6 - 循环神经网络
本文最后更新于:3 个月前
[√] 6.0 - 循环神经网络
alec:
循环神经网络的变种版本:GRU和LSTM
前馈神经网络和卷积神经网络,信息是单向传播的
循环神经网络中,信息是带有环路的
[√] 6.1 - 给神经网络增加记忆能力
[√] 前馈网络
alec:
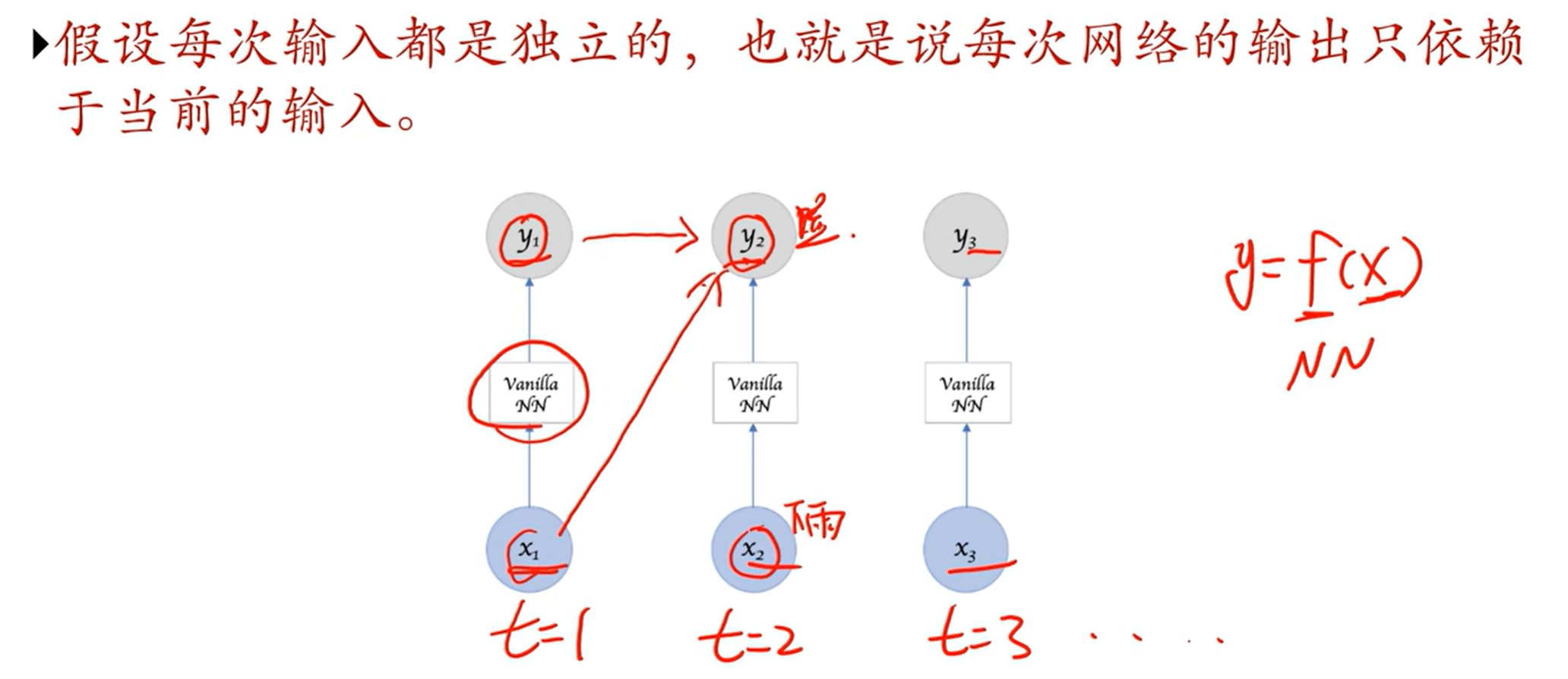
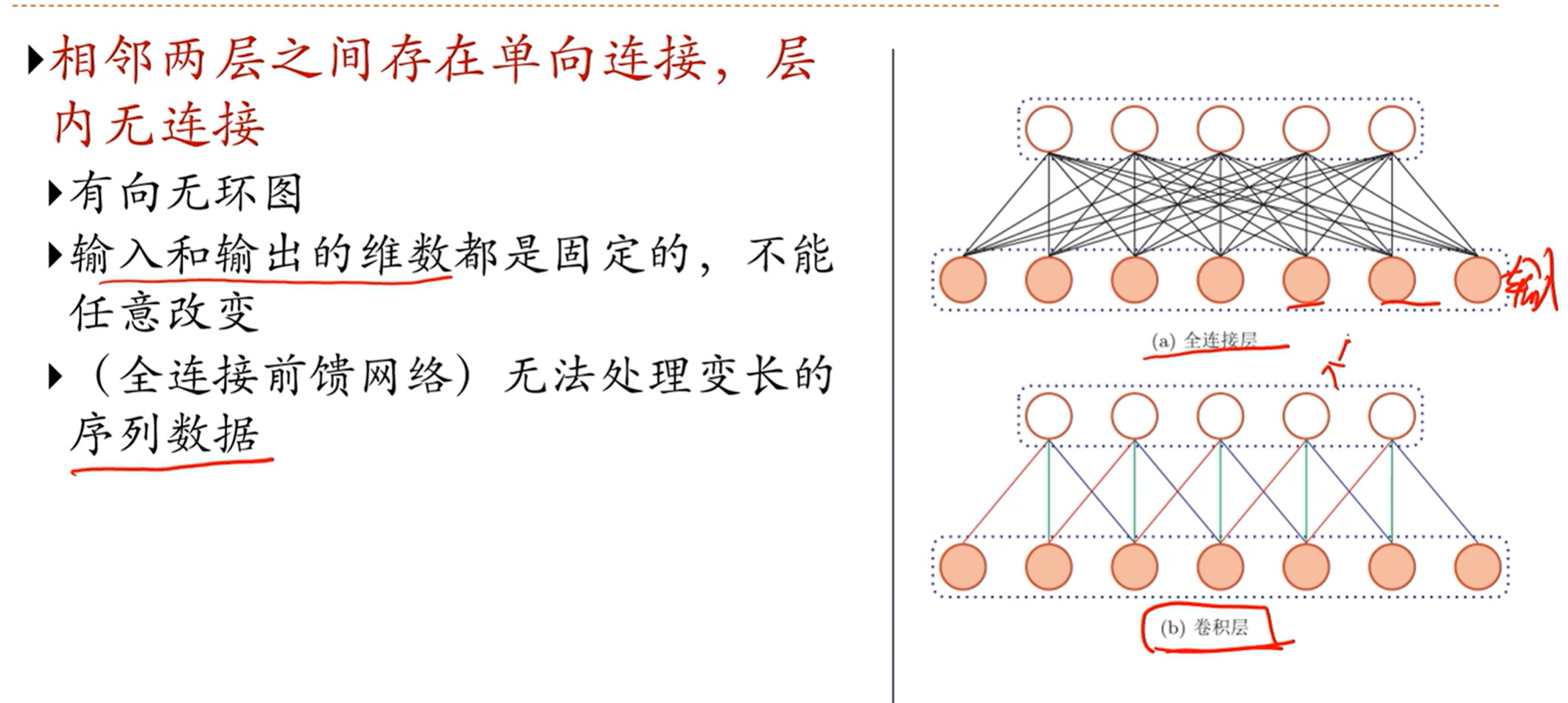
前馈神经网络总体上是无法处理可变大小的输入的(卷积神经网络中也有全连接层)
序列数据通常来讲是变长的,因为无法通过前馈神经网路来处理
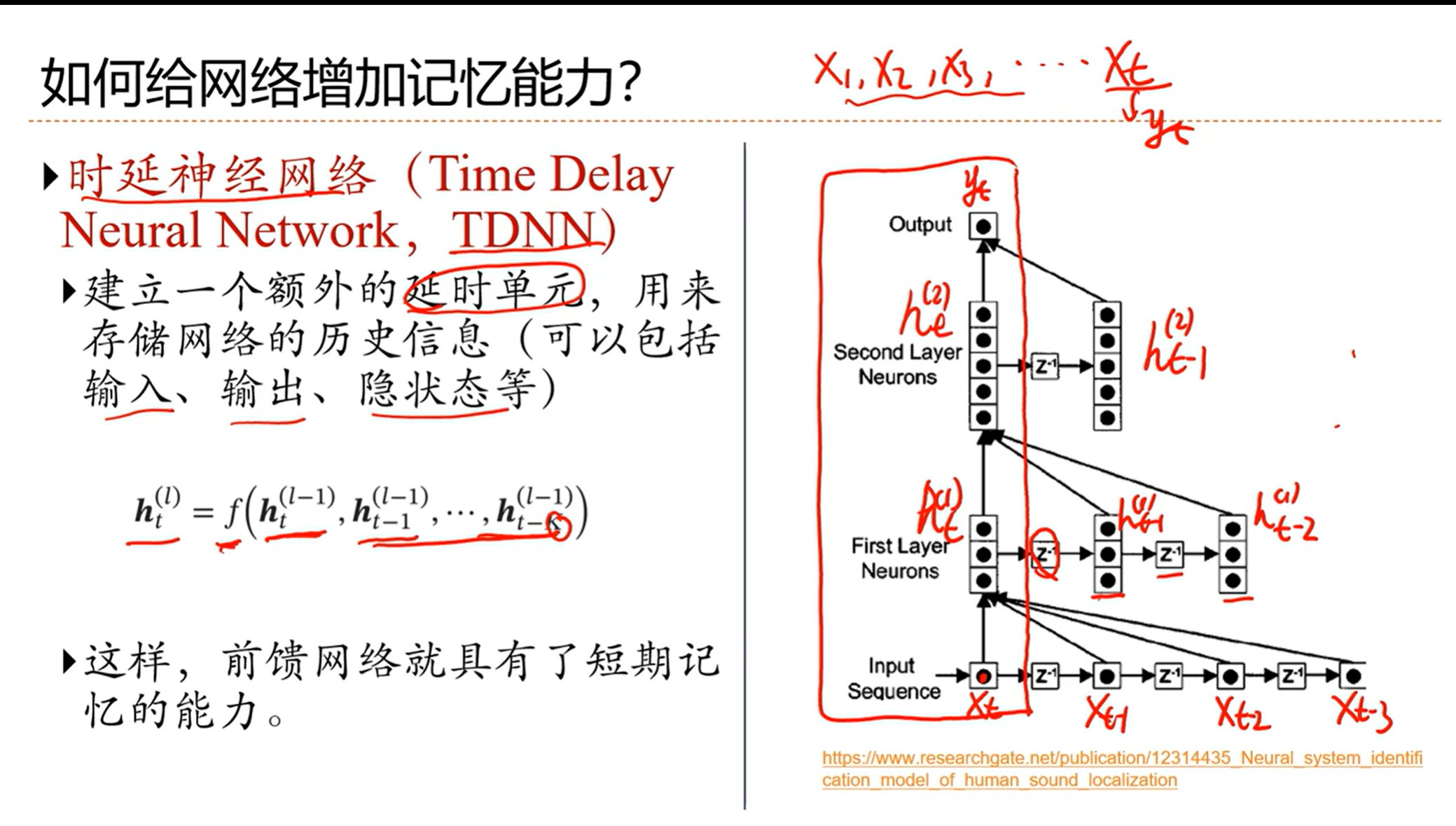
需要想办法给网络增加记忆能力,记住之前时刻的信息
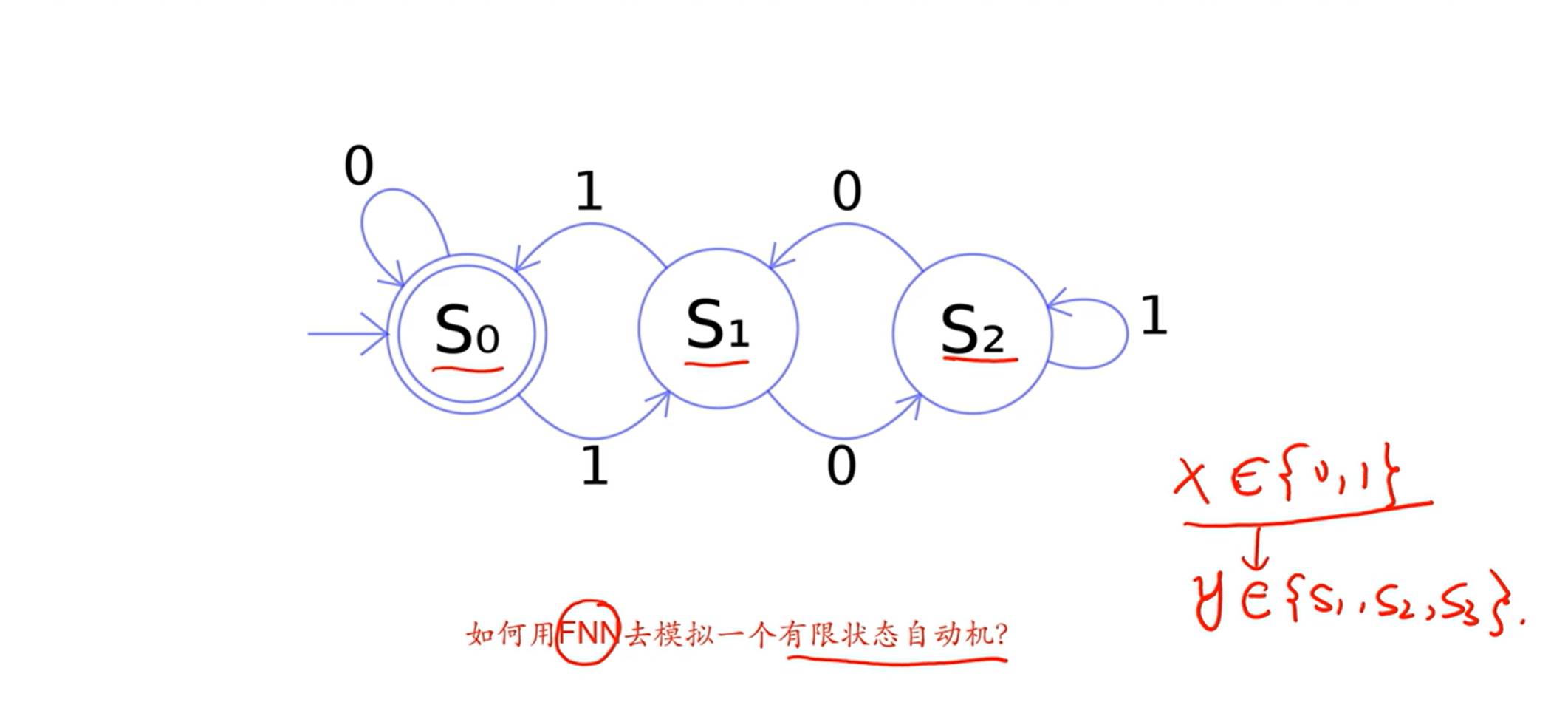
[√] 有限状态自动机
alec:
- FNN指的是前馈神经网络
- 有的时候,输出不是只根据输入确定的,也取决于之前的输出,即当前的状态。
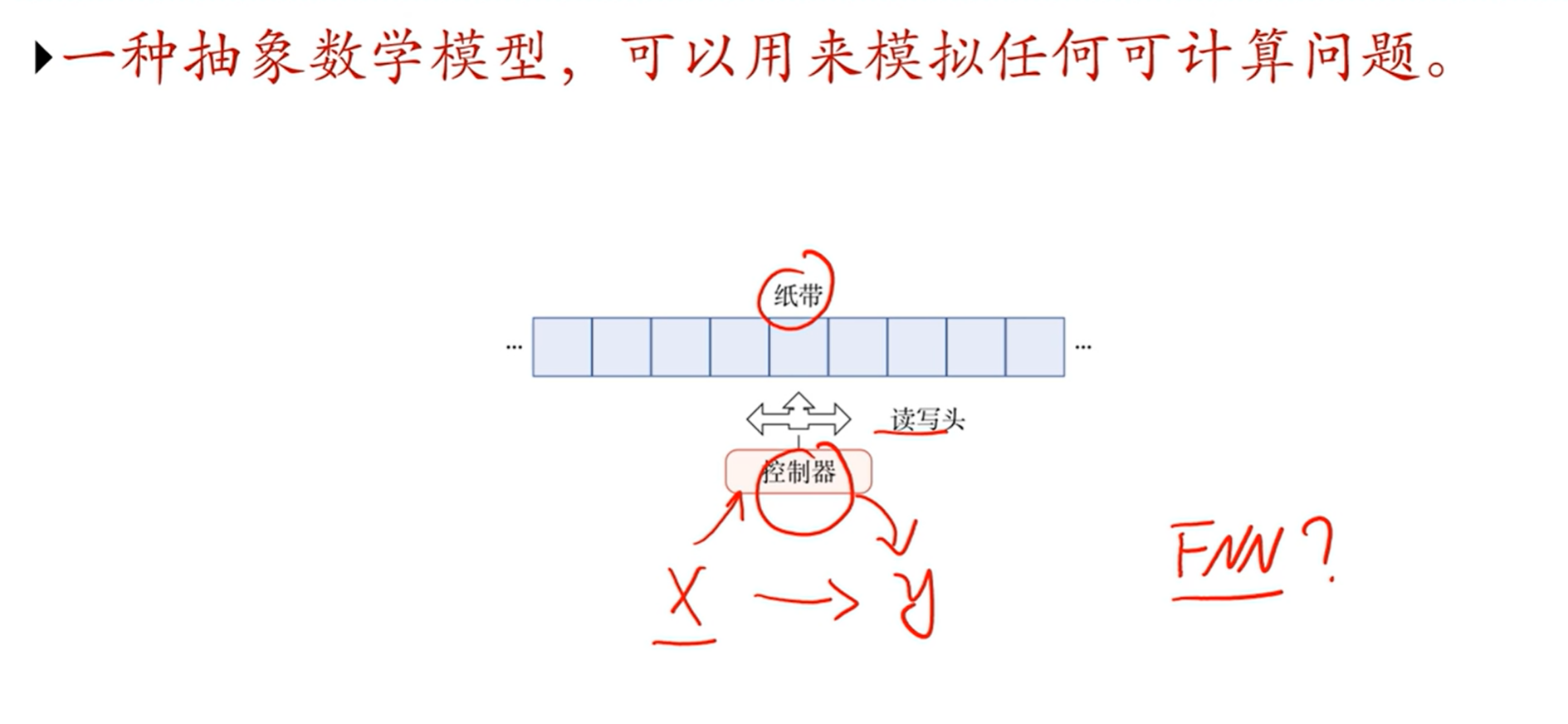
[√] 图灵机
