022 - 文章阅读笔记:【图像超分辨率重建】——RCAN论文精读笔记 - CSDN - 图像超分辨率重建论文精读 - Zency_SUN
本文最后更新于:3 个月前
转载自:
【图像超分辨率重建】——RCAN论文精读笔记 - CSDN - 图像超分辨率重建论文精读 - Zency_SUN(√)
于 2022-10-31 09:11:48
论文标题:Image Super-Resolution Using Very Deep Residual Channel Attention Networks(RCAN)
刊物和时间:ECCV 2018
论文作者:Yulun Zhang, Kunpeng Li, KaiLi, Lichen Wang, BinengZhong, and Yun Fu
论文摘要:
卷积神经网络(CNN)的深度对于图像超级分辨率(SR)来说是至关重要的。
然而,我们观察到,用于图像超分辨率的深度网络更难训练。
低分辨率的输入和特征包含丰富的低频信息,这些信息在不同的通道上被同等对待,因此阻碍了CNN的表示能力。
为了解决这些问题,我们提出了非常深入的残差通道注意网络(RCAN)。
具体来说,我们提出了一种残差(RIR)结构来形成非常深的网络,它由几个具有长跳过连接的残差组组成。
每个残差组包含一些具有短跳过连接的残差块。
同时,RIR允许丰富的低频信息通过多个跳过连接被绕过,使主网络专注于学习高频信息。
此外,我们提出了一种通道关注机制,通过考虑通道之间的相互依赖性,自适应地重新划分通道的特征。
广泛的实验表明,与最先进的方法相比,我们的RCAN实现了更好的准确性和视觉改善。
[√] 1.简介
图像SR是一个不好解决的问题,因为对于任何LR输入都存在多种解决方案。为了解决这样一个逆向问题,已经提出了许多基于学习的方法来学习LR和HR图像对之间的映射。前期的工作有SRCNN,VDSR,DRCN,EDSR等。
RCAN,残差通道注意力网络
SRCNN,第一个SRCNN
VDSR,非常深的CNN,使用了残差结构
DRCN,深度递归网络,使用了递归结构
EDSR,进阶的深度残差网络,提出了SR需要去除BN层
- 网络的深度对SR来说至关重要,但简单地堆叠残差块来构建更深的网络很难获得更好的改进。更深的网络是否能进一步促进图像SR,以及如何构建非常深的可训练网络,仍有待探索。
- 基于CNN的领先方法会平等对待每个通道的特征,缺乏跨特征通道的鉴别学习能力,并阻碍了深度网络的代表性。
基于以上两点,本文提出一个残差通道注意网络(RCAN),可以获得非常深的可训练网络,并同时自适应地学习更多有用的通道特征。
alec:
- 网络单纯的深不能提高更多的超分能力。平等的对待每个通道,阻碍了网络的学习能力。
- 因此需要让网络自适应的学习更多有用的通道特征。
- 更深的网络——RIR结构,残余组(RG)作为基本模块,长跳过连接允许残余学习在一个粗略的水平。在每个RG模块中,将几个简化的残差块与短跳过连接进行堆叠。长短跳过连接以及残余块中的短切,使得丰富的低频信息可以通过这些基于身份的跳过连接被绕过,这可以缓解信息的流动。
- 通道注意力机制CA——通过对各特征通道之间的相互依赖关系进行建模,对每个通道的特征进行自适应的重新划分。这样的CA机制使我们提出的网络能够集中在更多有用的通道上,并提高辨别学习的能力。
