031 - 文章阅读笔记:【图像超分辨率重建】——HAT论文精读笔记 - CSDN - Zency_SUN
本文最后更新于:3 个月前
转载自:
【√】【图像超分辨率重建】——HAT论文精读笔记 - CSDN - Zency_SUN
于 2022-12-28 17:30:48
2022-Activating More Pixels in Image Super-Resolution Transformer(HAT)
[√] 基本信息
作者: Xiangyu Chen, Xintao Wang, Jiantao Zhou, and Chao Dong
期刊:
引用:
摘要: 基于 Transformer 的方法在图像超分辨率等低级视觉任务中表现出令人印象深刻的性能。然而,我们发现这些网络只能通过归因分析利用有限空间范围的输入信息。这意味着 Transformer 的潜力在现有网络中仍未得到充分利用。为了激活更多的输入像素进行重建,我们提出了一种新颖的混合注意力转换器 (HAT)。它结合了通道注意力(CAB)和自注意力([S]W-MSA)方案,从而利用它们的互补优势。此外,为了更好地聚合跨窗口信息,我们引入了重叠交叉注意模块(OCAB)来增强相邻窗口特征之间的交互。在训练阶段,我们额外提出了一种相同任务的预训练策略,以带来进一步的改进。大量实验证明了所提出模块的有效性,整体方法明显优于最先进的方法 1dB 以上。
alec:
- 基于 Transformer 的方法在图像超分辨率等低级视觉任务中表现出令人印象深刻的性能。
- 混合注意力转换器HAT结合了通道注意力和自注意力。
- 在训练阶段,我们额外提出了一种相同任务的预训练策略,以带来进一步的改进。
[√] 1.简介
alec:
- swing,摆荡、旋转、秋千
- swing,翅膀
- 最近Transformer在NLP领域的成功带动了其在高级视觉任务中的发展,随后其在低级视觉任务方面也起到了很好的效果,尤其是Swin-Transformer。受到Swing-Transformer启发最近兴起的SISR算法是SwinIR。
在SISR领域中,近些年均使用法国CNN的方法,获得了很好的效果,最近Transformer在NLP领域的成功带动了其在高级视觉任务中的发展,随后其在低级视觉任务方面也起到了很好的效果,尤其是Swin-Transformer。受到Swing-Transformer启发最近兴起的SISR算法是SwinIR。
