: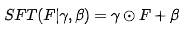
图像重建部分的损失同样采用了L1损失,定义如下:
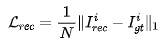
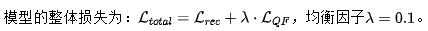
alec:
- QF = quality factory = 质量因子 = 在网络中提取出来的图像隐含质量因子
- 新名词:SFT层
- SFT一般被用于ResBlock的残差分支
[√] Restoration of Double JPEG Images
Limitations of existing methods : 尽管某些现有方法声称能够重建JPEG压缩图像,但关于二次JPEG压缩复原的研究尚未得到深入研究。我们发现:现有盲方法在面对二次不对齐JPEG压缩且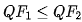 时会失效,哪怕只有一个像素偏移 。
时会失效,哪怕只有一个像素偏移 。


[√] Experiments
关于训练数据制作,作者采用MATLAB的JPEG编码器进行数据制作,训练数据为DIV2K与Flickr2K,图像压缩质量因子从10-95之间随机采样。
[√] Single JPEG Image Restoration
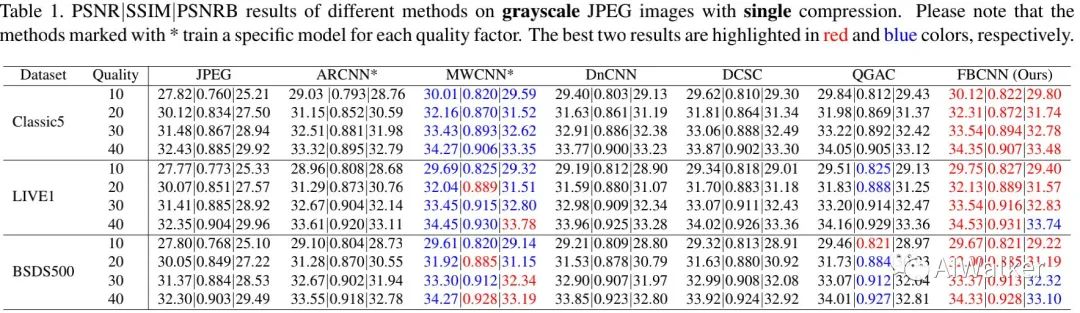
上表给出了灰度图像一次压缩任务上的性能对比,从中可以看到:所提方案显著优于其他盲方案 ,如DnCNN与QGAC,同时适度优于MWCNN(针对特定质量因子训练)。
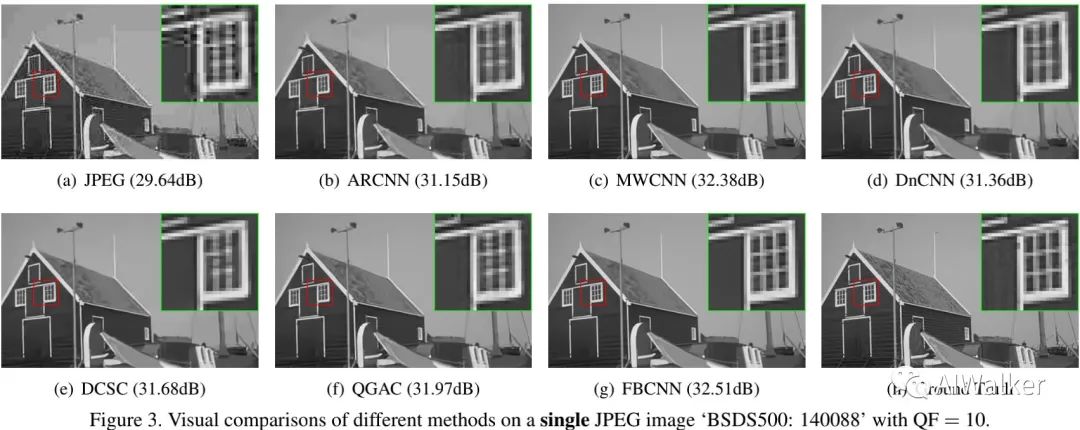
上图给出了可视化效果图,可以看到:所提方案复现效果更自然友好。
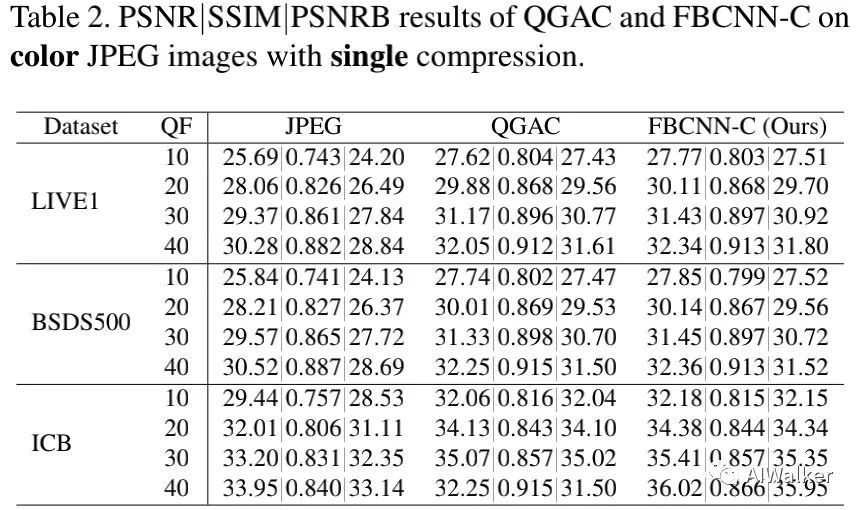
上表给出了彩色图像一次压缩任务上的性能对比,从中可以看到:所提方案显著优于QGAC 。

上图可视化了FBCNN的灵活性,可以看到:通过设置不同的质量因子,可以得到不同感知质量结果 。也就是说,用户可以通过交互方式按照个人偏好进行压缩图像复原。