本文的三个贡献:
- RCAN网络
- 使用RIR构建更深的网络
- 提出通道注意力机制CA
[√] 2.相关工作
- 基于深度学习的超分辨:SRCNN,VDSR,DRCN,FSRCNN,SRResnet,SRGAN等,这些方法中的大多数都有有限的网络深度,这在视觉识别任务中被证明是非常重要的。此外,这些方法中的大多数都是对通道特征的平等处理,阻碍了对不同特征的更好的鉴别能力。
- 注意力机制:注意力可以被看作是一种指导,使可用的处理资源分配偏向于输入中最有信息的部分。注意力机制在高层次视觉任务中广受欢迎,在低层次视觉研究比较少。
alec:
- 注意力机制在高层次视觉任务中广受欢迎,在低层次视觉研究比较少。
- 超分属于低层次视觉任务。
[√] 3.RCAN网络
[√] 3.1模型结构
- RCAN包括4个部分:浅层特征提取、残差(RIR)深层特征提取、上采样模块,重建部分。
- 上采样可以使用反卷积、邻域上采样+卷积、Pixel-shuffle等,因为这些后上采样策略在性能方面更好。
- 损失函数方面可以使用L2,L1,感知损失,对抗损失等,本文使用L1损失。
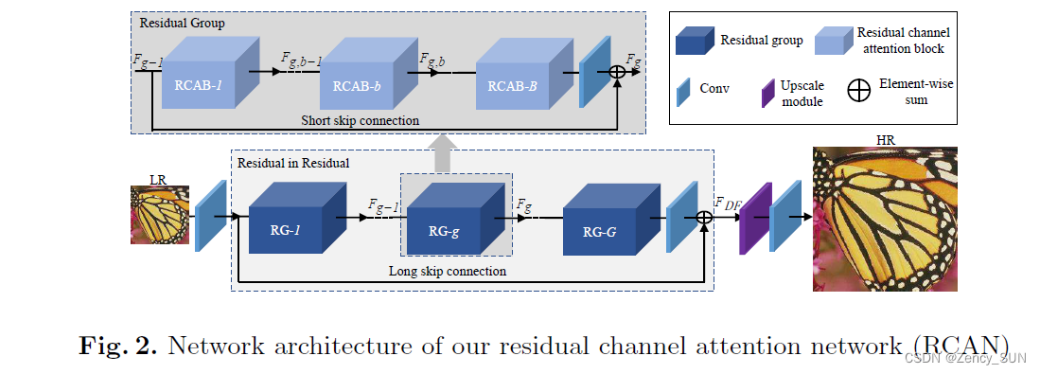
[√] 3.2.RIR模块(Residual in Residual)
该模块包括G个残差组RG和长跳连接,每个RG包含B个残差注意力通道模块RCAB和短跳连接。该残差结构可实现很深的CNN结构(400+)如上图。LSC和SSC可以使网络绕过更低频的信息。
[√] 3.3.注意力通道(CA)
- LR空间的信息有丰富的低频和有价值的高频部分。低频部分更复杂。高频成分通常是区域,充满了边缘、纹理和其他细节。
- Conv层中的每个滤波器都是以局部接受场来操作的。因此,卷积后的输出无法利用本地区域之外的背景信息。
- 多通道——全局池化——WD降维——ReLU激活——WU升维——Sigmoid激活——加权相乘——获得注意力的多通道
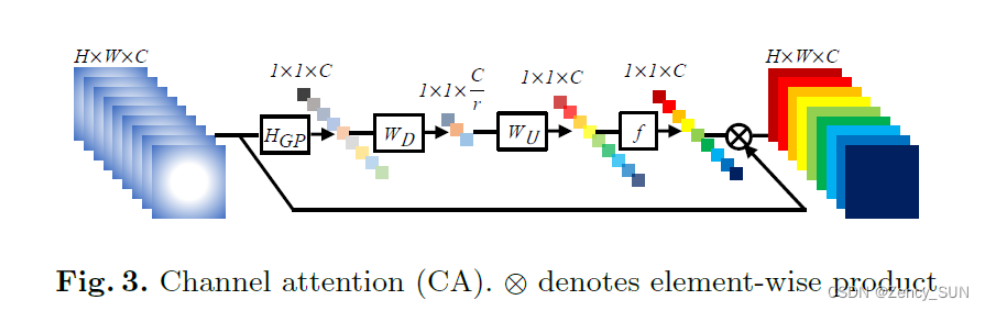
alec:
- 如上图,未通过CA模块之前,x层的C个特征图是没有注意力在里面的,彼此都是一样重要。在通过CA之后,得到了获得注意力的C个特征图。
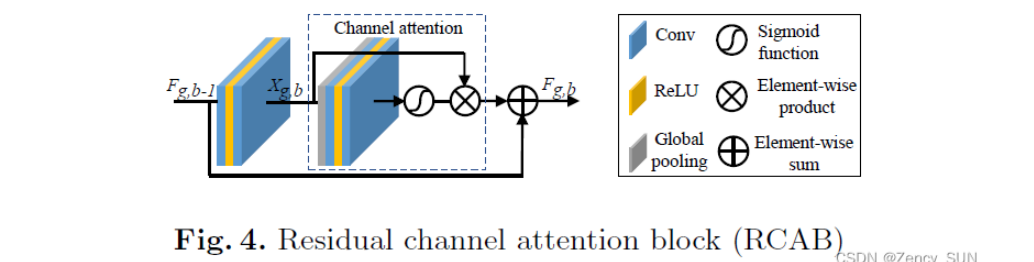
[√] 3.4.残差通道注意力块(RCAB)
在EDSR中的Multi就相当于所有通道都乘0.1,虽然引入了通道的特征重定比例来训练一个非常宽的网络,但在EDSR中没有考虑通道之间的相互依赖关系。在这些情况下,CA不被考虑。
[√] 4.实验
[√] 4.1 实验设置
训练集:DIVK,000-800,数据增强为随机旋转,水平翻转,随机裁剪16x48x48
测试集:Set5,Set14,B100,Urban100,Manga109,下采样使用BI与BD模型,在Y通道测试
取RIR中的RG为10个,每个RG中有20个RCBA。
[√] 4.2 RIR和CA的影响(消融实验)
alec:
- 本文使用了两个结构,RIR和CA,RIR是残差中的残差,残差的嵌套结构;CA是通道注意力结构。