“为什么 Transformer 比 CNN 更好”?一个直观的解释是,这种网络可以受益于自我注意机制并利用远程信息。然而,我们采用归因分析方法 LAM [14] 来检查 SwinIR 中重建所涉及的利用信息范围。有趣的是,我们发现 SwinIR 在超分辨率方面并没有比基于 CNN 的方法(例如 RCAN [65])利用更多的输入像素。此外,尽管 SwinIR 获得了更高的定量性能,但在某些情况下,由于使用的信息范围有限,它产生的结果不如 RCAN。这些现象说明Transformer对局部信息的建模能力更强,但其利用信息的范围有待扩展。
本文的贡献:
- 将通道注意力引入 Transformer 以利用更多输入信息
- 提出了一个重叠的交叉注意力模块来更好地聚合跨窗口信息
- 提供了一个相同任务的预训练策略来进一步激活所提出的网络的潜力
alec:
- transformer中主要是自注意力,本文将通道注意力引入transformer。
- 通过预训练策略,提高本模型的潜力。
[√] 2.相关工作
基于CNN的SISR:以SRCNN为代表的超分网络显示出突出性能,残差块、密集块等模块增强了网络的表示能力;递归神经网络、图神经网络等框架也起到了很好的效果;基于对抗神经网络GAN的网络提高了感知质量,产生更真实的结果;注意力机制(RCAN、SAN、HAN、NLRN、NLSN)在图像保真度方面取得进一步提高;最近Transformer技术也显示出强大的表示能力。本文使用LAM分析理解SR网络的各种行为。
CV领域的Transformer:Transformer因其在自然语言处理领域的成功而引起了计算机视觉界的关注。一系列基于 Transformer 的方法已经被开发用于高级视觉任务,包括图像分类,目标检测,分割等。虽然vision Transformer已经显示出其在建模远程依赖方面的优势,仍有许多工作证明卷积可以帮助 Transformer 实现更好的视觉表示。由于令人印象深刻的性能,Transformer 也被引入用于低级视觉任务。SwinIR、EDT是将Transformer技术应用到SISR的伟大尝试。
现有的作品仍然不能充分发挥 Transformer 的潜力,而本文方法可以激活更多的输入信息以实现更好的重建。
[√] 3.HAT模型
[√] 3.1.动机
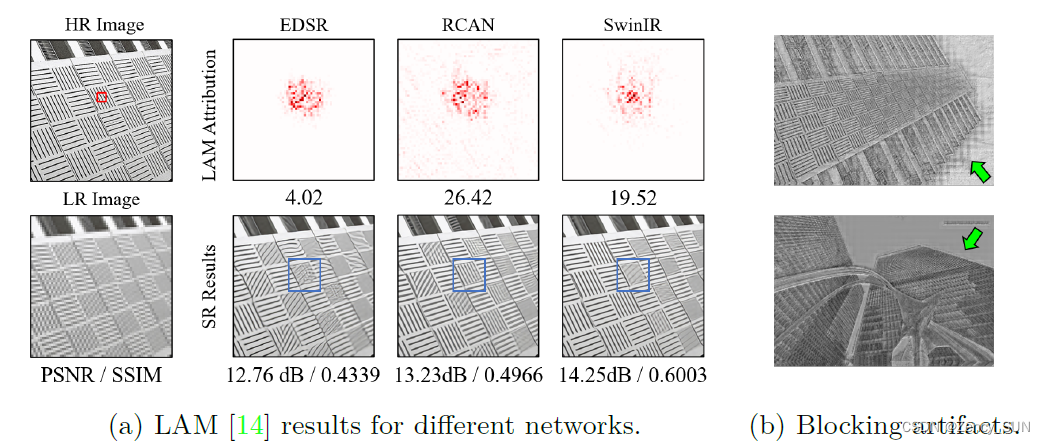
- Swin Transformer已经在图像超分辨率方面表现出色。然后我们很想知道是什么让它比基于 CNN 的方法更有效。为了揭示其工作机制,我们采用了一种诊断工具——LAM,这是一种为 SR 设计的归因方法。使用 LAM,我们可以判断哪些输入像素对所选区域的贡献最大。如图 2(a) 所示,红色标记点是有助于重建的信息像素。直观地说,利用的信息越多,可以获得越好的性能。