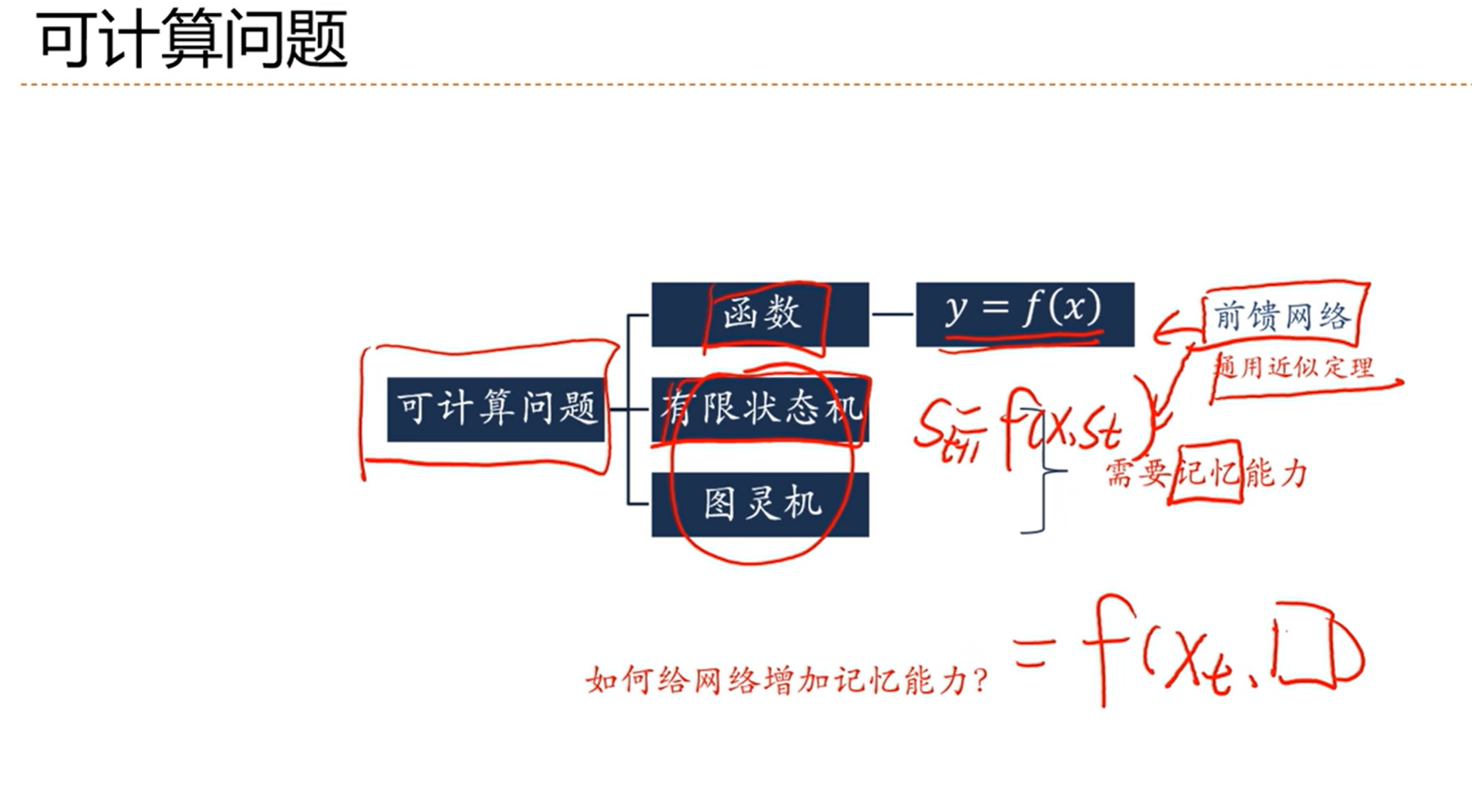
[√] 可计算问题
alec:
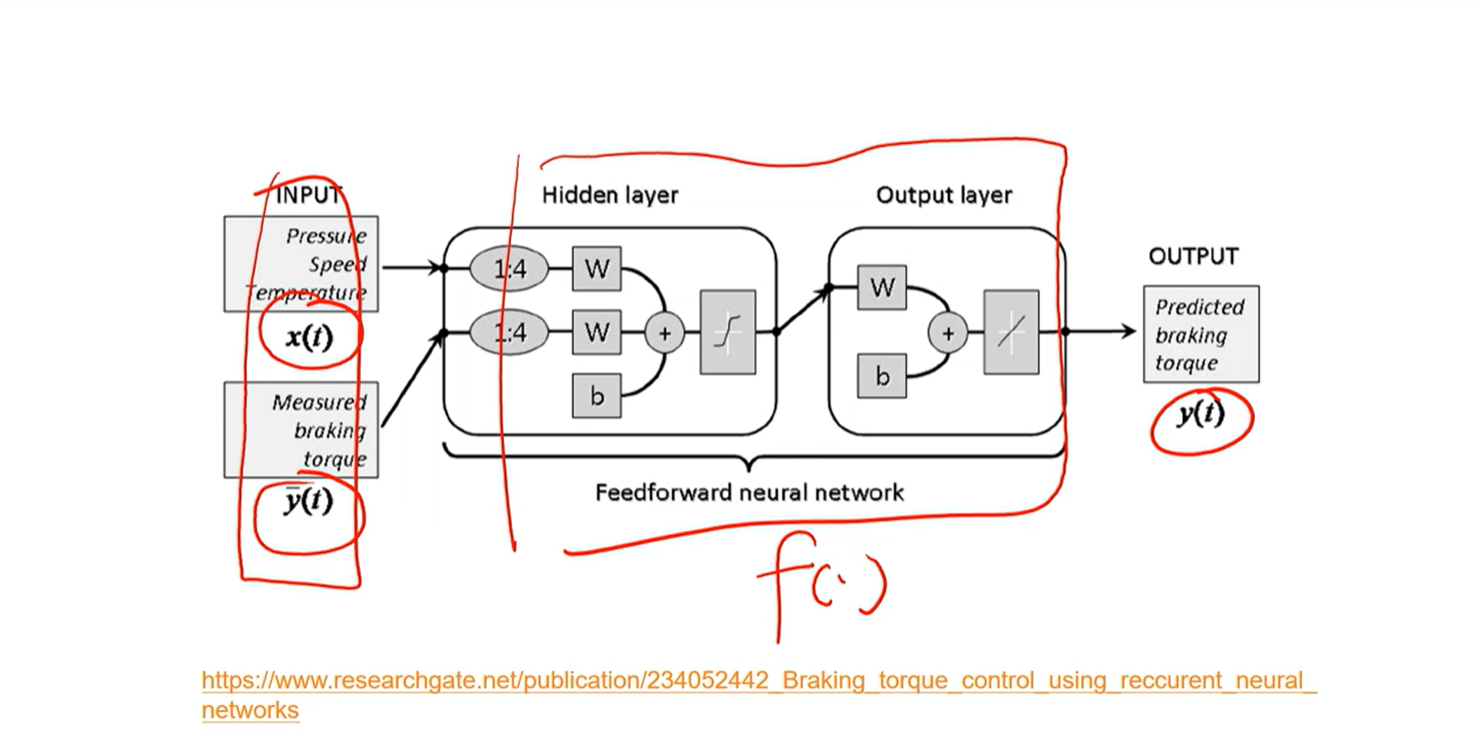
我们需要一种函数,这个函数不光需要输入,还需要记忆,然后才能根据输入和记忆计算当前时刻的输出
y = f(x, 记忆)

[√] 如何给网络增加记忆能力
[√] 非线性自回归模型
[√] 6.2 - 循环神经网络
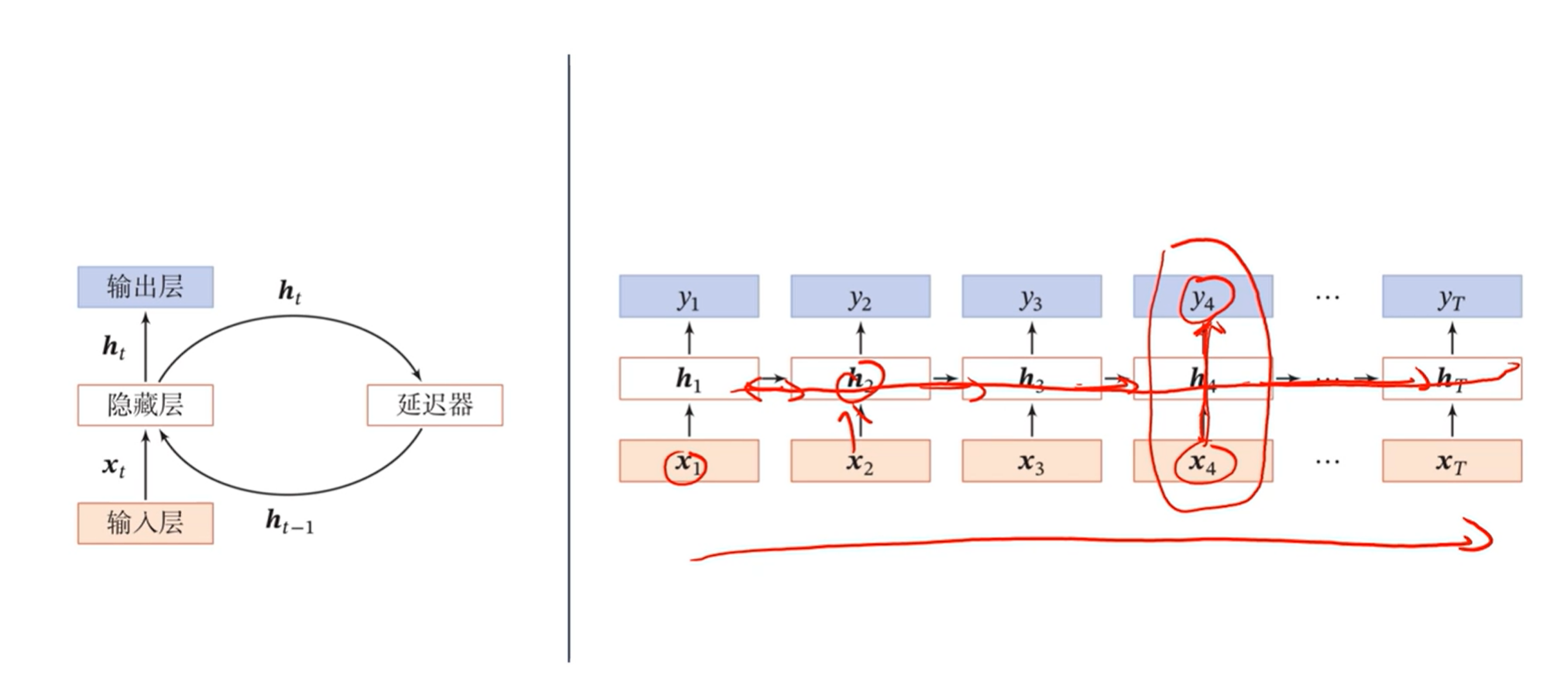
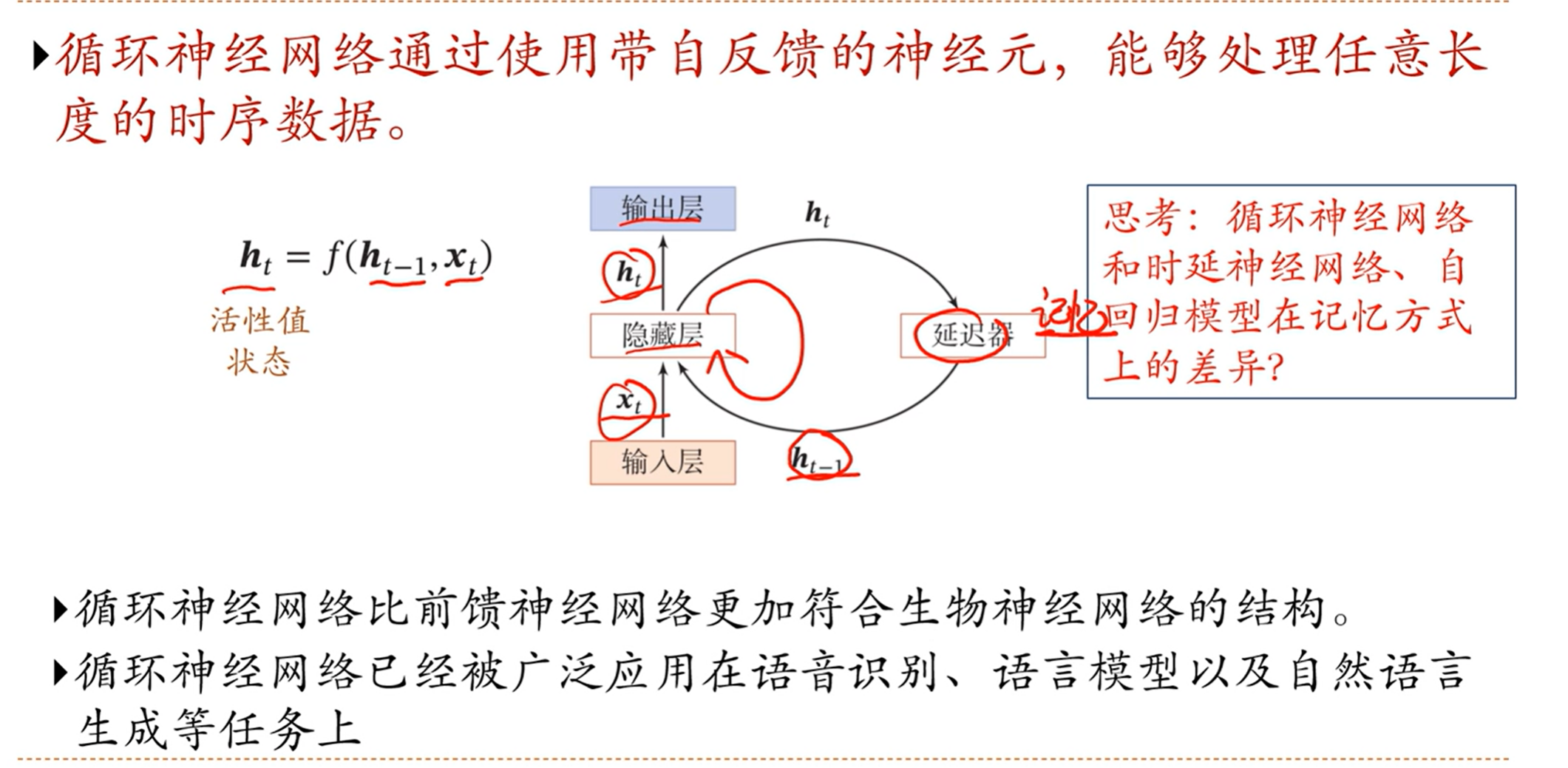
[√] 循环神经网络
alec:
当前的状态ht,通过延时器之后,变成ht-1,用作本次的记忆给下一次用
在我们的生物神经网络中,是有大量的循环边存在
循环神经网络有记忆能力
[√] 按时间展开
可以看出,从时间维度上,是一个非常深的网络,但是在非时间维度上(即竖着看)又是一个非常浅的网络
[√] 简单循环网络(SRN)
[√] 图灵完备
alec:
我们认为,如果FNN能够模拟任何的函数的话,那么RNN就可以模拟任何的程序
[√] 循环神经网络
alec:
非常有名的联想记忆模型是hopfield
