016 - 文章阅读笔记:一文带你入门超分辨率网络 - CSDN - 只会写bug的菜鸡
本文最后更新于:3 个月前
链接:
一文带你入门超分辨率网络 - CSDN - 只会写bug的菜鸡(√)
2021-07-06 19:43:06
[√] 常见降采样操作
最常见的降采样操作是双三次插值
[√] 数据集
[√] 通用图像数据集
BSDS300、BSDS500、DIV2K、General-100、L20、Manage109、 OutdoorScene、PIRM、Set5、Set14、T91、Urban00
[√] 人脸图像数据集
CelebA、Helen、CelebMask-HQ
[√] 常见的损失函数
[√] 逐像素损失
[√] 内容损失
希望生成的图片从视觉上看更像是真实的图片
content loss代表2副图像高维特征之间的欧氏距离。它把分类网络引入超分中,不再关注oixel之间的匹配,而是使生成的图片从视觉上看更像是真实的图片。
[√] 纹理损失
希望重构的图片与原图有相同的风格
Gram矩阵来衡量纹理相似性
[√] 全变分损失
望生成的图片更平滑
[√] 对抗损失
希望重构的图片与原图有相同的风格
[√] 常见的网络架构设计
[√] 残差学习
[√] 全局残差学习
只学习两幅图像的残差,这样就避免了学习完整图像到另一个完整图像之间复杂的变换,简化了任务难度。神经网络只需要学习丢失的高频细节信息即可
[√] 局部残差学习
理论:
是ResNet网络的技巧,提出的目的是为了解决网络的梯度消失、梯度爆炸的问题,增强网络的学习能力。主要由skip-connnection和逐像素加法进行计算,前者连接输入与输出,后者在不同网络层之间进行连接
模型:
SRGAN、RCAN
[√] 递归学习
[√] 目的
- 减少网络的参数量
- 实现更大的感受野
[√] 实现方法
将递归引入模型,多次使用相同权重的模块,这些模块之间是参数共享的
[√] 模型
DRCN、MEMNet、CARN、DSRN
[√] 优缺点
递归学习在不引入额外参数的情况下学习到更先进的表示,但并没有带来计算量的减少,同时也带来了梯度消失和梯度爆炸的问题。因此通常将残差学习和递归学习结合来缓解这些问题。
[√] 注意力机制
[√] 理论
考虑到不同通道和不同空间位置之间特征的相互依赖关系来提高网络的学习能力
[√] 模型
Squeeze-and-Excitation Networks
Image Super-Resolution Using Very Deep Residual Channel Attention Networks
Second-Order Attention Network for Single Image Super-Resolution
Image Super-Resolution With Cross-Scale Non-Local Attention and Exhaustive SelfExemplars Mining
[√] 密集连接、稠密连接
[√] 目的
密集连接有助于缓解梯度消失、增强信号传播和鼓励特征重用。通过采用小增长率(growth rate,即密集块中的信道数)和在级联所有输入特征映射后对channel number进行压缩来极大程度地减少模型的大小。
[√] 理论
对于稠密块体中的每一层,将所有前一层的特征图作为输入,并将其自身的特征图作为输入传递到所有后续层
[√] 模型
Residual Dense Network for Image Super Resolution
SRDenseNet:Image Super-Resolution Using Dense Skip Connections
[√] 优点
稠密连接不仅有助于减轻梯度消失、增强信号传播和鼓励特征重用,而且还通过采用小增长率(即密集块中的信道数)和在连接所有输入特征映射后压缩通道数来显著减小模型尺寸
[√] 多路径学习
[√] 理论
指通过多条路径传递特征,每条路径执行不同的操作,将他们的操作结果融合以提供更好的建模能力
[√] 分类
全局多路径学习
理论:利用多个路径提取图像不同方面的特征。这些路径在传播过程中可以相互交叉,从而大大提高了特征提取的能力。
模型:LapSRN、DSPN
局部多路径学习
理论:对输入进行不同路径的特征提取后进行融合,具体就是采用了一种新的多尺度特征提取块,采用核大小为3×3和5×5的两个卷积运算同时提取特征,然后将输出拼接起来,再次进行相同的运算,最后再进行一个额外的1×卷积。
模型:CSNLN、MSRN
尺度明确的多路径学习
理论:在网络的开始端和结束端分别附加特定尺度的预处理路径和上采样路径。训练时,只启用和更新所选比例对应的路径。通过这种方式,大多数参数可以在不同的尺度上共享。
模型:MDSR、CARN、ProSR
[√] 增强卷积
空洞卷积:增大感受野、有助于生成逼真的细节
分组卷积:降低参数量
深度分离卷积
[√] 金字塔池化
Pyramid的思路就是把不同size的feature concat?在一起。对于尺寸是HxWxc的feature map,每个channel被划分成MxM块并通过GAP全局池化,生成MxMxC的结果。再通过1X卷积把输出压缩为single channel。之后,再经过双线性插值把结果进行上采样到原来feature map的维度。当M变化时,模块结合全局和局部的上下文信息以提升性能。
[√] 操作通道
RGB
YCbCr
[√] 常见的上采样方法
[√] 传统插值方法
[√] 最近邻插值
每个待插值的位置选择最相邻的像素值,而不考虑其他像素
[√] 双线性插值
首先对图像的一个轴进行线性插值,然后在另一轴上执行。通过周围最近的4个点求出目标点的像素值
[√] 双三次插值
首先对图像的一个轴进行三次插值,然后在另一轴上执行,通过最近的16个像素值求出目标点的像素值。
[√] 可学习的上采样方法
[√] 反卷积
理论:为了克服基于插值方法的缺点,端到端地学习上采样,在SR领域引入了转置卷积层。先对低分辨率图像插入0值,再通过卷积(kernel=:3,stride=l,padding=l)的过程获得输出。
缺点:很容易在每个轴上引起“不均匀重叠“,并且两个轴上的相乘结果进一步创建了大小变化的棋盘状图案,从而损害了SR性能。
[√] 亚像素卷积
理论:核心思想是通过卷积操作产生大量的channel之后,再通过reshape得到最终的输出。比如说要上采样s倍,那么就需要得到sxs个不同的channel。,设输入的维度是hxwxc,则输出的维度是hxwxs.2:接下来进行一步reshapingl的操作(比如shuffle)把特征最终变为:shxswxc
优点:与转置卷积层相比,亚像素层具有更大的感受野,它提供了更多的上下文信息以帮助生成更多逼真的细节。
缺点:然而,由于感受野的分布是不均匀的,并且块状区域实际上共享相同的感受野,因此可能会导致在不同块的边界附近出现一些伪影,也可能会导致不平滑的输出结果。
[√] Meta upscale module
这些可学习的上采样方法已成为应用最广泛的上采样方法。特别是在Post-upsampling Super–resolution框架中,这些图层通常用于最终上采样阶段,基于低维空间提取的高层表示重建HR图像,从而在避免高维空间的巨大的计算量的情况下,实现端到端的SR。
[√] 超分网络的四种框架
[√] Pre-upsampling Super-resolution