比较 RCAN和 EDSR,这对于基于 CNN 的方法来说是正确的。然而,对于基于 Transformer 的方法——SwinIR,其 LAM 并没有显示出比 RCAN 更大的范围。这与我们的常识相矛盾,但也可以为我们提供额外的见解。首先,这意味着 SwinIR 具有比 CNN 更强的映射能力,因此可以使用更少的信息来获得更好的性能。其次,如果 SwinIR 可以利用更多的输入像素,它仍有改进空间。如图 2(a) 所示,SwinIR 在蓝色框中标记的重建模式不如 RCAN。 通道注意力帮助RCAN看到更多像素,这对Transformer可能也有好处。
alec:
- 窗口分区机制,在移位窗口的时候会导致伪影。移位窗口无法有效的建立跨窗口的连接。
- 在 SwinIR 的中间特征图中观察到明显的块效应,如图 2(b)所示。这些伪影是由窗口分区机制引起的,这种现象表明移位窗口机制无法有效地建立跨窗口连接。一些针对高级视觉任务的工作也指出,增强窗口之间的连接可以改进基于窗口的自注意力方法。基于以上两点,我们研究了基于 Transformer 的模型中的通道注意力,并提出了一个重叠的交叉注意力模块,以更好地为基于窗口的 SR Transformer 聚合跨窗口信息。
[√] 3.2.网络结构
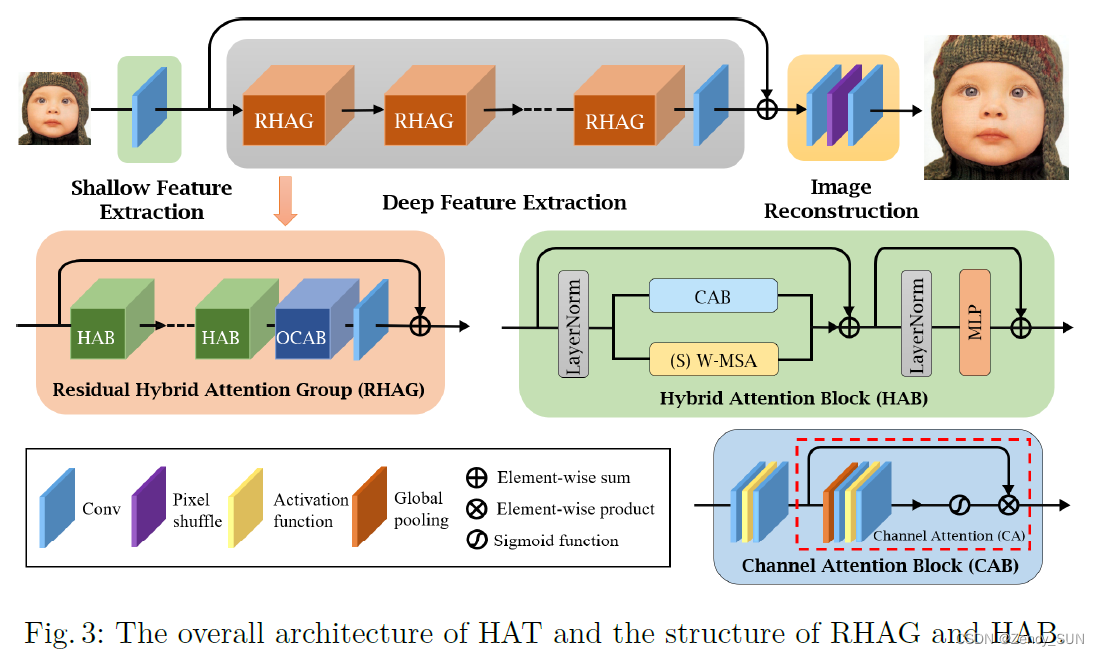
alec:
- RHAG = 残差混合注意力组
- HAB = 混合注意力模块
- OCAB = 重叠的交叉注意力模块
- 其中RHAG中有混合注意力模块HAB、重叠的交叉注意力模块OCAB和残差连接
- 混合注意力模块中有通道注意力模块
alec:
- 通道注意力中的注意力权重,是特征图通过全局池化、卷积等,然后通过激活函数得到,然后再乘上原特征图。
- 总体结构:浅层特征提取——深层特征提取——图像重建(Pixel-Shuffle),L1损失
- 残差混合注意力组(RHAG)深层特征提取的基本单元
- 混合注意力块(HAB)在STL的基础上添加了CAB,修改MSA为(S)W-MSA
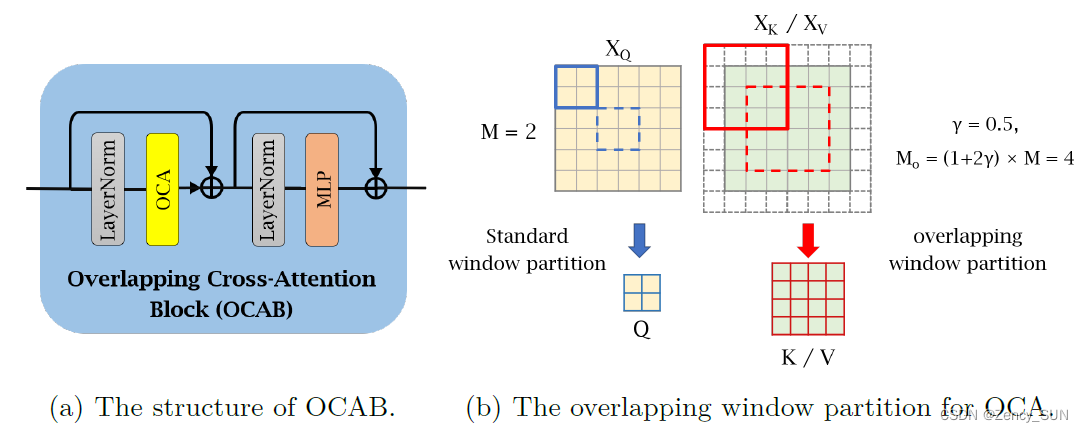
- 重叠交叉注意力块(OCAB)在STL的基础上将MSA替换为OCA(基于重叠窗口分区计算,查询更大窗口)
alec:
- STL的结构:LN + MSA + 跳跃连接 + LN + MLP + 跳跃连接
[√] 3.3.ImageNet预训练
alec:
- IPT、EDT等表明预训练在低级任务中起着重要作用。这些工作旨在探索多任务预训练对目标任务的影响。