[√] 6.3 - 应用到机器学习
[√] 应用到机器学习
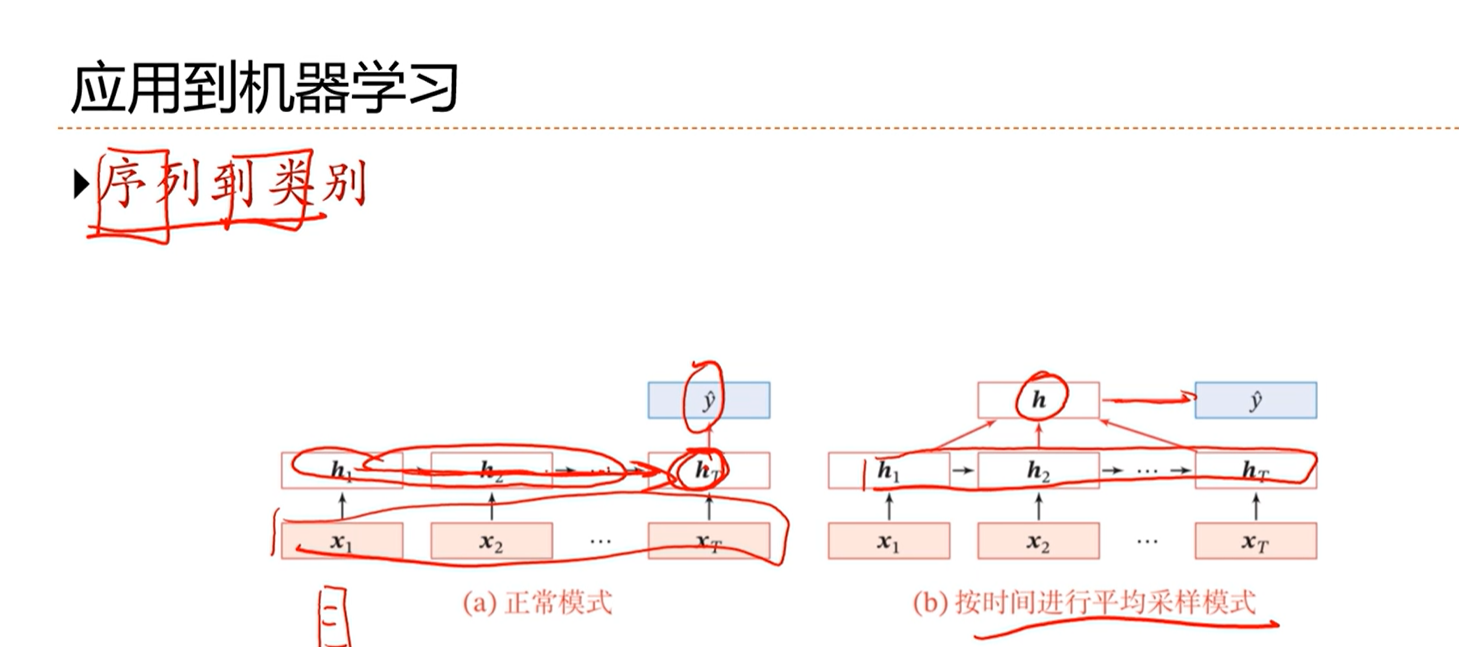
主要有三类:
- 序列到类别
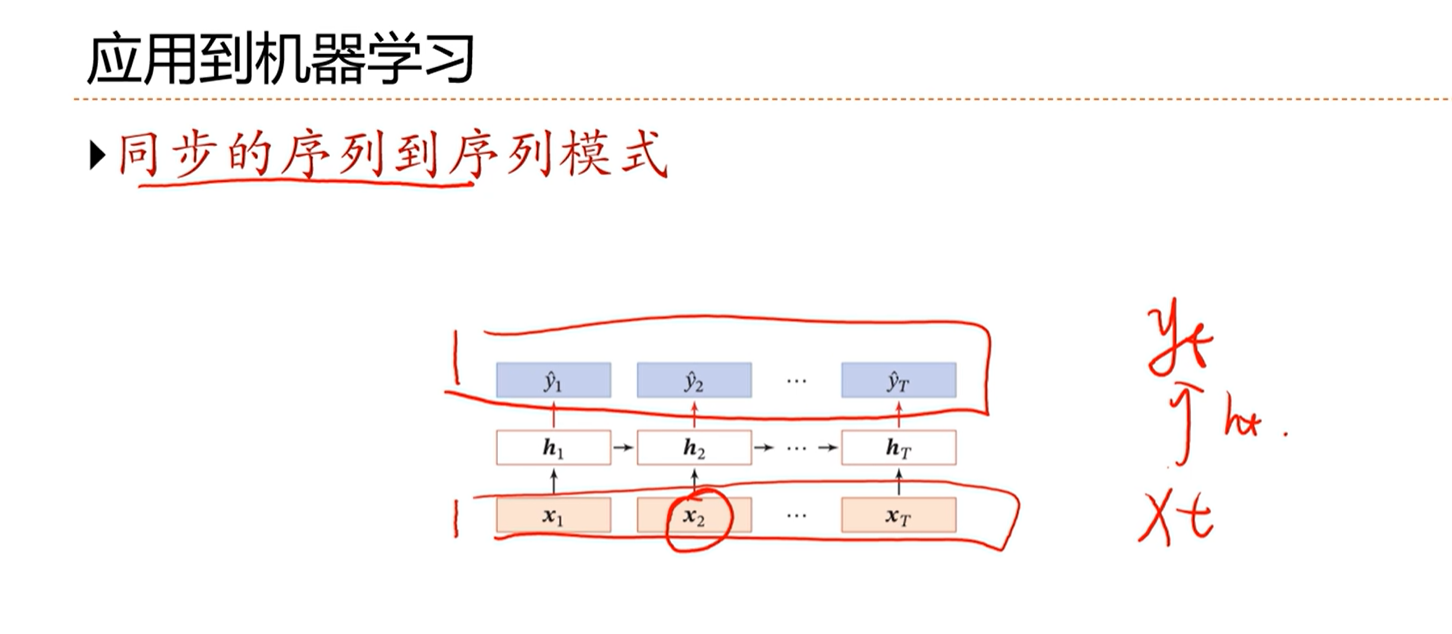
- 同步的序列到序列模式
- 异步的序列到序列模式
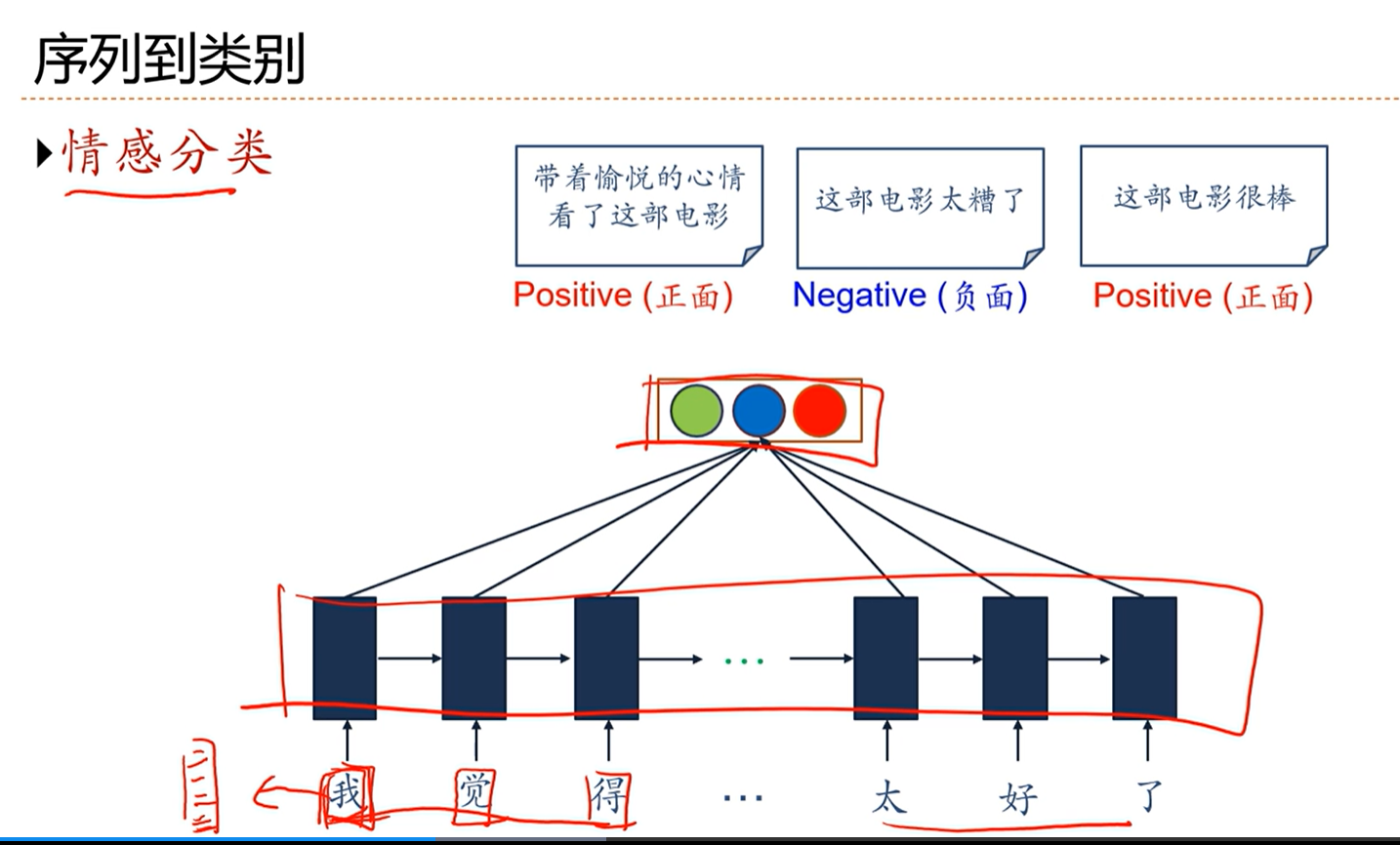
[√] 序列到类别
[√] 情感分类
alec:
一个额外的东西:
- 在用RNN做文本处理的时候,第一步会做一件事就是将文字映射到一个向量上面去,也叫wordembedding。这个操作可以通过查表操作完成。
- 这个操作简单,通过一个查表操作就可以了
[√] 同步的序列到序列模式
alec:
输入是一个序列,输出也是一个序列。且输入和输出和一一对应的。

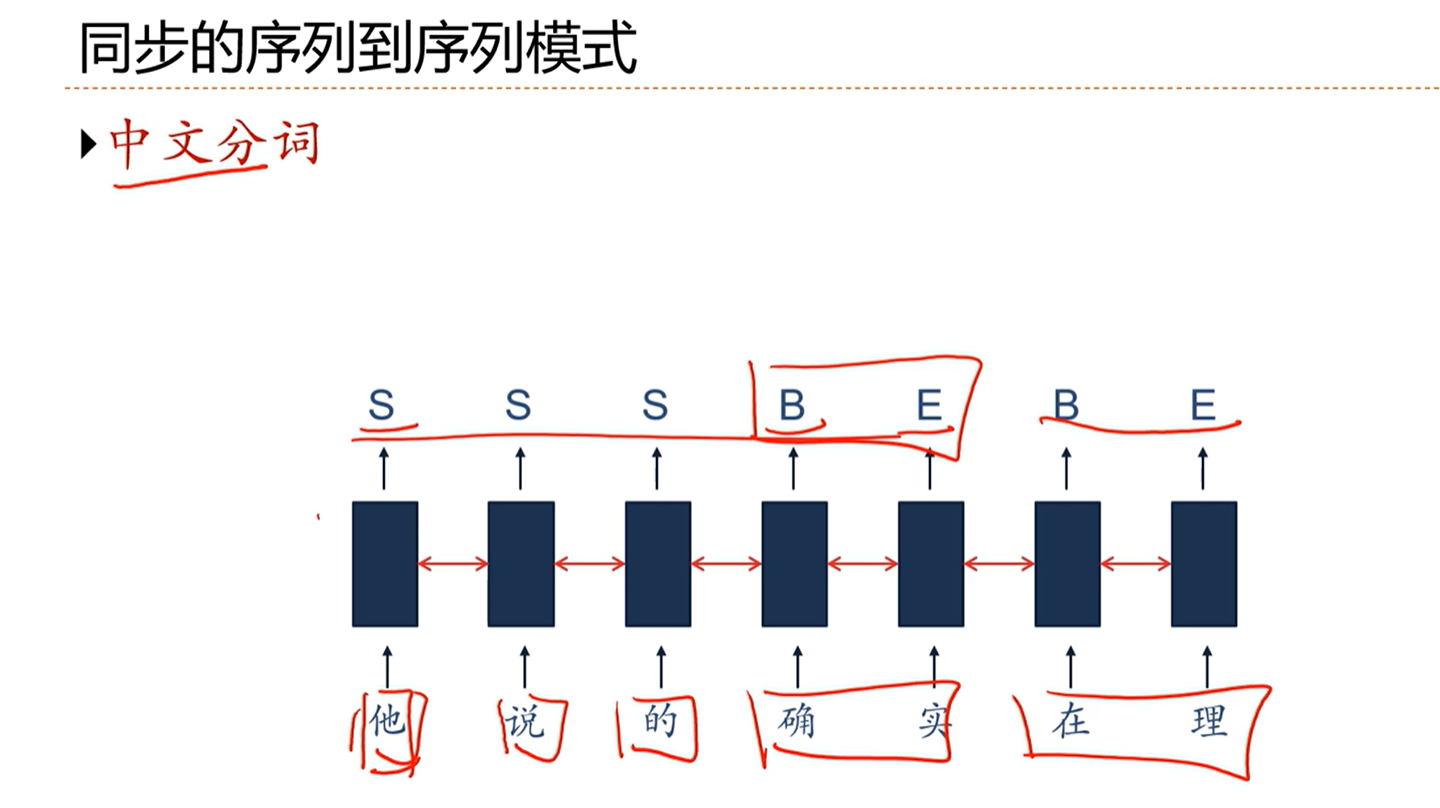
[√] 举例:中文分词
alec:
中文分词问题存在歧义,因此不好分。因此通过RNN,通过序列标注进行学习。
s表示单个成词,b表示begin,e表示end

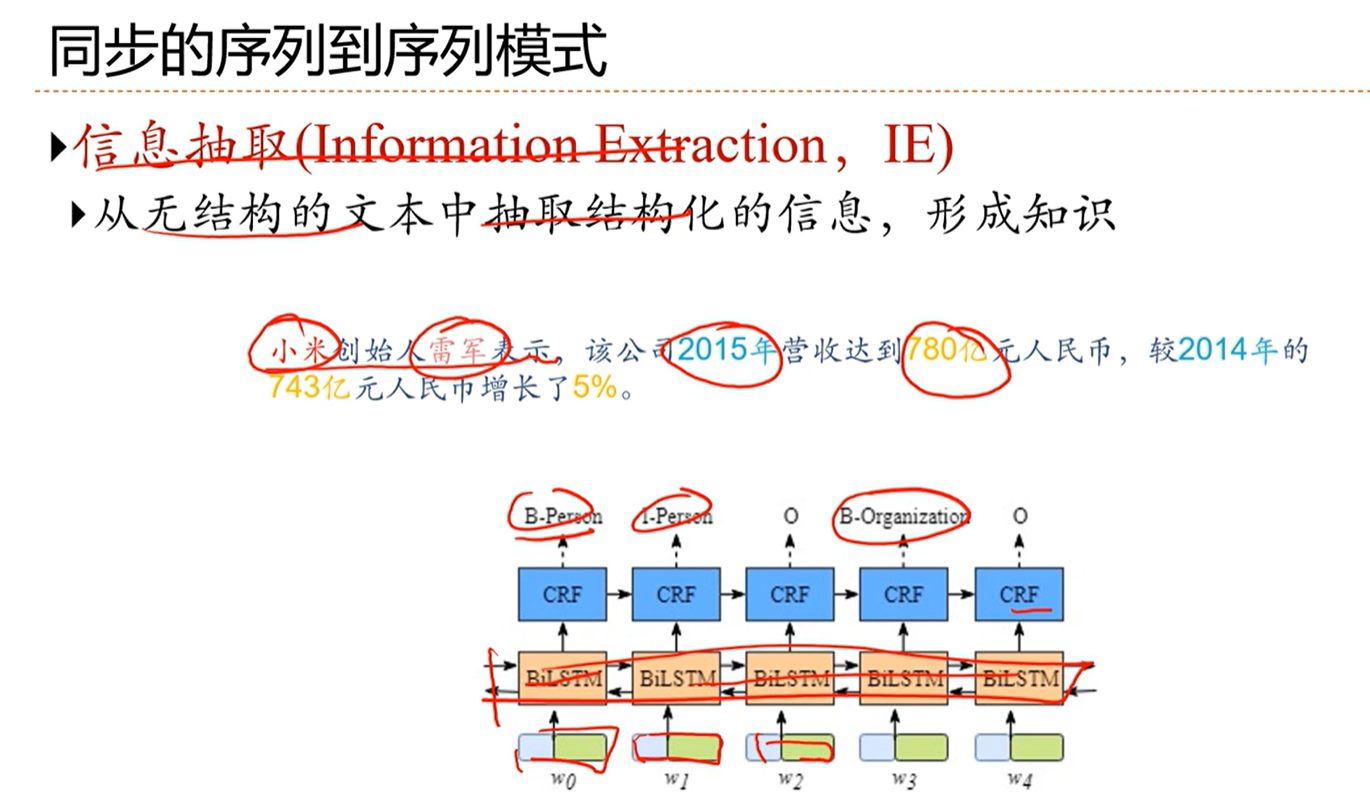