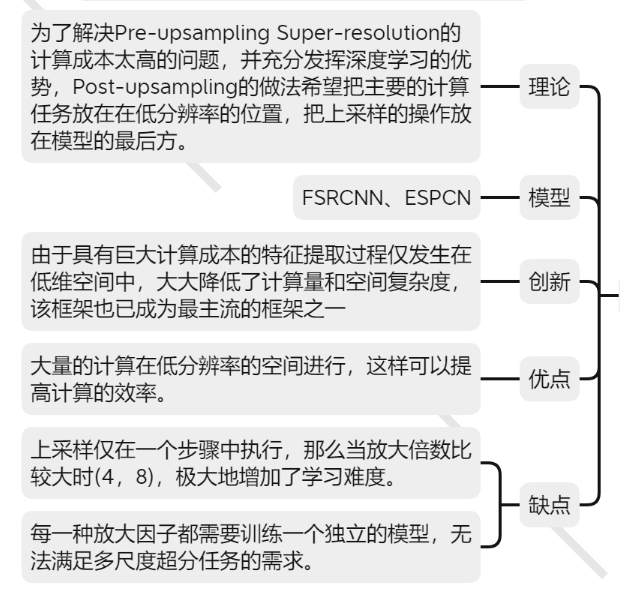
[√] Post-upsampling Super-resolution
[√] 渐进式上采样超分辨

[√] 上下采样迭代超分辨

[√] 质量评估方法
