009 - 文章阅读笔记:图像超分辨率:IPT学习笔记 - 知乎 - 桃川京夏
本文最后更新于:3 个月前
链接:
编辑于 2022-09-02 20:28
论文名称:Pre-Trained Image Processing Transformer(CVPR 2021,IPT)
论文链接:
[√] 一、Introduction
[√] 1 Motivation:
图像超分辨率、图像修复、去雨等图像处理任务(image processing tasks)都是相关的,因此本文希望提出一个预训练模型能够处理多个任务。目前,在NLP和CV领域中预训练模型已经非常普遍。其中,基于Transformer的预训练模型先在一个大数据集上做训练,再在特定任务的小数据集上finetune,取得了很好的效果。
alec:
- 预训练模型,即现在大的数据集上做预训练,然后再针对特定任务的小数据集微调,会取得比较好的效果。(预训练的目的在于给模型初始化一个很好的起点参数,从而让模型更有效的收敛到好的局部最优点)
但是,NLP和CV领域中的预训练模型大多研究单一的先验分类任务,而图像处理任务的输入和输出都是图片,因此现有的预训练策略无法直接应用;如何在预训练阶段有效兼容不同目标的任务仍然是一个挑战
[√] 2 Challenge:
预训练模型面对的难点:
1)特定任务的数据集很有限,这一难点在涉及付费数据或者隐私数据的图像处理任务中加剧。相机参数,光照,天气等大量变化因素会进一步影响数据的分布;
2)在测试图像出来之前,不知道会是哪种类型的图像处理任务。
[√] 3 Contribution:
1)提出了一个使用Transformer架构的图像处理预训练模型(IPT),该模型由多对head和tail,以及共享的body组成,适用于不同的图像处理任务,包括超分辨率、去噪、去雨;
alec:
- 整个模型分为head、body、tail组成,head用于浅层特征的推理、body用于深层特征的非线性推理、tail用于图像的上采样重建。
- head、tail根据特定的任务灵活替换,这些任务可以共享body的参数。