[√] 举例:信息抽取
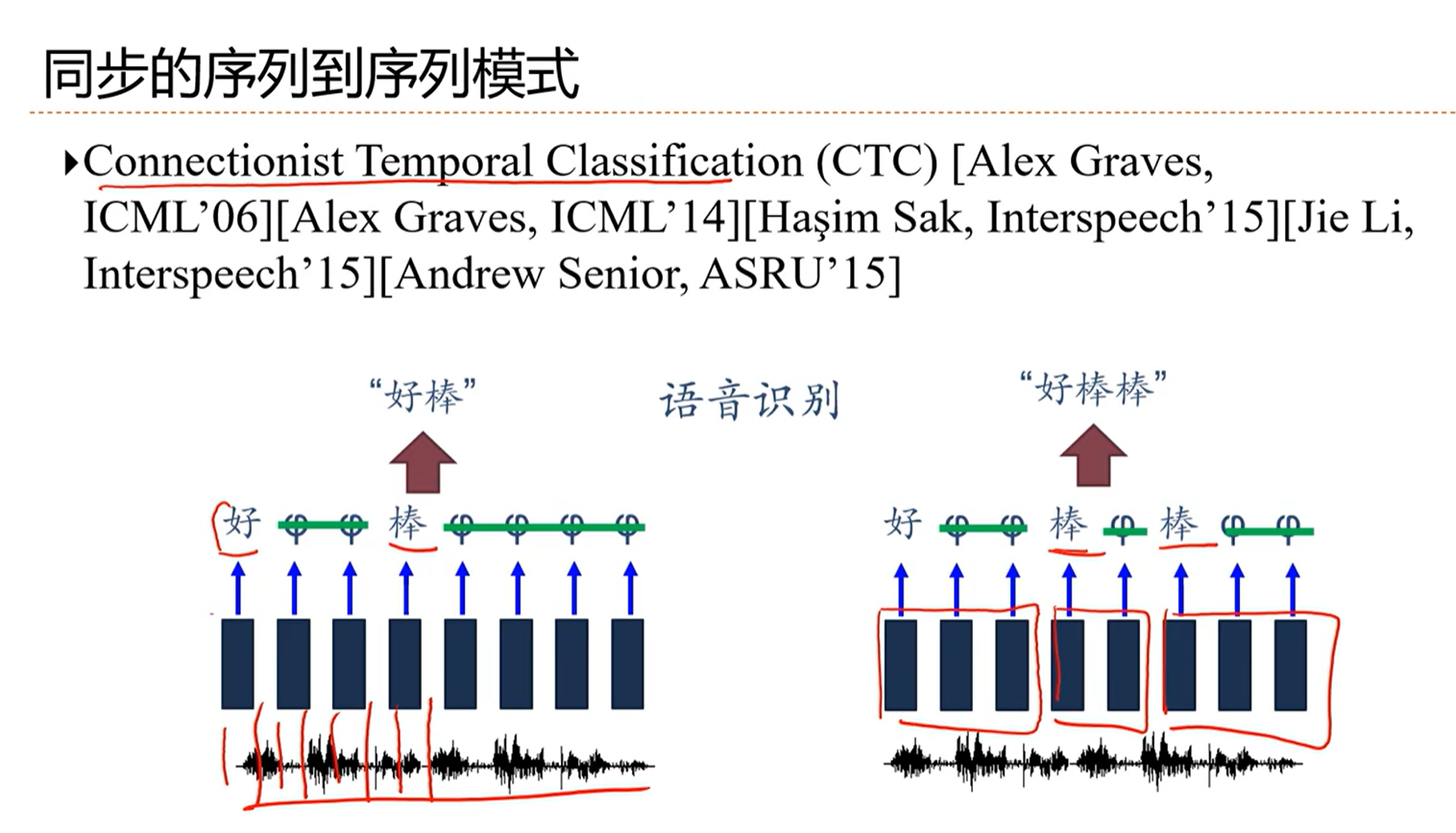
[√] 语音识别
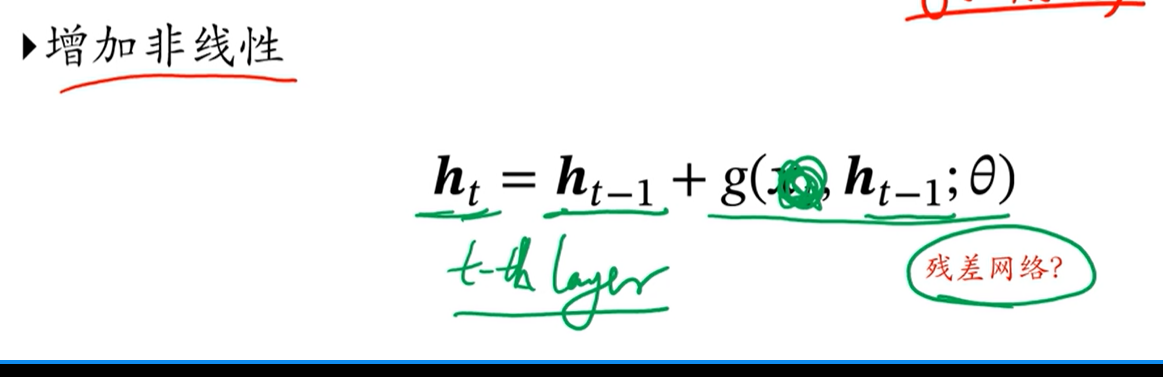
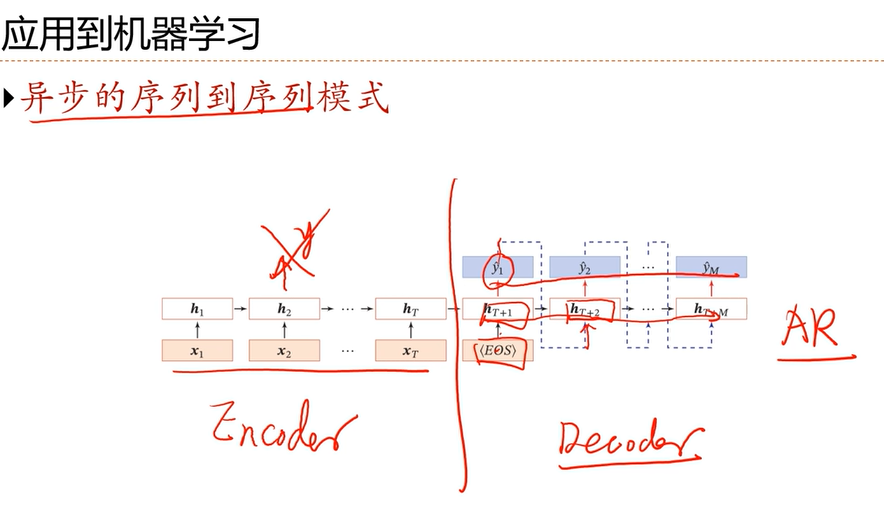
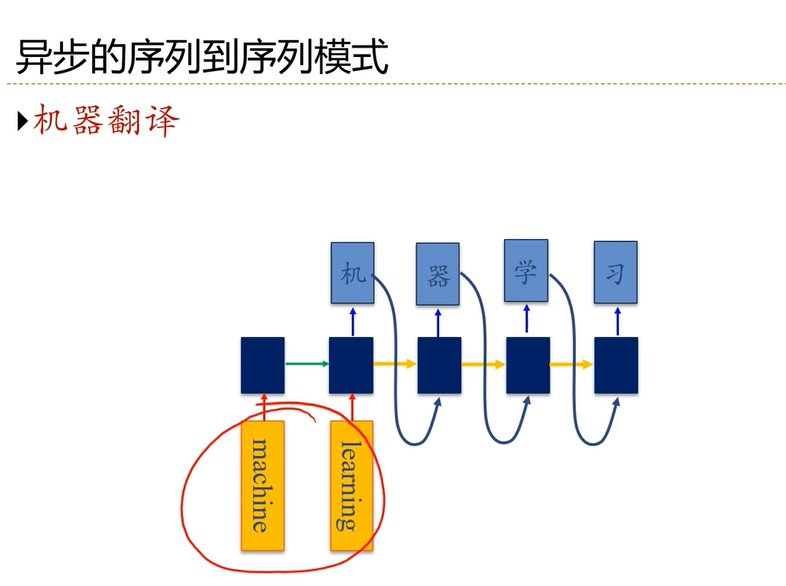
[√] 异步的序列到序列模式
是一个自回归模型,输入为编码,输出为解码。
decoder用了RNN、自回归
[√] 机器翻译
[√] 6.4 - 参数问题与长程依赖问题
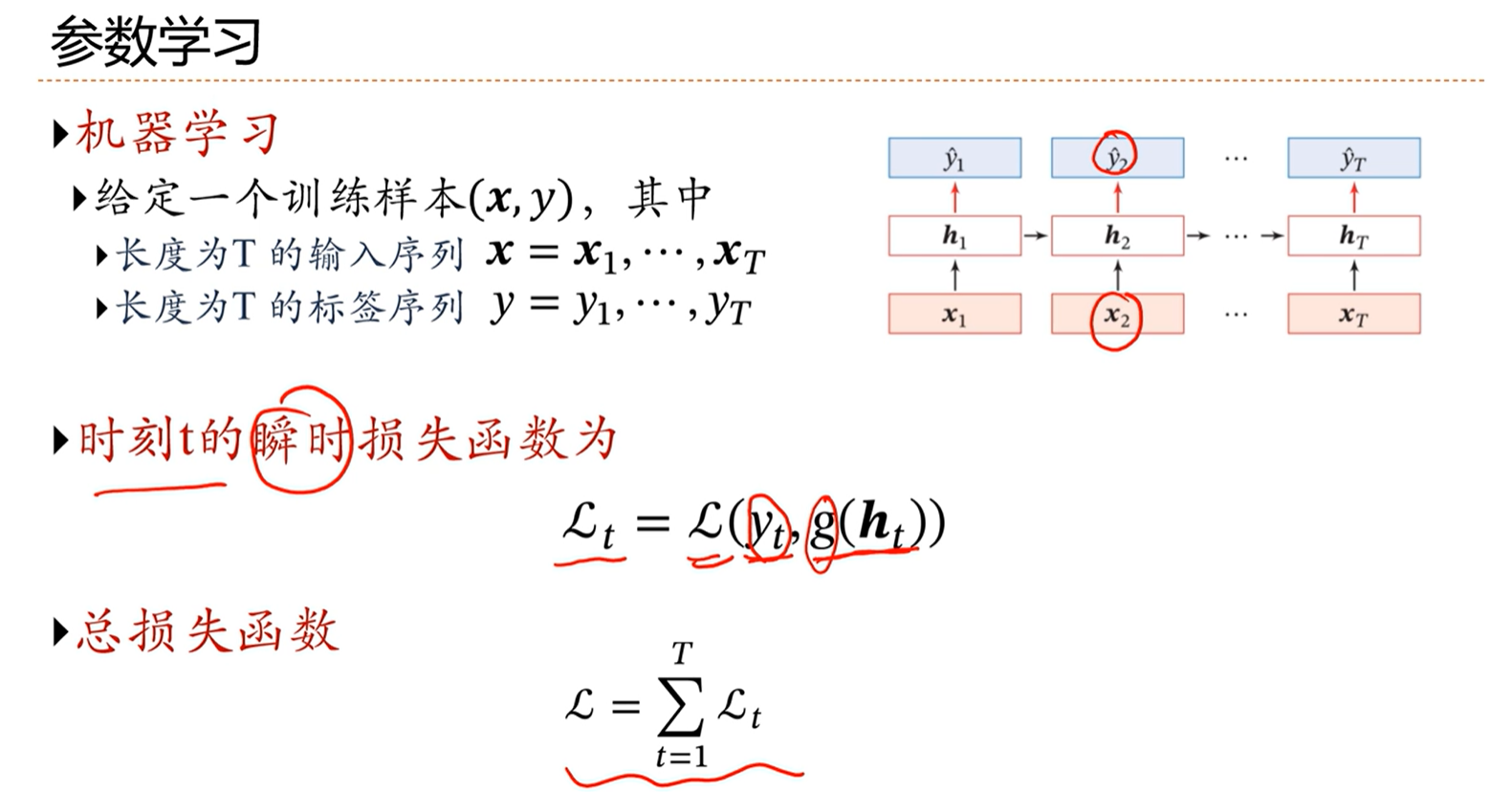
[√] 参数学习

alec:
通过状态单元h,计算得到预测标签y,然后真实标签和预测标签计算损失。其中状态单元是由当前的输入和之前的状态得到的。
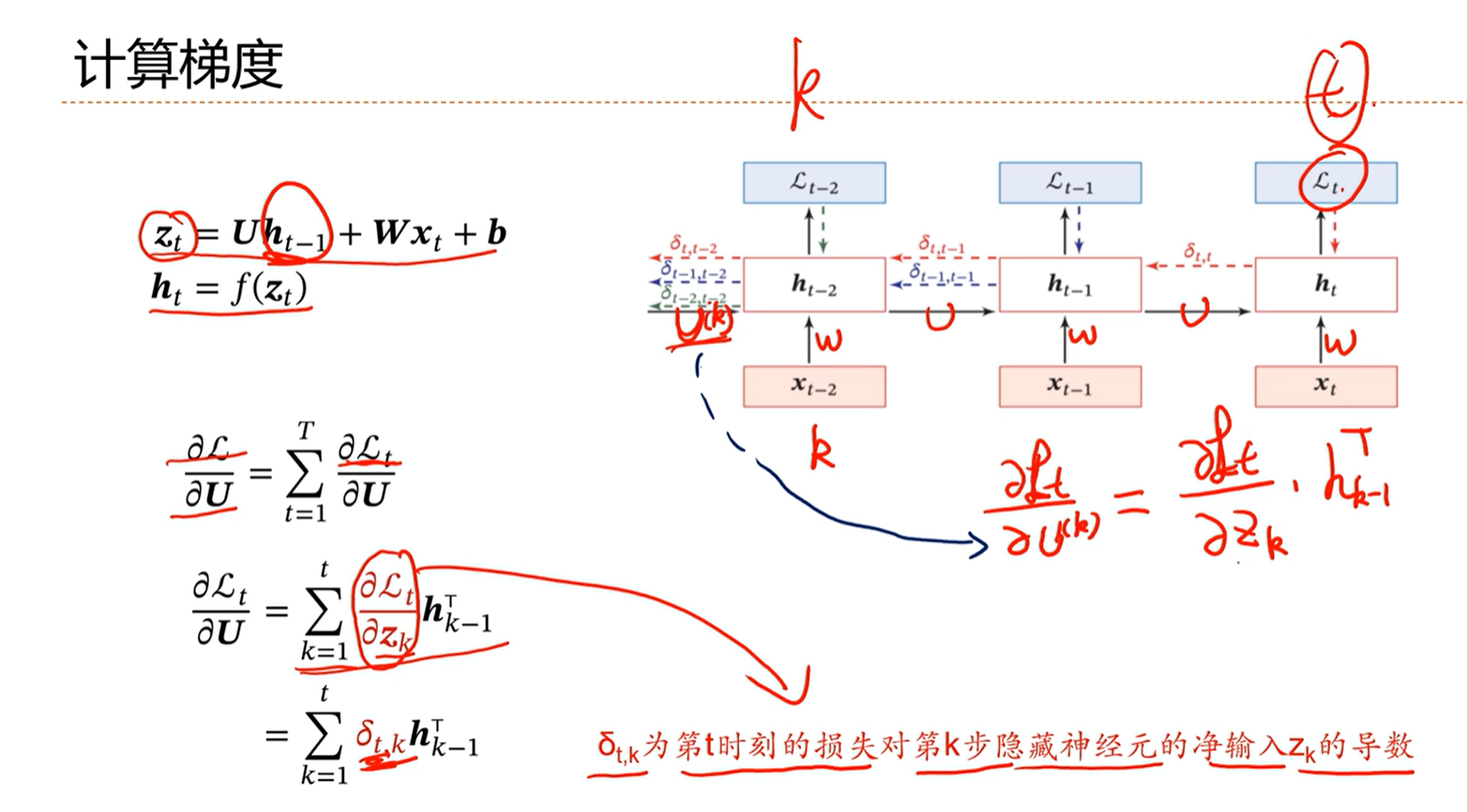
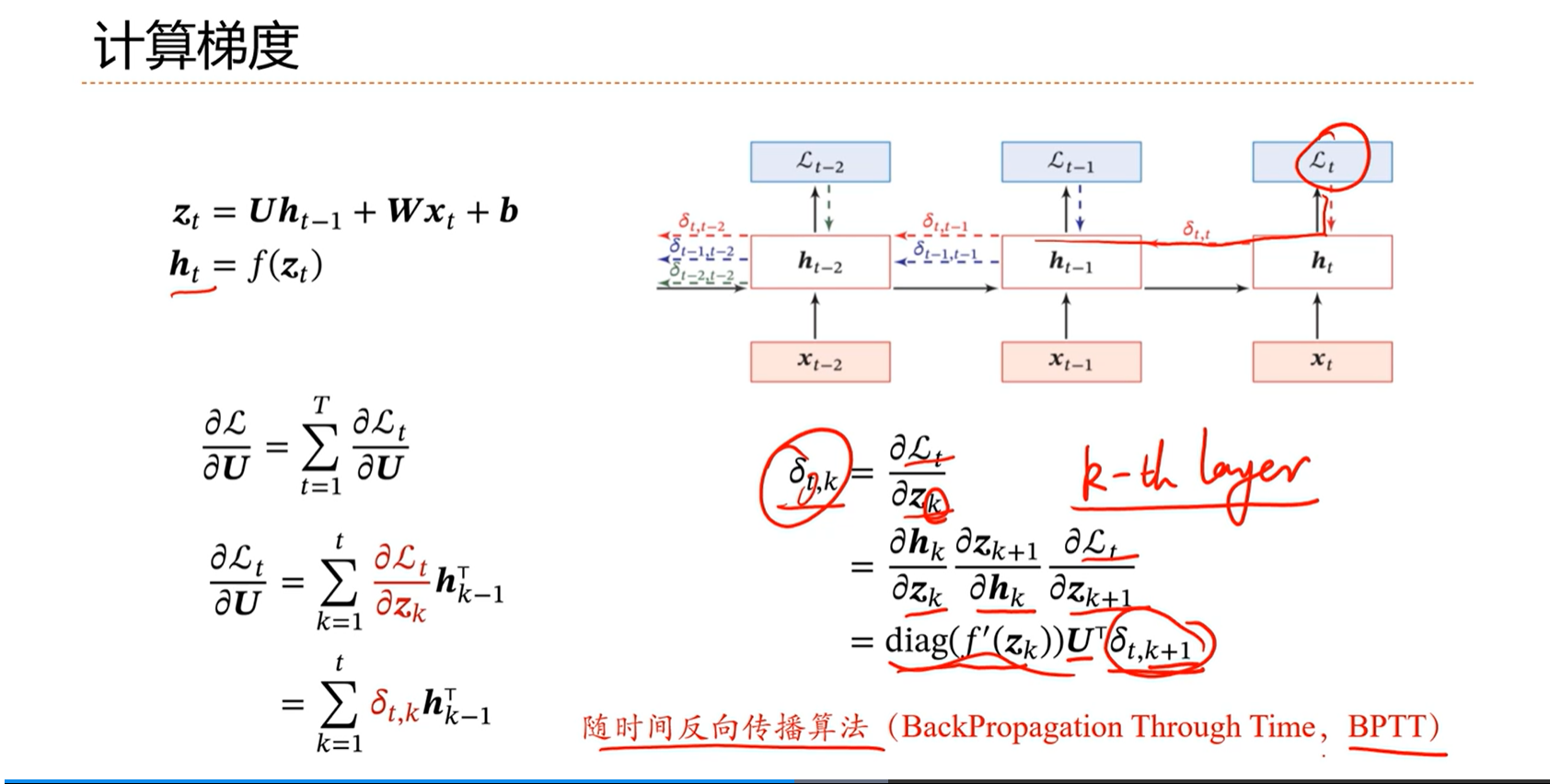
[√] 计算梯度
alec:
- 简单循环神经网络,SRN
- H
t-1、Xt、b通过线性计算得到Zt,Zt通过非线性函数,得到Ht- 类比得到,Zt看做净活性值、Ht看做激活值。