IPT、EDT等表明预训练在低级任务中起着重要作用。这些工作旨在探索多任务预训练对目标任务的影响。相比之下,我们基于相同的任务直接对更大规模的数据集(即 ImageNet )进行预训练。例如,当我们要为×4 SR训练一个模型时,我们首先在ImageNet上训练一个×4 SR模型,然后在特定的数据集上进行微调,比如DF2K。同任务预训练,更简单同时带来更多的性能提升。值得一提的是,足够的预训练训练迭代次数和适当的小学习率进行微调对于预训练策略的有效性非常重要。我们认为这是因为 Transformer 需要更多的数据和迭代来学习任务的一般知识,但需要较小的学习率进行微调以避免对特定数据集的过度拟合。
[√] 4.实验
[√] 4.1.实验设置
- 训练集:DIV2K+Flicker2K
- 预训练:ImageNet
- 网络详情:RHAG、HAB均为6个,HAT-L中RHAG个数加倍
- 比较指标:PSNR、SSIM(YCbCr)
[√] 4.2.不同窗口大小的影响
16*16的窗口效果最好,本文采用了该设置

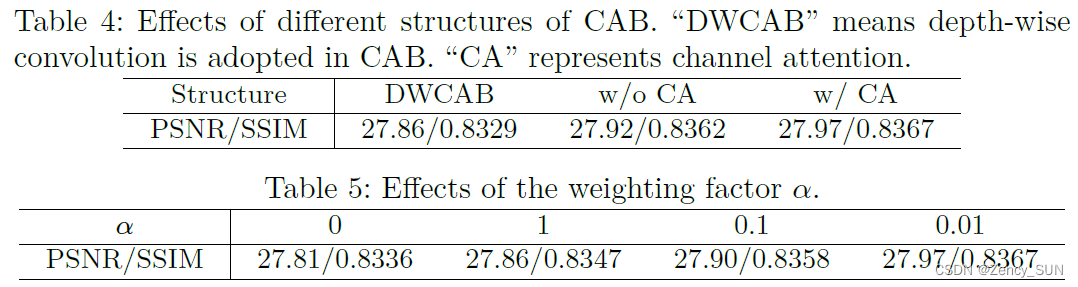
[√] 4.3.消融实验
- OCAB与CAB的有效性

- OCAB中重叠大小的影响

- CAB不同设计的影响
[√] 4.4.与SOTA比较
在x2,x3,x4倍数下与EDSR, RCAN, SAN, IGNN, HAN, NLSN, RCAN-it,比较,同时在预训练方法下与IPT、 EDT比较,均达到了最优的效果。具体数据见原文。
[√] 4.5.同任务预训练的有效性
同任务预训练表现更好,不仅在预训练阶段,在微调过程中也表现得更好。与特定任务的预训练相比,多任务预训练似乎削弱了性能。从这个角度来看,我们倾向于认为“为什么预训练有效”的原因是数据的多样性,而不是任务之间的相关性。
[√] 5.结论
在本文中,我们提出了一种用于图像超分辨率的新型混合注意力转换器 HAT。我们的模型结合了通道注意力和自我注意力来激活更多像素来重建高分辨率结果。此外,我们提出了一个重叠的交叉注意力模块,它计算具有不同窗口大小的特征之间的注意力,以更好地聚合跨窗口信息。此外,我们引入了相同任务的预训练策略,以进一步激活所提出模型的潜力。广泛的实验表明了所提出模块的有效性,我们的 HAT 明显优于最先进的方法
[√] 代码实现
[√] 个人总结
- 对将Transformer引入超分SwinIR算法进行改进,在RCAN的基础上结合通道注意力(RCAN)和自注意力(SwinIR),并提出OCAB。总体而言,HAT是基于Transformer、注意力机制的超分的优秀作品
NLRN、NLSN…
SwinIR、EDT…