RIR——当LSC和SSC都被移除时,无论是否使用通道关注(CA),PSNR值都相对较低。这表明,简单地堆叠残余块并不适用于实现图像SR的非常深入和强大的网络。这些比较表明,LSC和SSC对于非常深的网络是必不可少的。他们还证明了我们提出的残差(RIR)结构对非常深的网络的有效性。
alec:
- 长、短跳跃连接对于非常深的网络是必不可少的。
CA——当我们比较前4列和后4列的结果时,我们发现有CA的网络会比没有CA的网络表现更好。受益于非常大的网络深度,非常深的可训练网络可以实现非常高的性能。从这样的深度网络中很难获得进一步的改进,但我们通过CA获得了改进。即使没有RIR,CA也能将性能从37.45dB提高到37.52dB。这些比较有力地证明了CA的有效性,并表明对信道特征的自适应关注确实提高了性能。

[√] 4.3 使用Bicubuc降采样(BI模型)的结果
alec:
- bicubic指的是双三次插值下采样算法
定量分析:在Set5,Set14,B100,Urban100,Manga109上与Bicubic、SRCNN,FSRCNN,VDSR,LapSRN,MemNet,EDSR,SRMDNF,D-DBPN,RND比较2,3,4,8倍的结果,都取得了最好成绩。非常大的网络深度和CA可以提高性能。(表2)
定性分析:大多数被比较的方法不能恢复晶格,并且会受到模糊伪影的影响。相比之下,RCAN可以更好地缓解模糊伪影,恢复更多的细节。这种明显的比较表明,具有更强大表征能力的网络可以从LR空间中提取更复杂的特征(图5)。对于更大放大倍数(x8)由于缩放系数非常大,Bicubic的结果会失去结构,产生不同的结构。这种错误的预缩放结果也会导致一些最先进的方法产生完全错误的结构(SRCNN、VDSR、MemNet)。即使从原始的LR输入开始,其他方法也不能恢复正确的结构。而我们的RCAN可以正确地恢复它们。(图6)RCAN使主网络学习到残余信息并增强了表征能力。
alec:
- RIR这种长短残差结构能够利用深度的网络充分学习特征信息
- CA则能够提高网络的表征能力,让网络更加灵活地关注不同的通道,而不是一视同仁
[√] 4.4 使用Blur-Downscale(BD模型)的结果
定量分析:在Set5,Set14,B100,Urban100,Manga109上与Bicubic、SRCNN,FSRCNN,VDSR,LapSRN,MemNet,EDSR,SRMDNF,D-DBPN,RND比较3倍的结果,都取得了最好成绩。(表3)与完全使用RDN中的分层特征相比,RCAN中带有通道注意的更深的网络取得了更好的性能。这种比较也表明,研究更深的网络用于图像SR有很大的潜力。
定性分析:对于图像中具有挑战性的细节,大多数方法都有严重的模糊假象。RDN在一定程度上缓解了这一问题,并能恢复更多的细节。相比之下,RCAN通过恢复更多的信息成分获得了更好的结果。这些比较表明,非常深的通道注意力引导的网络将缓解模糊的伪影。这也证明了RCAN对于BD退化模型的强大能力。
RDN:残差密集网络,CVPR 2018
带通道注意力的网络比RDN这种残差密集网络效果更好,其中R是相加,D是concat叠加
[√] 4.5 物体识别性能