2)Transformer需要大规模数据集进行训练,因此本文选择ImageNet来训练IPT模型。对不同的任务采用不同的操作来生成多个图片对,整个训练集包括超过一千万张图片;
3)在训练过程中,图片输入特定的head,生成的特征crop成patches并flatten,通过body来处理flattened features,tail再根据不同的任务预测不同输出大小的原始图片;
4)此外,为了适应不同的图像处理任务,提出了一种基于不同输入图像的patches之间关系的对比损失(contrastive loss)。
[√] 二、原理分析
[√] 1 IPT architecture
整个IPT模型如下图所示,可以分为4个部分:Heads、Transformer encoder、Transformer decoder、Tails。Heads用于初步提取输入的退化图片的特征,encoder-decoder transformer用于恢复丢失的信息,Tails用于将特征映射为原始图片。
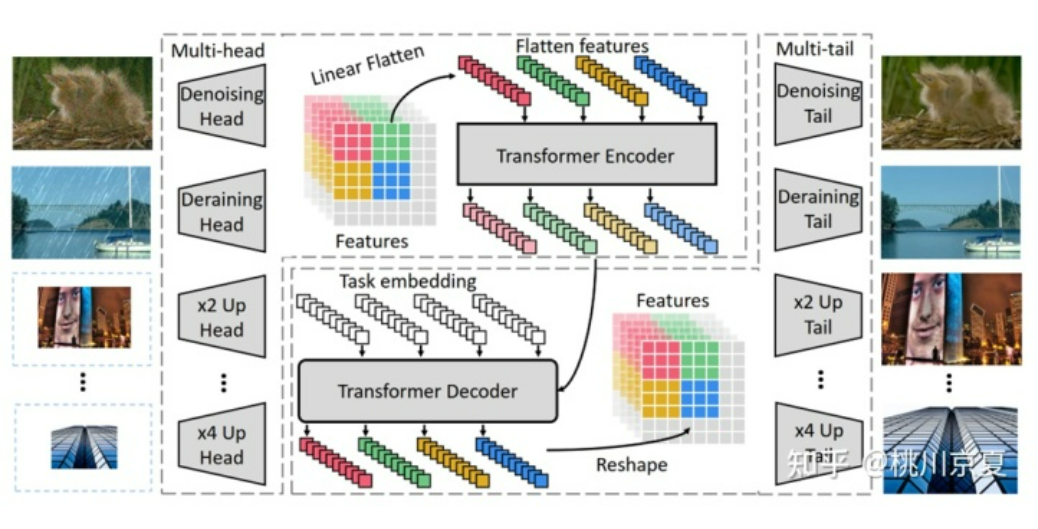
[√] 1)Heads
采用多个heads分别处理不同的任务,每个head由三个卷积层组成。输出特征的大小(H、W)不变,通道数C增加至64;
[√] 2)Transformer encoder
将输入大小为H×W×C的特征split为N×(P2·C),其中N=H×W/P2,P为patch size。和Transformer一样加入了位置编码,给每一个输入的patch引入一个位置编码position encodings,和原版Transformer的sincos编码不同,这里的位置编码是可学习的。
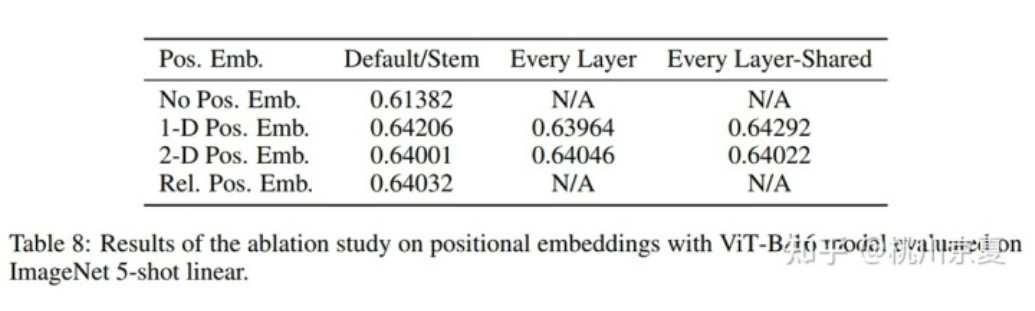
*ViT中对不同的位置编码、不同的添加方式做了消融实验,结果如下表所示。位置编码这一策略显然是有效的,但1D位置编码、2D位置编码、相对位置编码得到的结果比较相近,可以认为1D位置编码已经可以充分学到位置信息。