[√] 随时间的反向传播算法
[√] 梯度 和 长程依赖问题
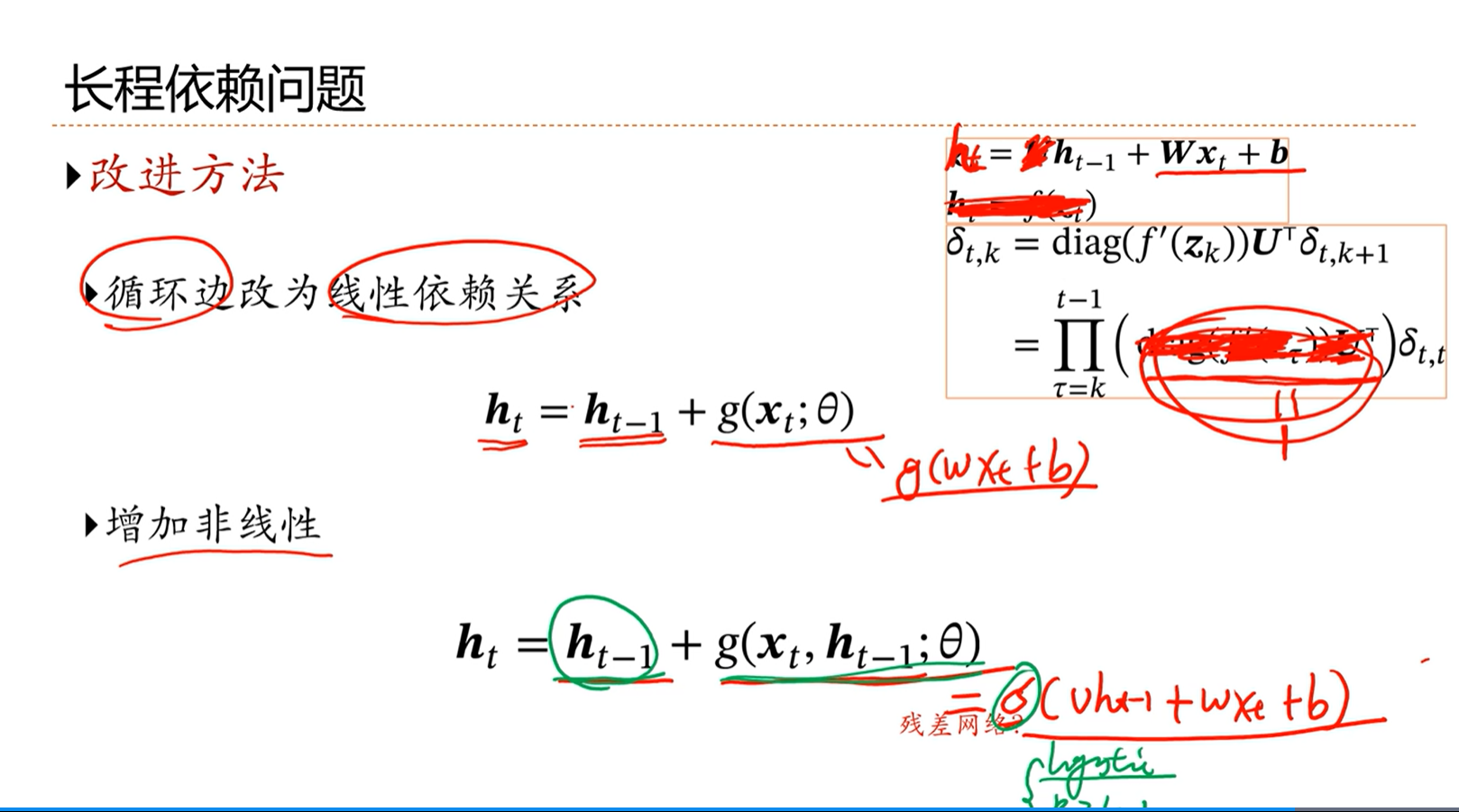
当 γ 大于1,t-k非常大的时候,梯度就是趋向于非常大,就会产生梯度爆炸问题。
当 γ 小于1,t-k非常大的时候,梯度就趋向于0,就会产生梯度消失问题。
因此SRN网络,当网络的深度很深的时候,就不好训练了。
虽然长周期之内存在依赖关系,但是由于长周期会有类似于梯度消失或者梯度爆炸问题,因此事实上只能学习到短周期的依赖关系,学不到长周期的依赖关系。
因为上图中损失函数对参数U的导数是一个对多个时刻的梯度求和,因此虽然单个存在梯度消失问题,但是总体上不会存在梯度消失问题,因为长距离内会梯度消失,但是短距离内不会梯度消失。这种现象就会导致参数只能学习到短周期内的,无法学习到长周期内的。
alec:
问题思考:如何不发生梯度消失后者梯度爆炸呢?
答:令梯度公式中的γ等于1,就不会产生梯度问题了。
[√] 6.5 - 如何解决长程依赖问题?
[√] 长程依赖问题
梯度爆炸问题,相对来说比较容易解决。
[√] 改进方法
方法1:循环边改为线性依赖关系