图像SR也是高级视觉任务(如物体识别)的预处理步骤。我们评估了物体识别性能,以进一步证明我们的RCAN的有效性。这里我们使用与ENet[31]相同的设置。我们使用ResNet-50[11]作为评估模型,并使用ImageNet CLS-LOC验证数据集的前1000张图像进行评估。原始的裁剪过的224×224的图像被用于基线,降级为56×56的SR方法。我们使用4种最先进的方法(DRCN[17]、FSRCN[6]、PSyCo[30]和ENet-E[31])来提高LR图像的比例,然后计算其准确度。如表4所示,我们的RCAN取得了最低的前1名和前5名的误差。这些比较进一步证明了我们的RCAN具有非常强大的表示能力。
图像SR也是高级视觉任务(如物体识别)的预处理步骤。我们评估了物体识别性能,以进一步证明我们的RCAN的有效性。这里我们使用与ENet[31]相同的设置。我们使用ResNet-50[11]作为评估模型,并使用ImageNet CLS-LOC验证数据集的前1000张图像进行评估。原始的裁剪过的224×224的图像被用于基线,降级为56×56的SR方法。我们使用4种最先进的方法(DRCN[17]、FSRCN[6]、PSyCo[30]和ENet-E[31])来提高LR图像的比例,然后计算其准确度。如表4所示,我们的RCAN取得了最低的前1名和前5名的误差。这些比较进一步证明了我们的RCAN具有非常强大的表示能力。
[√] 4.6 模型大小分析
RCAN模型很深,但是其参数比EDSR和RND少,RCAN和RCAN+取得了更高的性能,在模型大小和性能之间有一个更好的权衡。这也表明,更深的网络可能比更宽的网络更容易获得更好的性能。
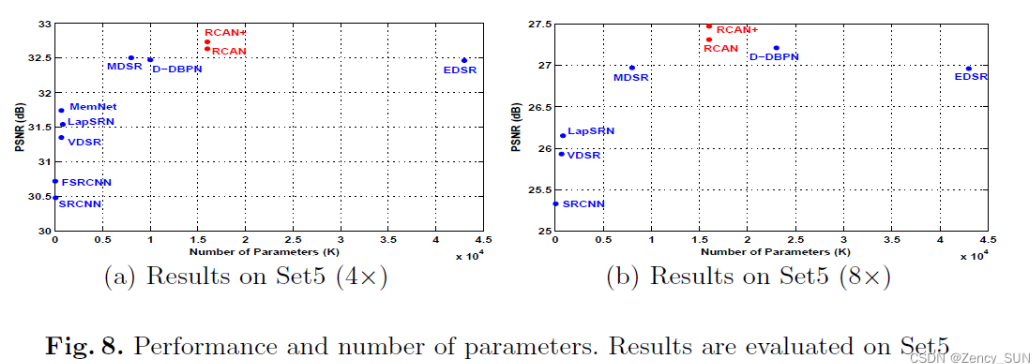
alec:
- 模型的参数量某种程度上和模型的能力成正相关。因此比较模型能力的时候,如果抛开模型参数量不弹,那么就不是控制变量法实验。
- 在保持模型的能力的前提下,轻量化模型也是一个值得探究的方向。
- 本文使用CA机制,在模型大小和性能之间有了好的权衡。比EDSR和RDN的参数量少,但是性能更好。
[√] 5. 结论
提出了用于高精度图像SR的非常深的残余通道注意网络(RCAN)。
具体来说,残差(RIR)结构使RCAN可以通过LSC和SSC达到非常大的深度。
同时,RIR允许丰富的低频信息通过多个跳过连接被绕过,使主网络专注于学习高频信息。
此外,为了提高网络的能力,我们提出了通道注意(CA)机制,通过考虑通道之间的相互依赖性,自适应地重新划分通道的特征。
在SR与BI和BD模型上进行的大量实验证明了我们提出的RCAN的有效性。RCAN在物体识别方面也显示出很好的效果。
[√] 代码实现
https://github.com/yulunzhang/RCAN
[√] 个人总结
- 高频细节的增强是通过RIR结构实现的,使得多个跳连接绕过低频信息
- RCAN不仅可以达到更优的PSNR,它用于目标识别的预处理可以提高目标识别的效果,可能就在于它更多的恢复了边缘高频信息,这些信息是更有助于目标识别任务的。(实验中的定性部分也可以说明这一点)
- Enhancenet这篇文章值得注意,它也强调SR任务要强调高频细节,也做了一些目标识别的实验。