整个encoder layer的计算过程和原版的Transformer一致,由多头自注意力机制multi-head self-attention module和前向网络feed forward network构成,具体如式(1)所示。在式(1)中,第一个式子表示添加位置编码;第二个式子表示Query、Key、Value的计算过程;第三个式子表示multi-head self-attention以及add and norm;第四个式子表示feed forward network以及add and norm,整个过程重复L次。最终输出的向量维度和输入一致。

[√] 3)Transformer decoder
同样采用了原版Transformer的decoder,包含两个multi-head self-attention module和一个feed forward network,和原版Transformer的不同之处在于本文采用了一个task-specific embedding作为decoder的额外输入,该向量的维度为P2×C,用于解码不同的图像处理任务。整个计算过程如式(2)所示。其中,第一个式子表示Transformer encoder的输出;第二个式子表示第1个multi-head self-attention的Query、Key、Value的计算过程,task-specific embedding仅作用于Query和Key;第三个式子表示第1个multi-head self-attention以及add and norm;第四个式子表示第2个multi-head self-attention的Query、Key、Value的计算过程,task-specific embedding仅作用于Query;第五个式子表示第2个multi-head self-attention以及add and norm;第六个式子表示feed forward network以及add and norm,整个过程重复L次。输出维度的大小和输入一致,为N×(P2·C)。最后再reshape为H×W×C。

[√] 4)Tails