- 这种方式解决了长程依赖问题,但是模型能力就变弱了
方法2:进一步改进,增加非线性
- 后面一项保证了非线性关系,同时前面一项保证了倒数为有1不会发生梯度消失等问题
- 这个式子的问题在于,非常容易饱和,饱和之后,非线性函数的值都是一样的,因此会导致信息的差别越来越小
- 解决办法是想办法主动的去丢弃一些东西,即接下来要讲的基于门控的方法
这种结构和残差网络非常像。因此解决梯度问题,无论是在前馈神经网络还是循环神经网络,原理都是非常类似的。
[√] 6.6 - GRU 和 LSTM
两个可以有效缓解长程依赖问题的模型:GRU 和 LSTM
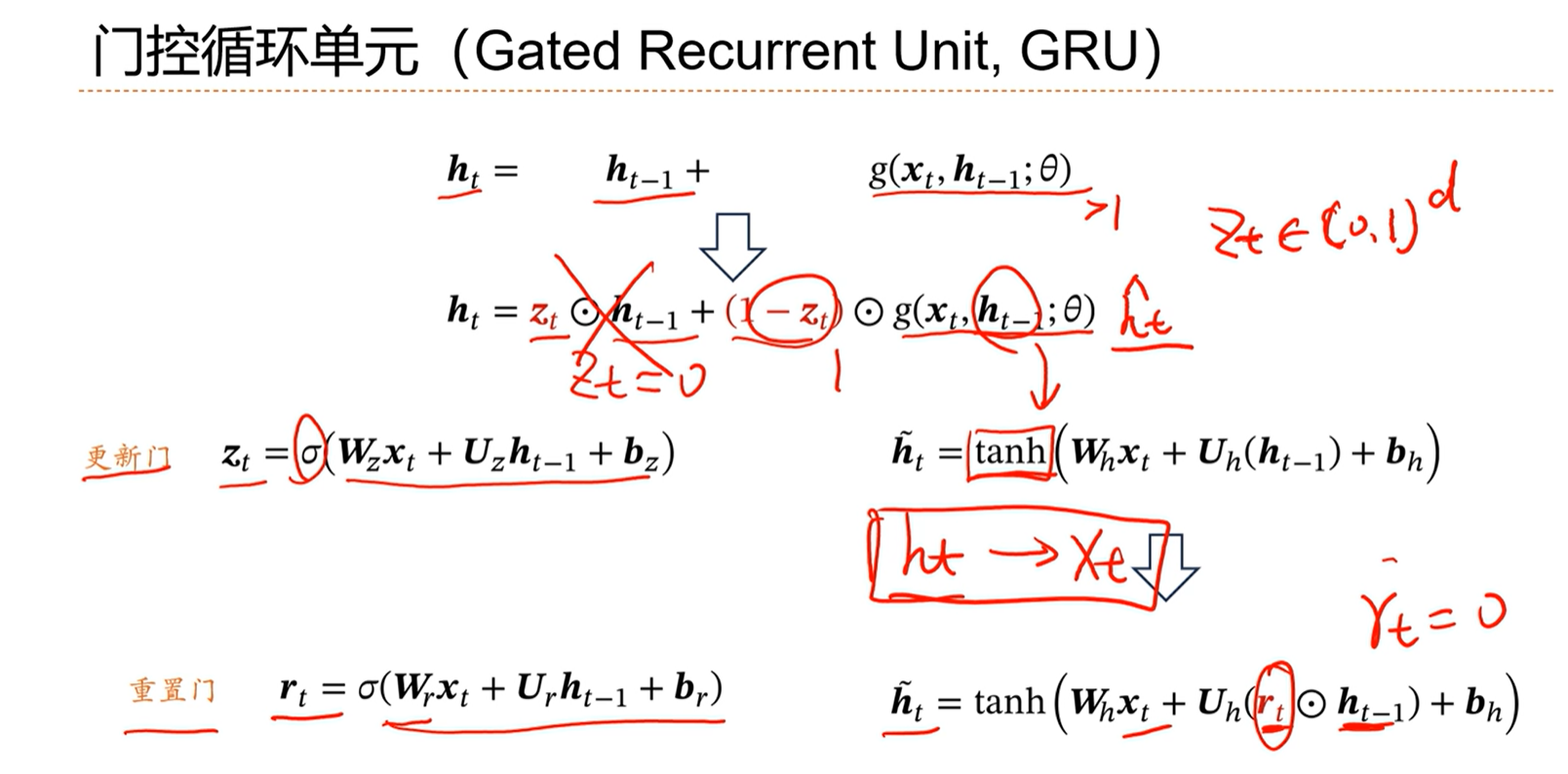
[√] 门控机制

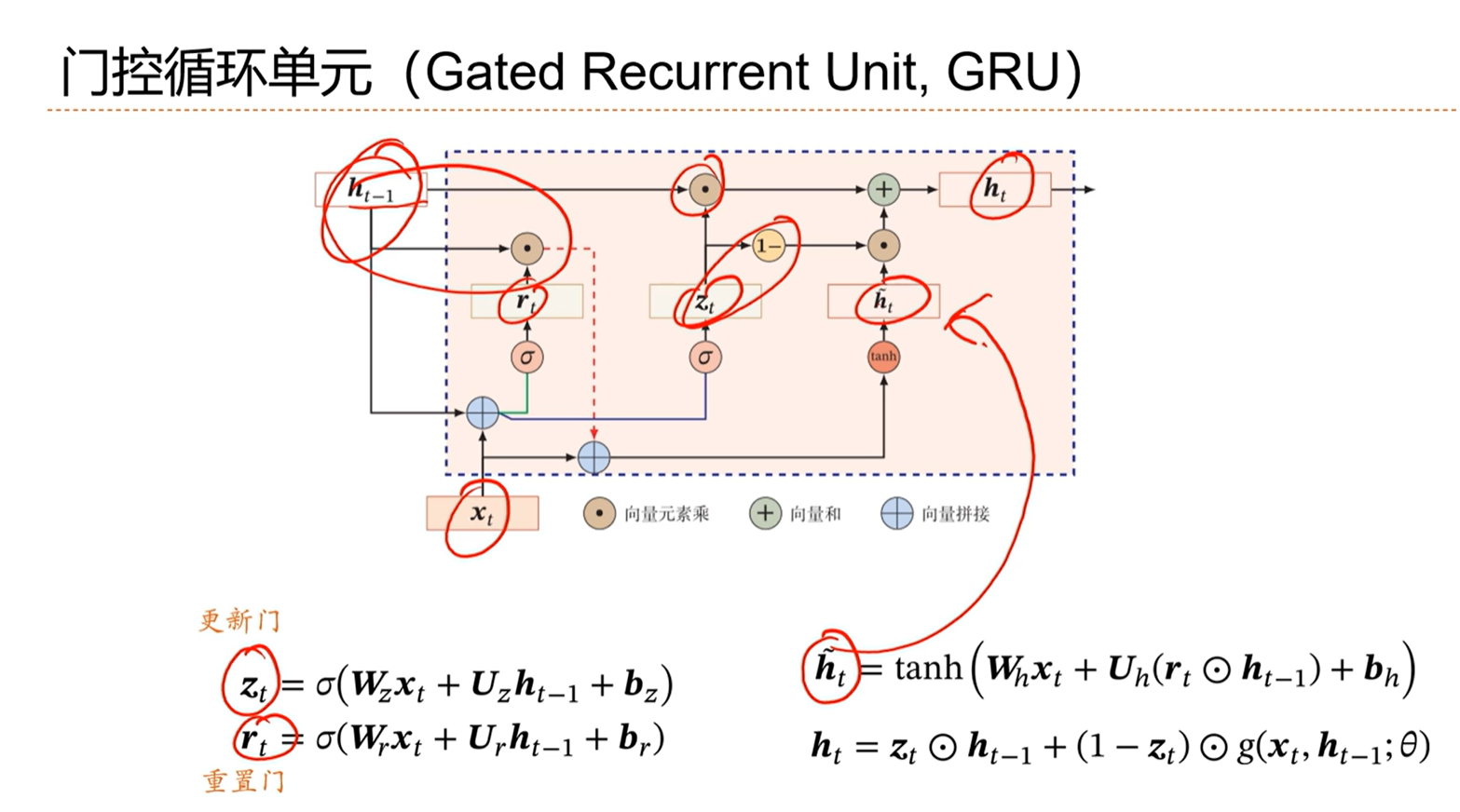
[√] 门控循环单元,GRU
如果后面这个非线性部分一直大于0的话,那么这个整体就会越来越大,然后通过非线性函数之后,可能就会走到梯度的饱和问题,最终不利于参数的学习。
因此引入门控机制,让这个ht不要太大。

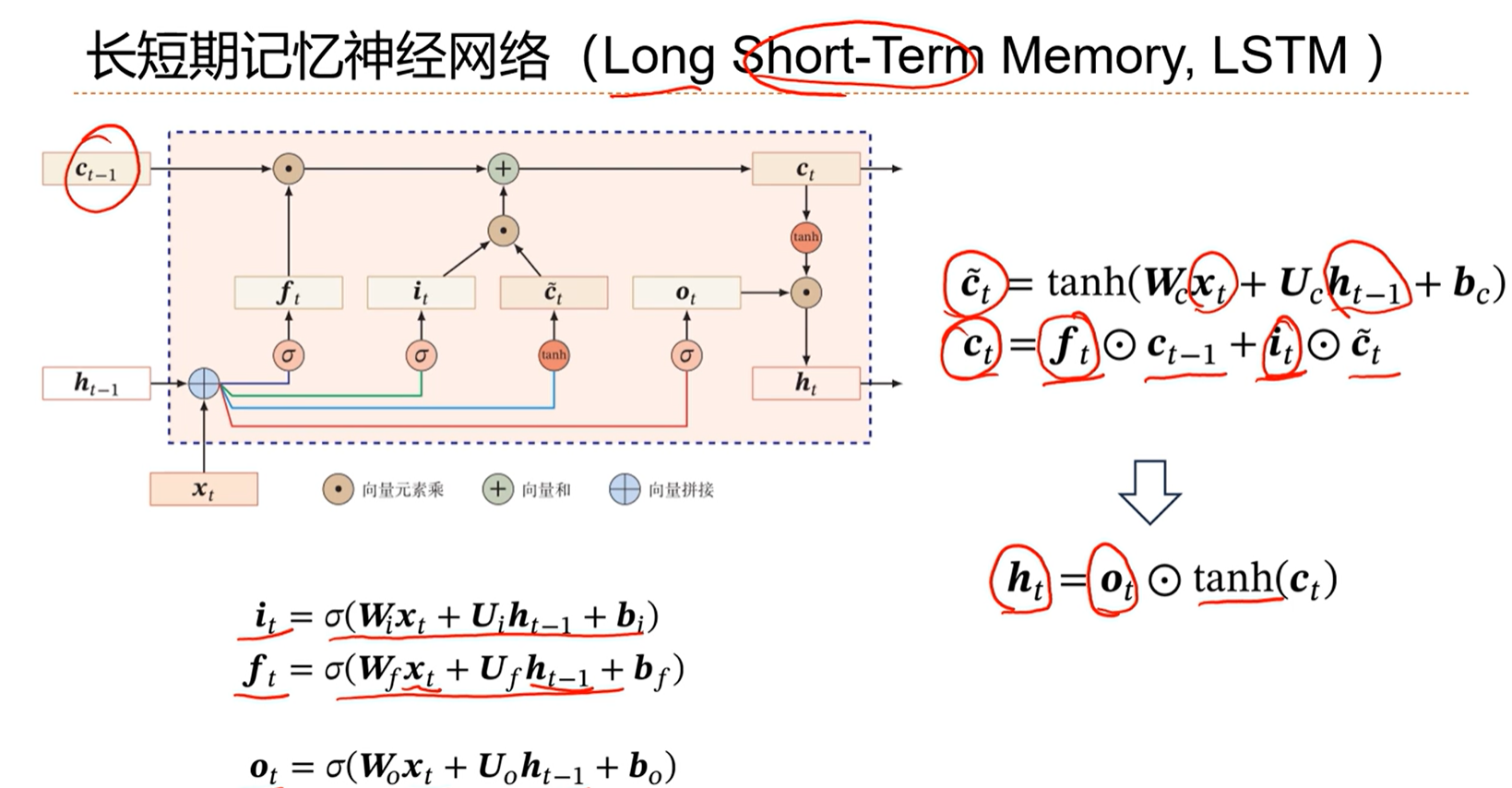
[√] 长短期记忆神经网络(LSTM)
这个网络引入了内部记忆单元 c ,用c来传递线性依赖关系。
通过线性+非线性计算得到当前时刻暂时的记忆单元c_t’,然后还有上一个时刻的记忆单元c_t-1,然后通过两个门控遗忘门f_t和输入门i_t控制这两个记忆单元的大小。
将被门控后的这两个记忆单元相加,得到当前时刻的记忆单元c_t。
然后将c_t通过非线性单元,并乘上一个输出门o_t,得到了第t个时刻我们要的最终的状态h_t。
遗忘门用于控制上一个时刻的记忆单元的传达阀门
输入门用于控制当前输入等计算得到的记忆单元的传递阀门
输出门用于控制最终的输出的非线性的传递阀门
[√] LSTM的各种变体

最初提出的时候,是没有遗忘门,但是发现这样效果不太好,所以就将遗忘门加上了。
[√] 6.7 - 深层循环神经网络
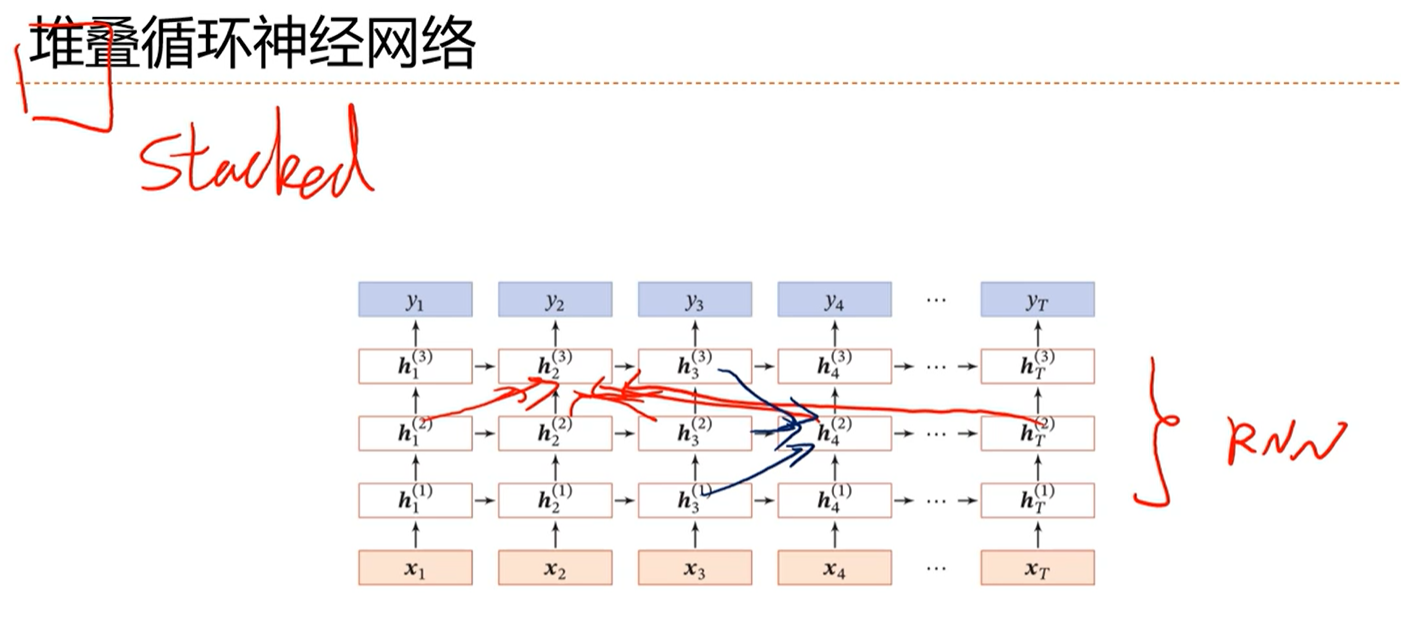
[√] 堆叠RNN
堆叠的神经网络,一种使得RNN变深的网络。
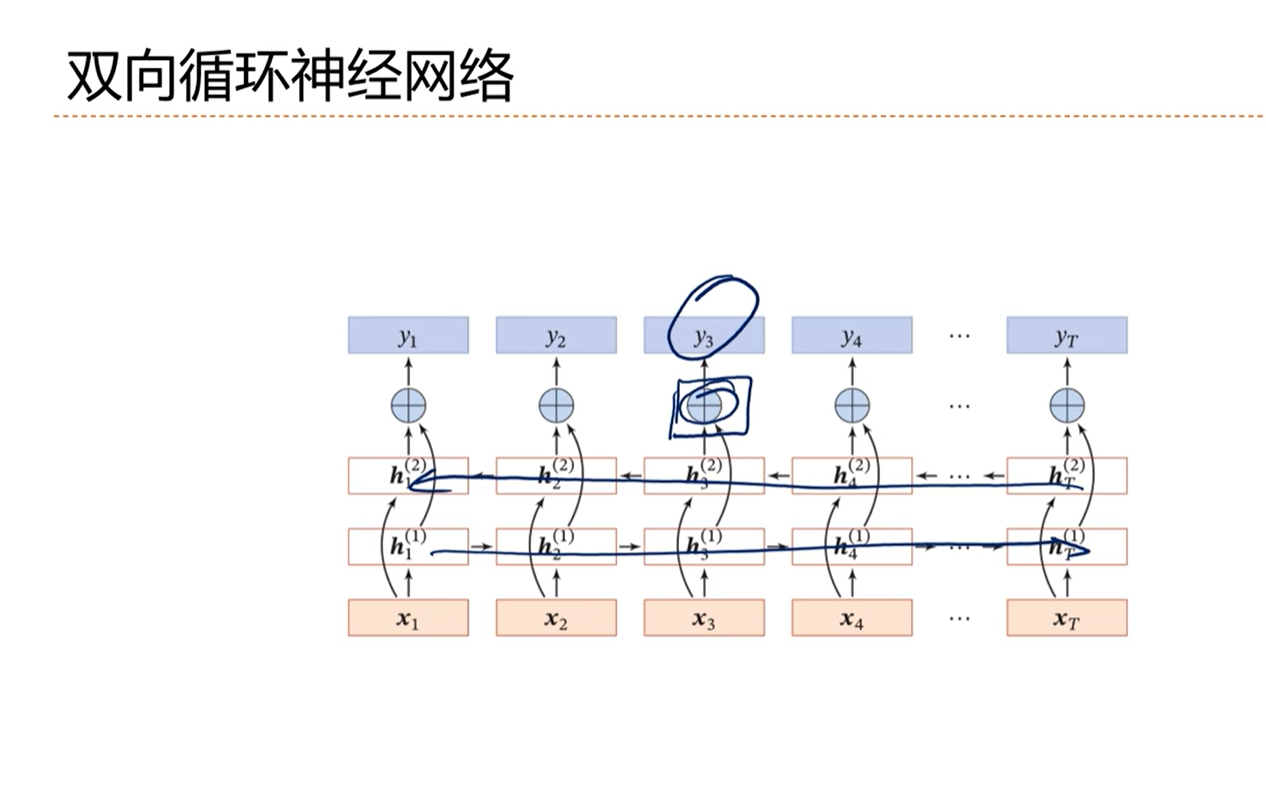
[√] 双向RNN
双向循环神经网络已经成为语音识别、机器翻译、文本分类等的标配模型
[√] RNN小结
[√] 6.8 - RNN应用