和输入heads对应,采用多个tails分别处理不同的任务。将Transformer decoder输出的H×W×C的特征映射为H’×W’×C,H’×W’由具体任务决定,比如在2×超分辨率任务中,tail使用sub-pixel convolution layer,H’=2H,W’=2W。
[√] 2 Pre-training on ImageNet
除了模型本身,成功训练一个transformer模型的关键因素是对大规模数据集的使用。与图像分类任务相比,用于图像处理任务的可用数据相对较少(例如,用于图像超分辨率的DIV2K数据集只有2000幅图像)。因此,本文作者建议利用众所周知的ImageNet作为基线数据集来预训练IPT模型。
alec:
- 因为特定任务的数据集量较小,不足以充分的训练transformer模型,因此现在ImageNet这个基线数据集上预训练IPT模型,然后再在特定任务的数据集比如DIV2K上进行训练。
首先去除语义标签,然后从这些未标记的图像中手动合成各种不同的退化图像,用于不同的任务,退化图片由式(3)计算得到,针对不同的任务采用不同的退化操作:对于超分辨率任务,fsr是bicubic interpolation;对于图像去噪任务,fnoise(I)=I+η,式中η是高斯噪声;对于去雨任务,frain(I)=I+r,式中r是人工添加的雨线。

IPT的损失函数如式(4)所示。从式(4)可以看出,所提出的框架同时接受多个图像处理任务的训练。对每个batch,从Nt个监督任务中随机选择一个任务进行训练,每个任务将同时使用该任务所对应的head、tail和task embedding进行处理。

最后,作者引入了对比学习(contrastive learning)来学习通用特征,从而提高模型的泛化性能。作者的目标是最小化来自相同图像的patches features(P2×C)之间的距离,同时最大化来自不同图像的patches features之间的距离。对比学习的损失函数公式如下:
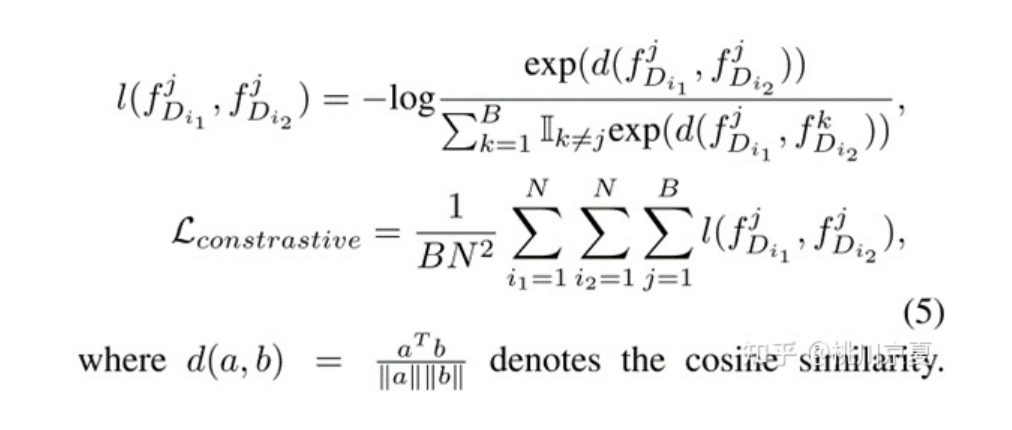
最终的损失函数如公式(6)所示,其中λ用于平衡contrastive loss和supervised loss。

[√] 三、实验结果
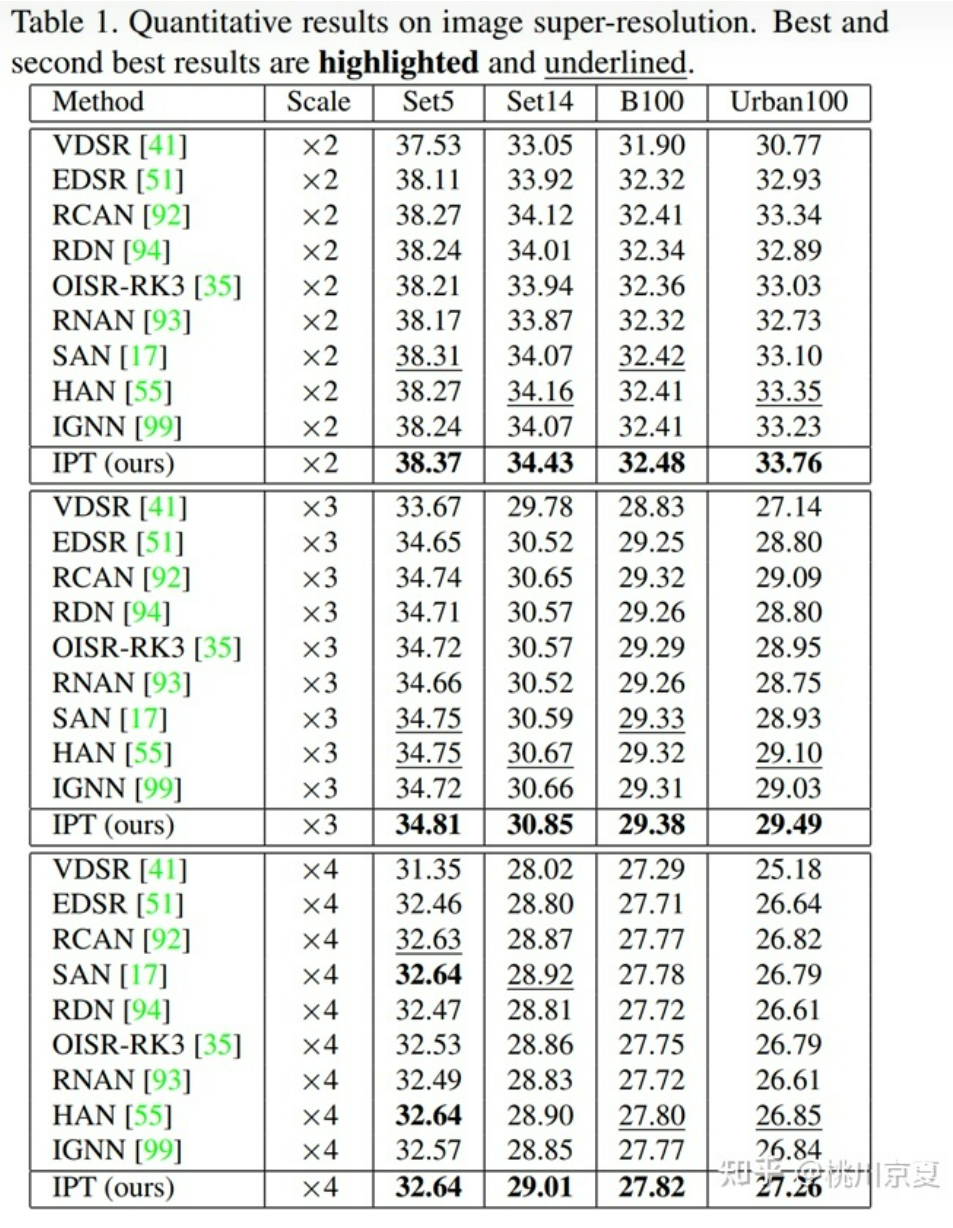
部分实验结果如下所示(仅选取了图像超分辨率相关的实验结果)。作者对比了目前精度最高的CNN模型,数据集有Set5、Set14、BSD100、Urban100,超分类型×2,×3,×4,IPT取得了SOTA。实验结果表明,在使用大规模数据集解决图像处理问题时,基于Transformer的模型比基于CNN的模型具有更好的性能。
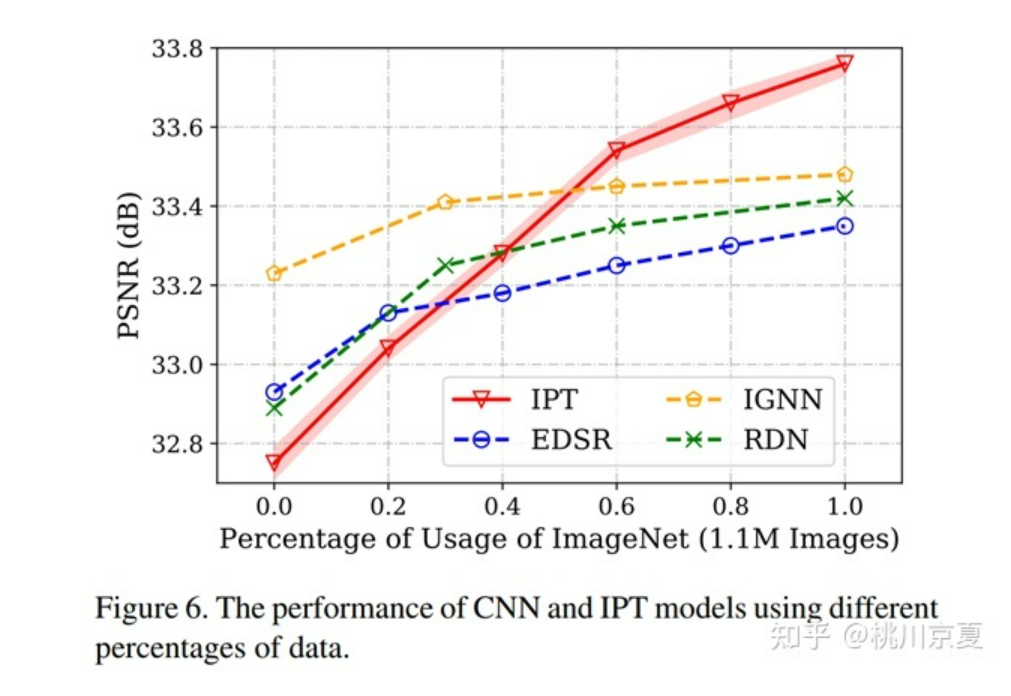
作者在消融实验中对比了数据集对模型的影响,在不同比例的ImageNet上训练CNN模型,包括EDSR、IGNN、RDN,分别将数据集的比例控制为20%、40%、60%、80%、100%。结果显示,当数据量较小时,CNN预训练模型性能优于IPT;当数据量增加至60%以上时,IPT取得了更好的性能。
alec:
- 对比于CNN,transformer模型,数据量越多,性能越好。
[√] 四、小结
ViT把Transformer原汁原味地搬到了视觉领域,IPT则是仿照ViT,把Transformer原汁原味地运用到了图像处理任务中。IPT模型遵循目前超分网络的通用结构,即head、body、tail的形式,主要改进则是将这一结构中原本用的CNN的body改为Transformer。
作者认为图像处理任务中的预训练模型有两个难点:1、特定任务的数据集很有限;2、在测试图像出来之前,不知道会是哪种类型的图像处理任务。实际上两个难点都不算真正的难点。难点1实际上源于Transformer自身,想要实现全局注意力自然会导致模型较大、训练困难,也就显得数据集有限。在SwinIR中可以看到当模型大小减下来之后,只用DIV2K数据集训练也能得到不错的效果,不过也好的很有限。
难点2则是因为作者想要用IPT模型兼容多个图像处理任务,这也就引出了作者在模型结构上的主要创新点:针对不同任务的multi-head、multi-tail、task-specific embedding以及contrastive learning。这也意味着需要针对不同的任务制作不同的数据集,在一定程度上也能缓解难点1。