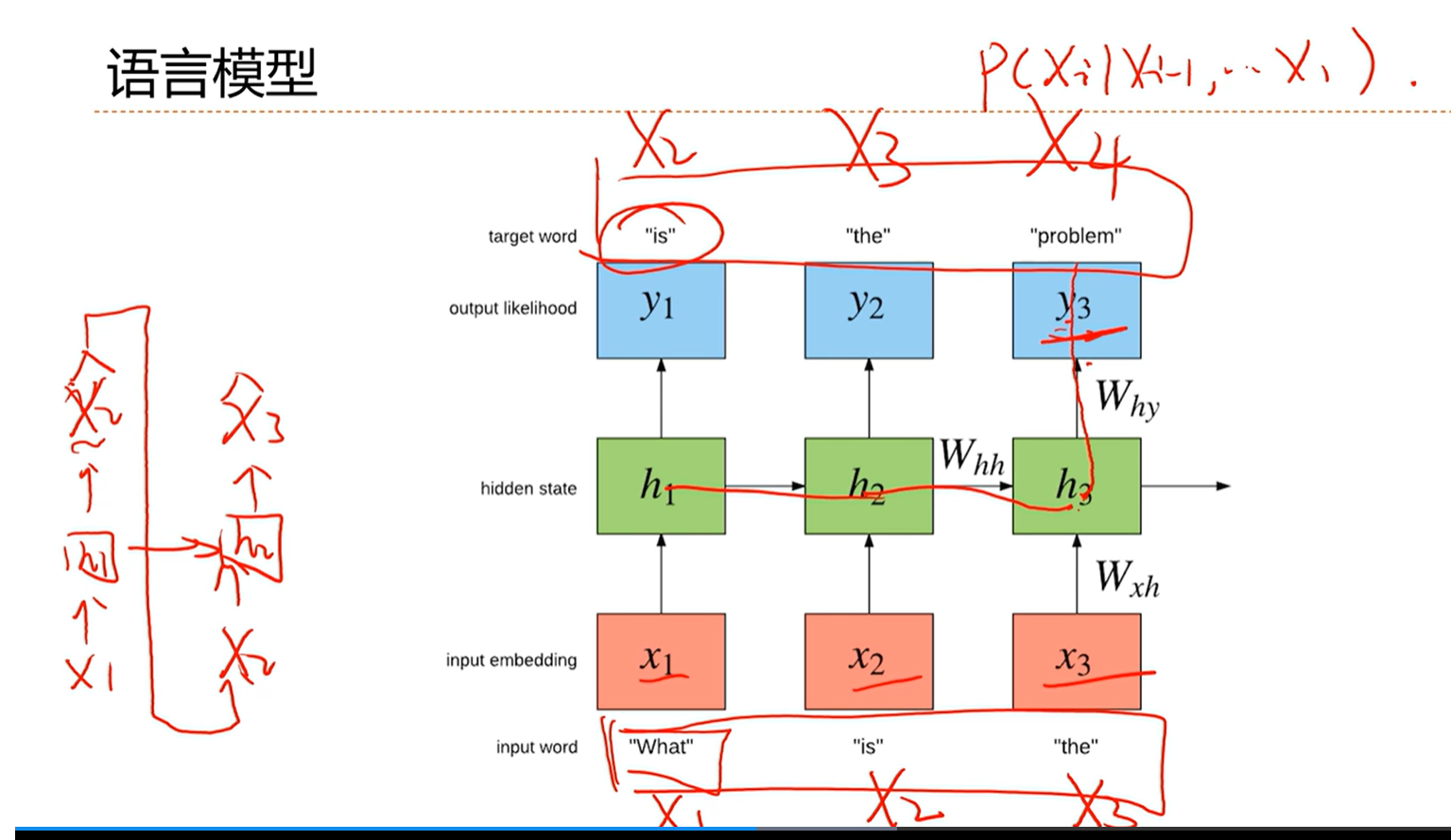
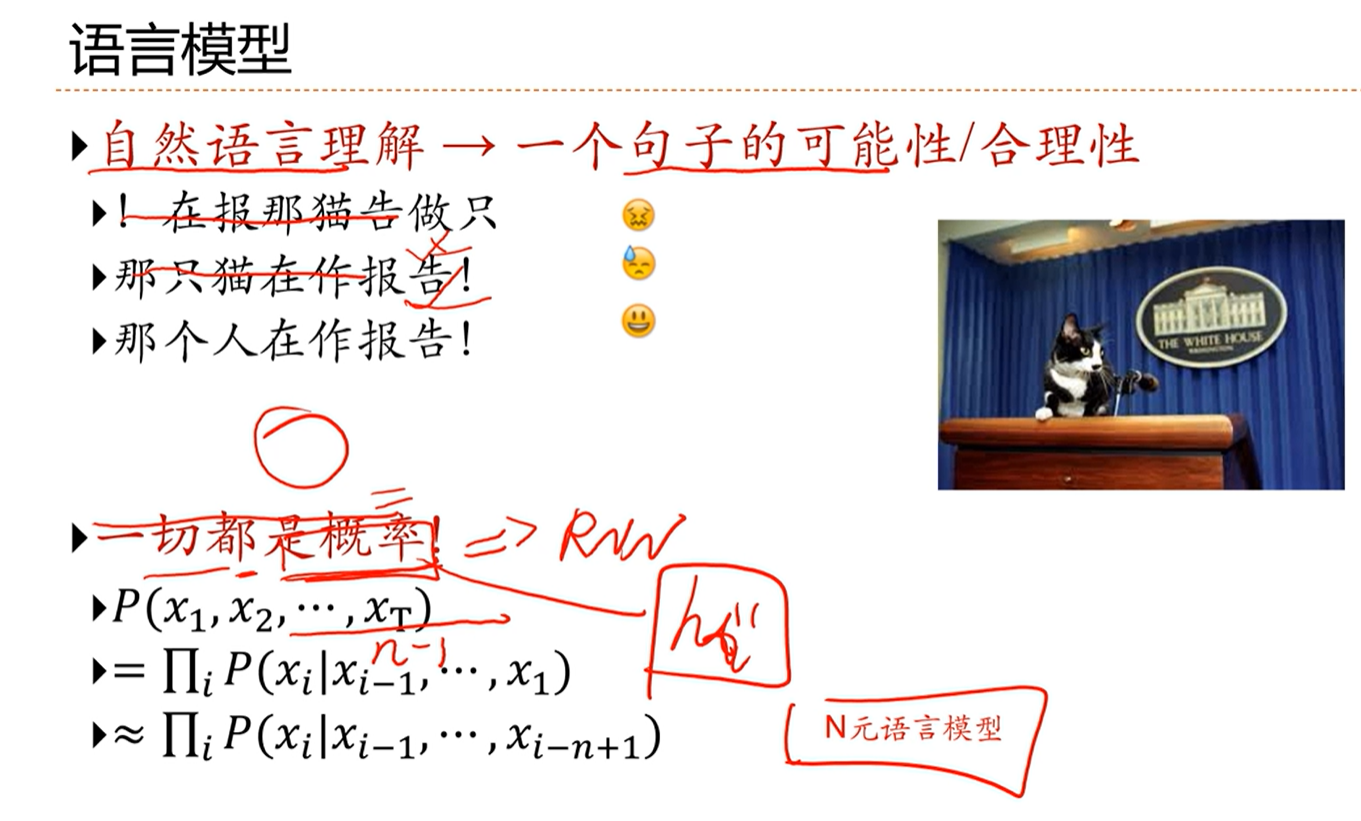
[√] 语言模型
[√] 生成Linux内核代码
[√] 作词机
[√] 作诗
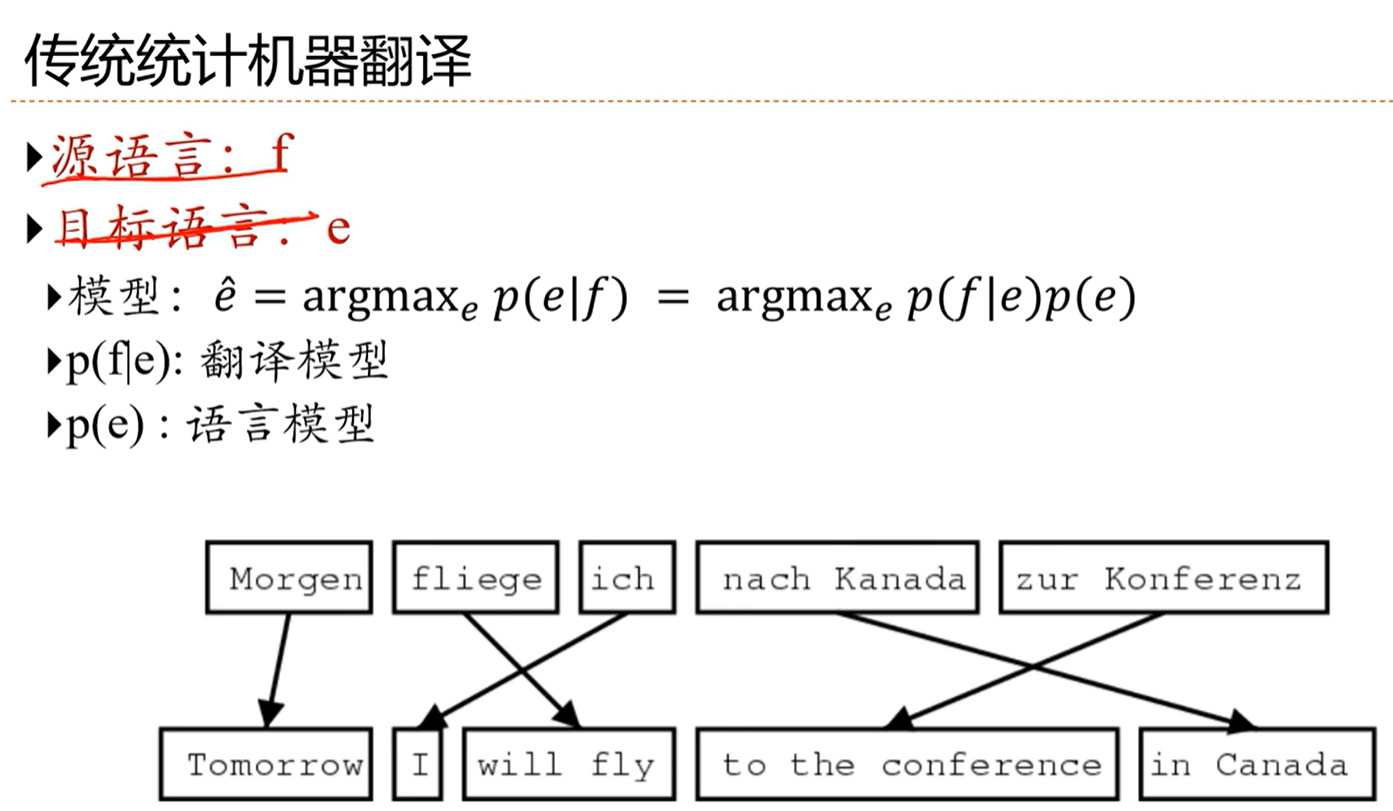
[√] 传统统计机器翻译
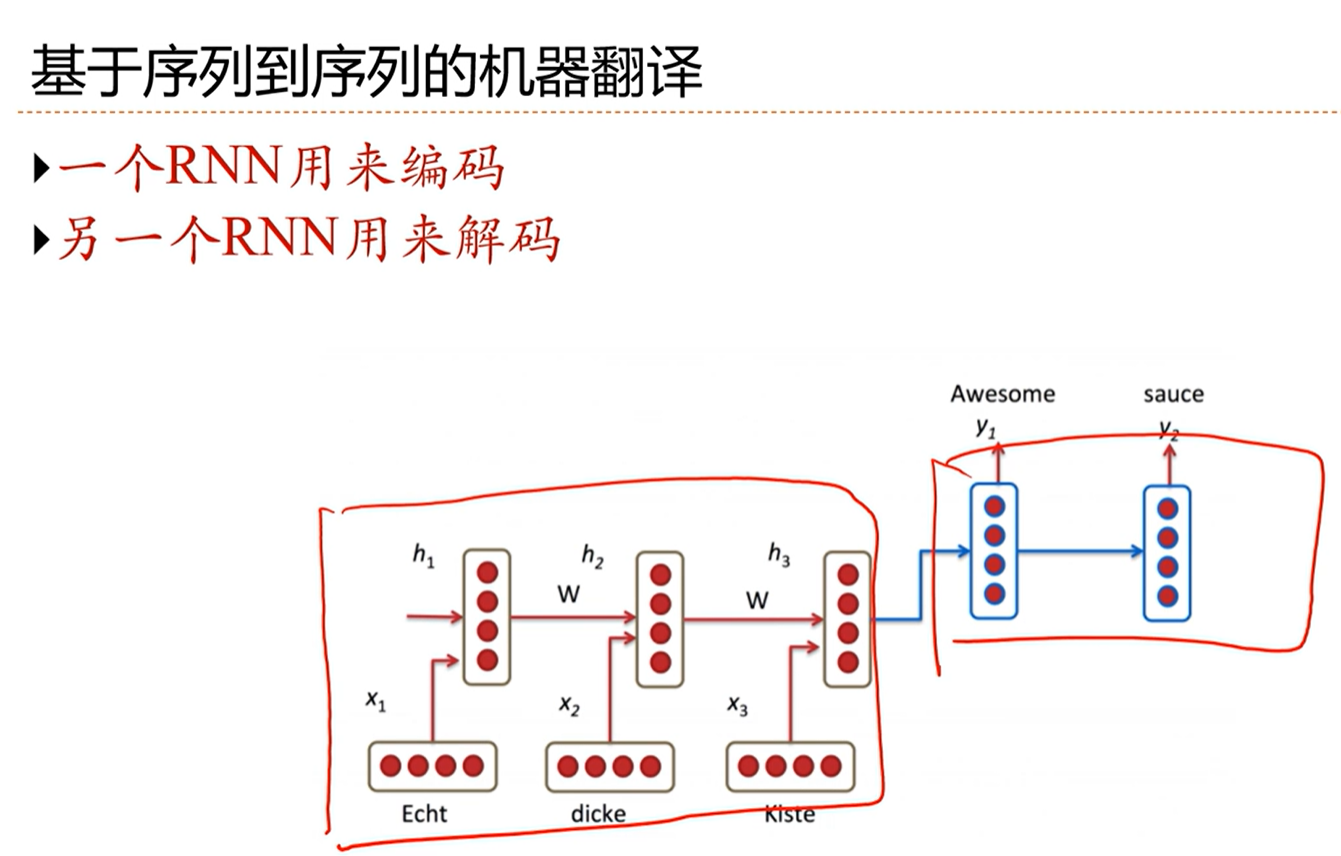
[√] 基于序列到序列的机器翻译
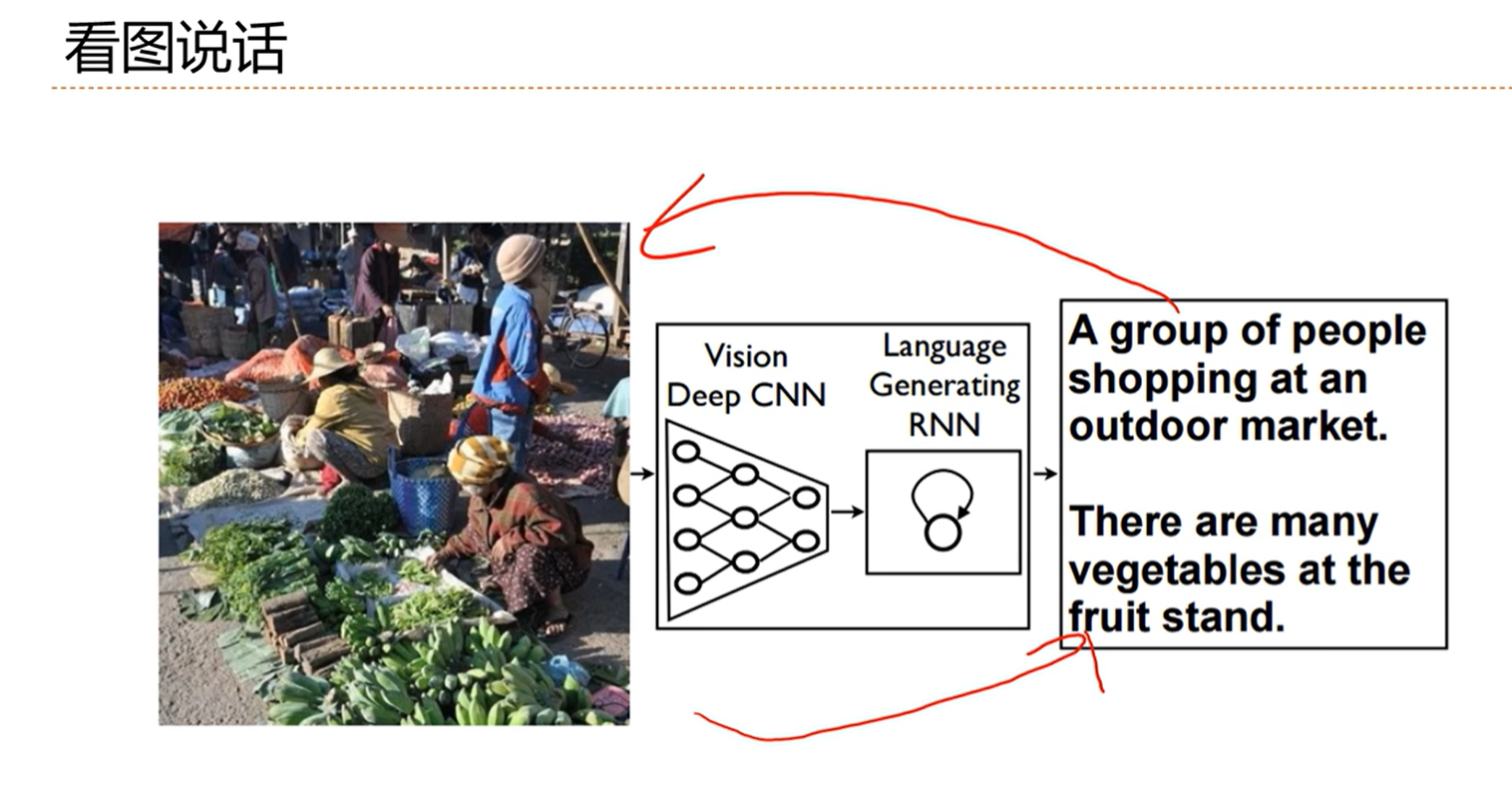
[√] 看图说话

编码的时候使用CNN,解码的时候使用RNN

[√] 写字
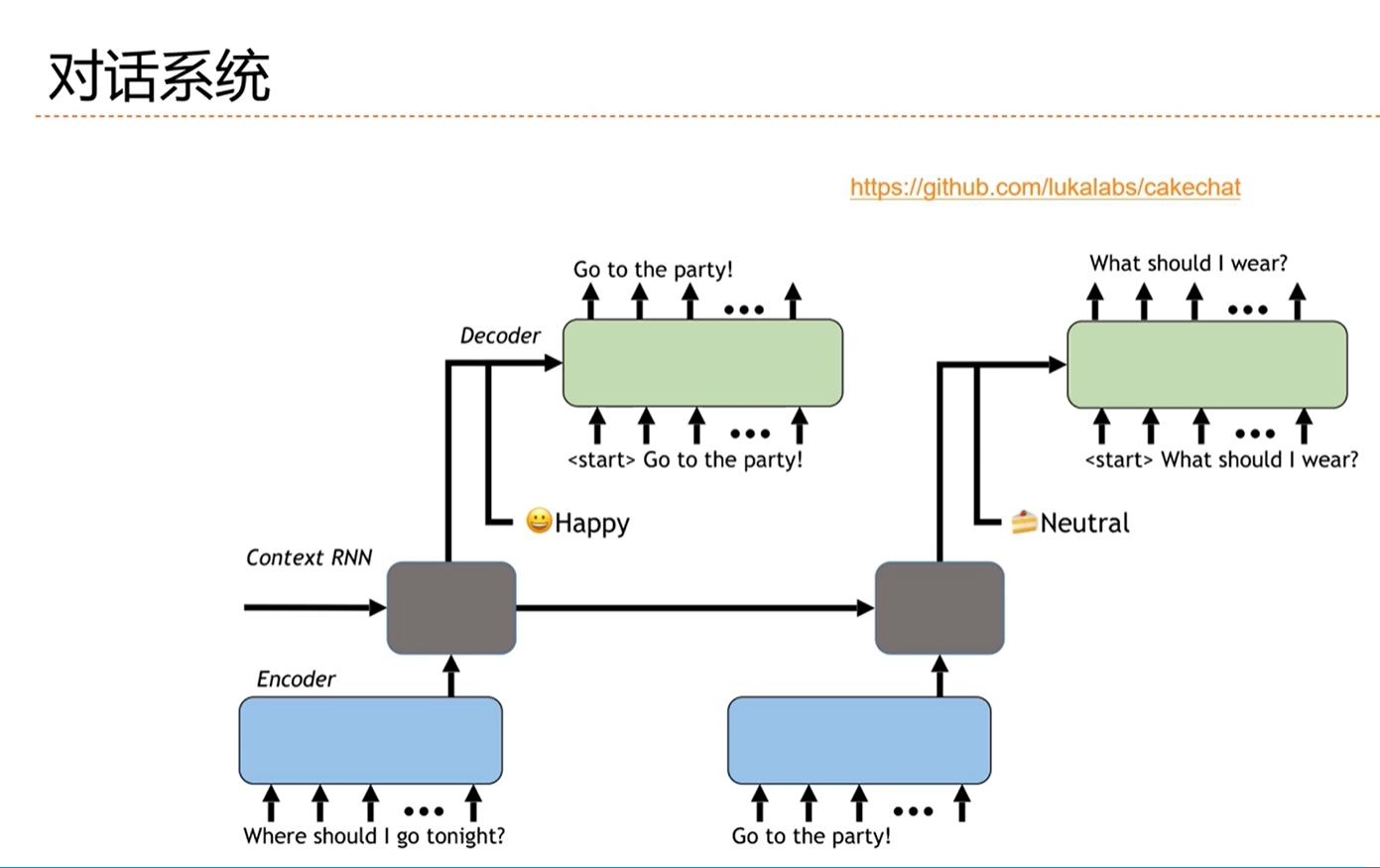
[√] 对话系统

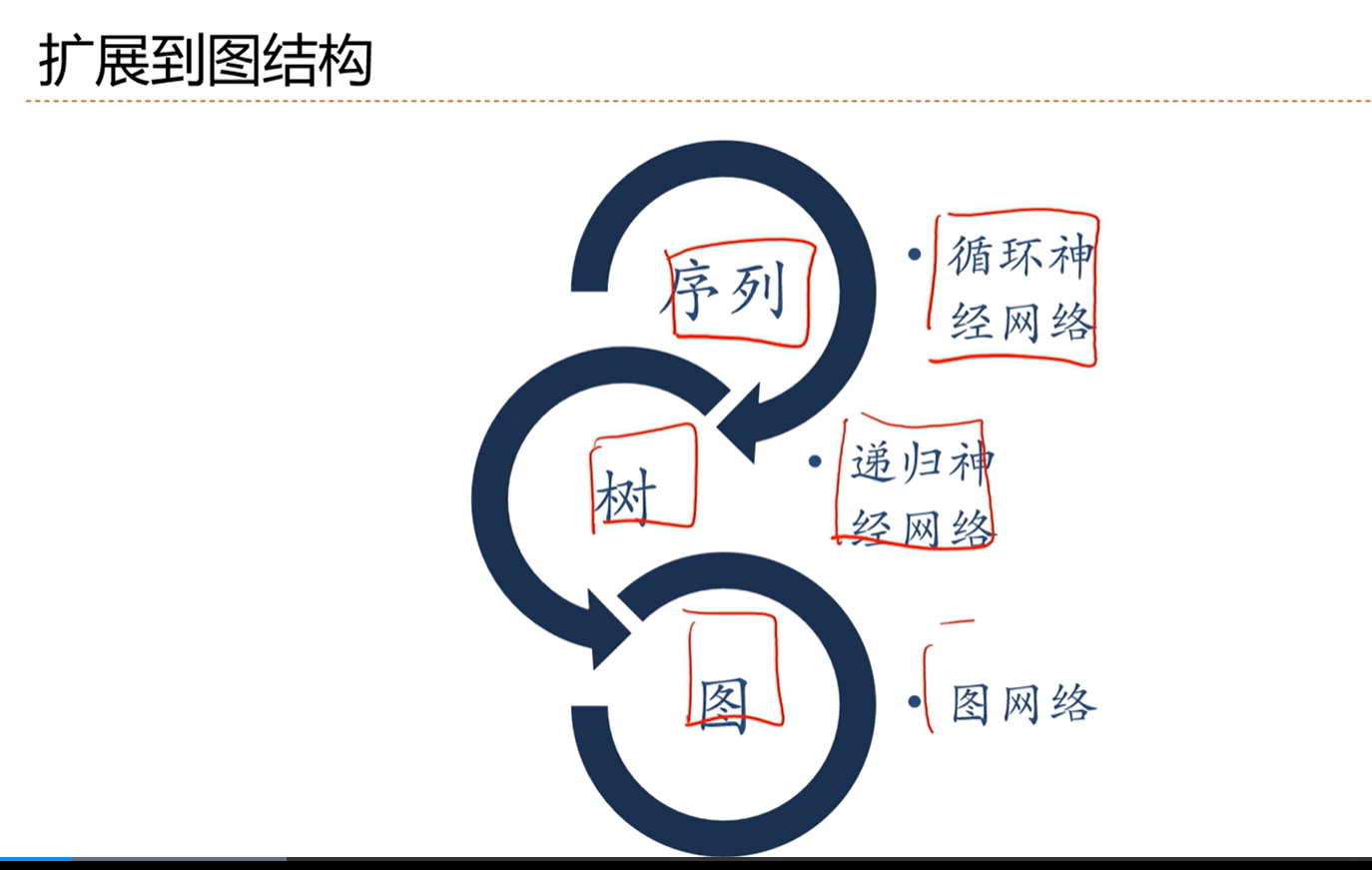
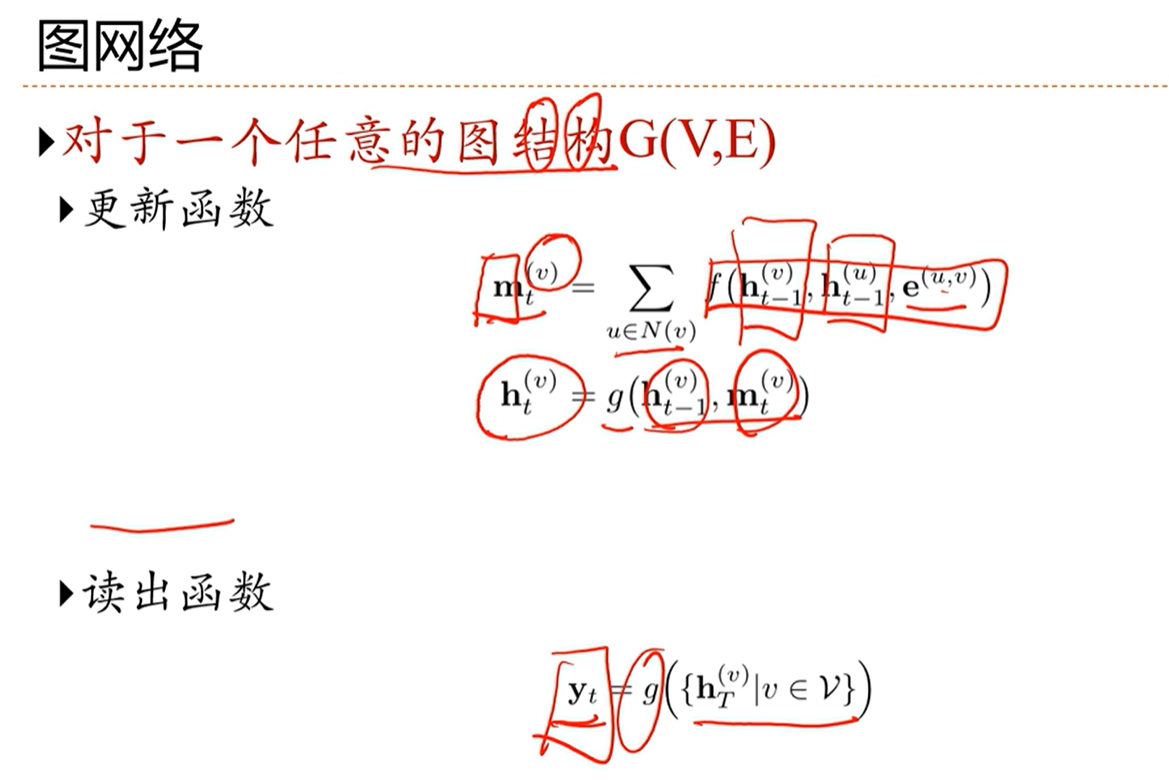
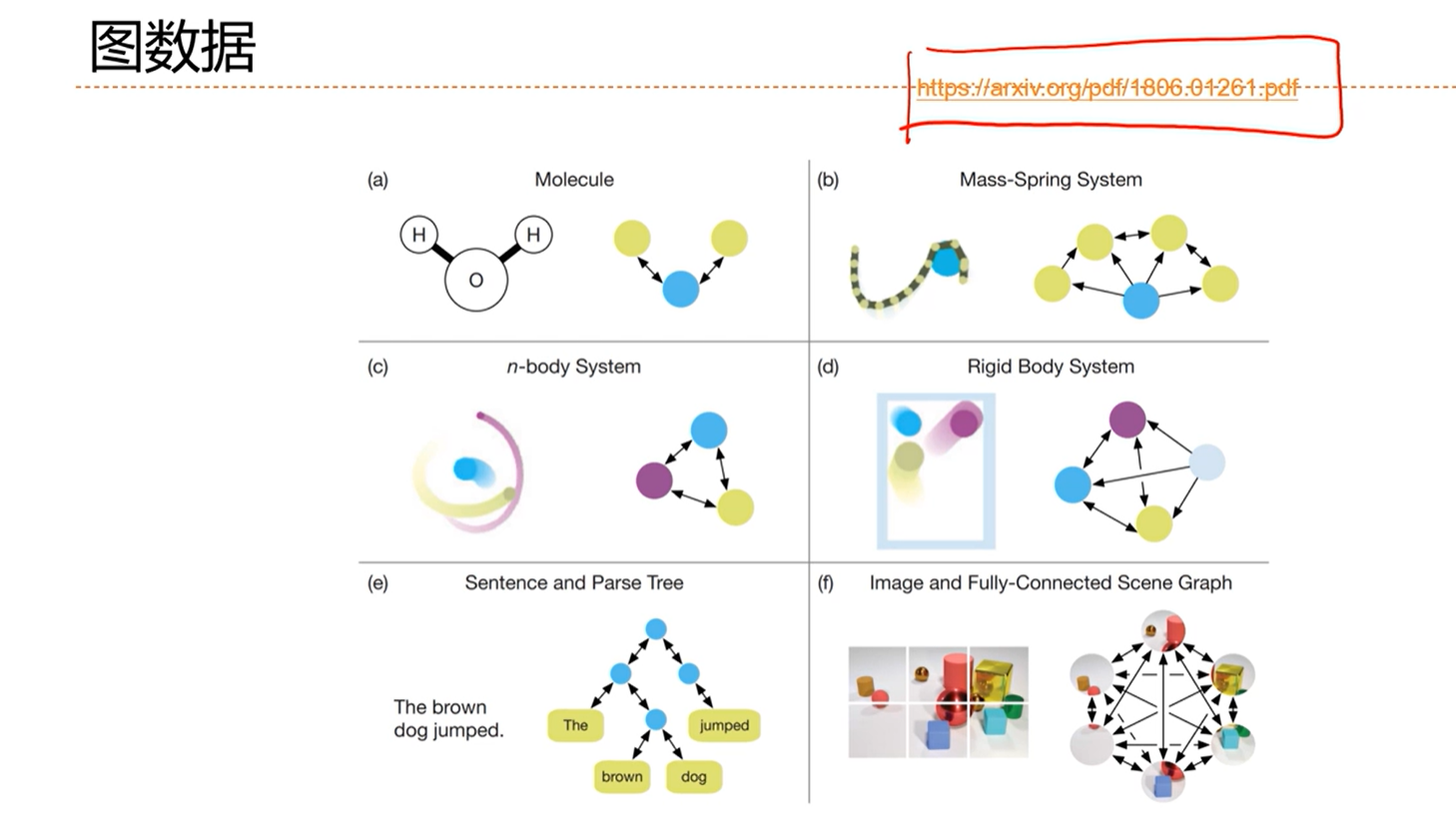
[√] 6.9 - 扩展到图结构
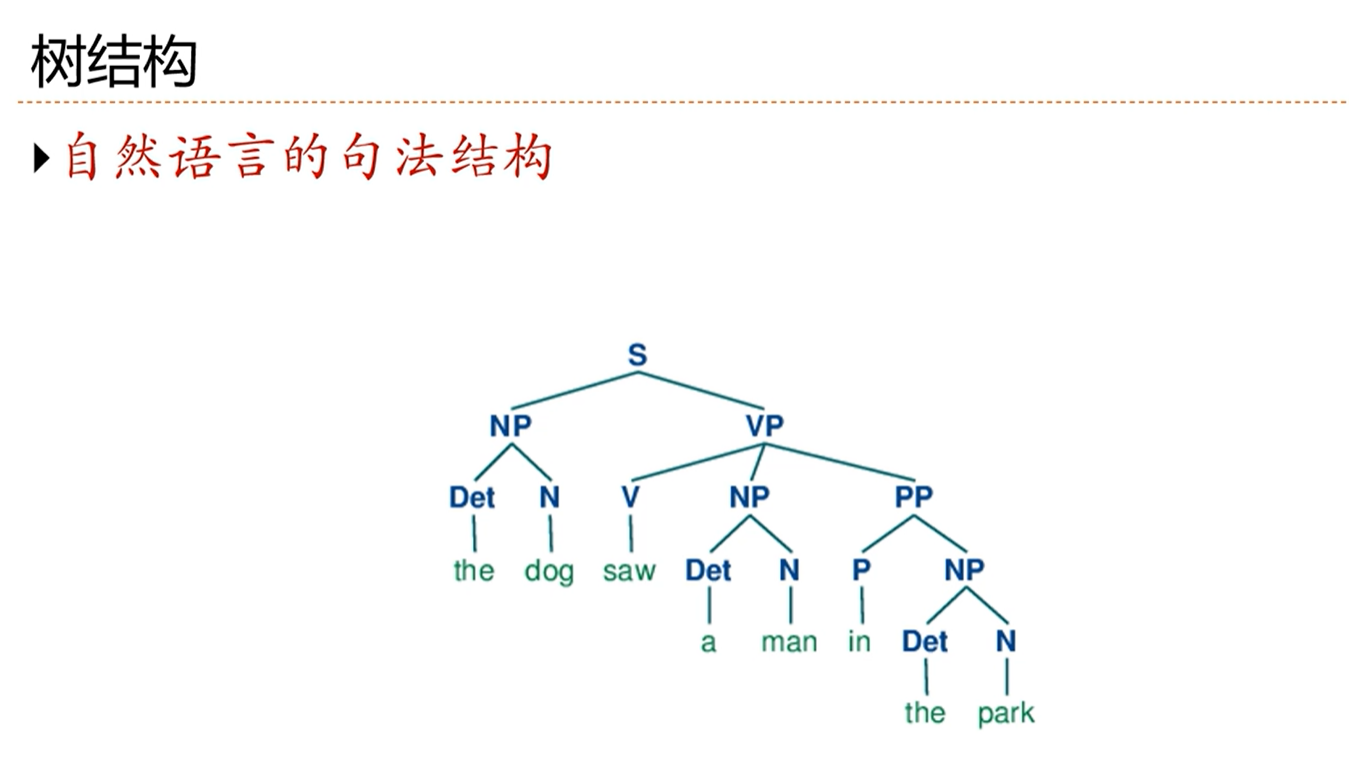
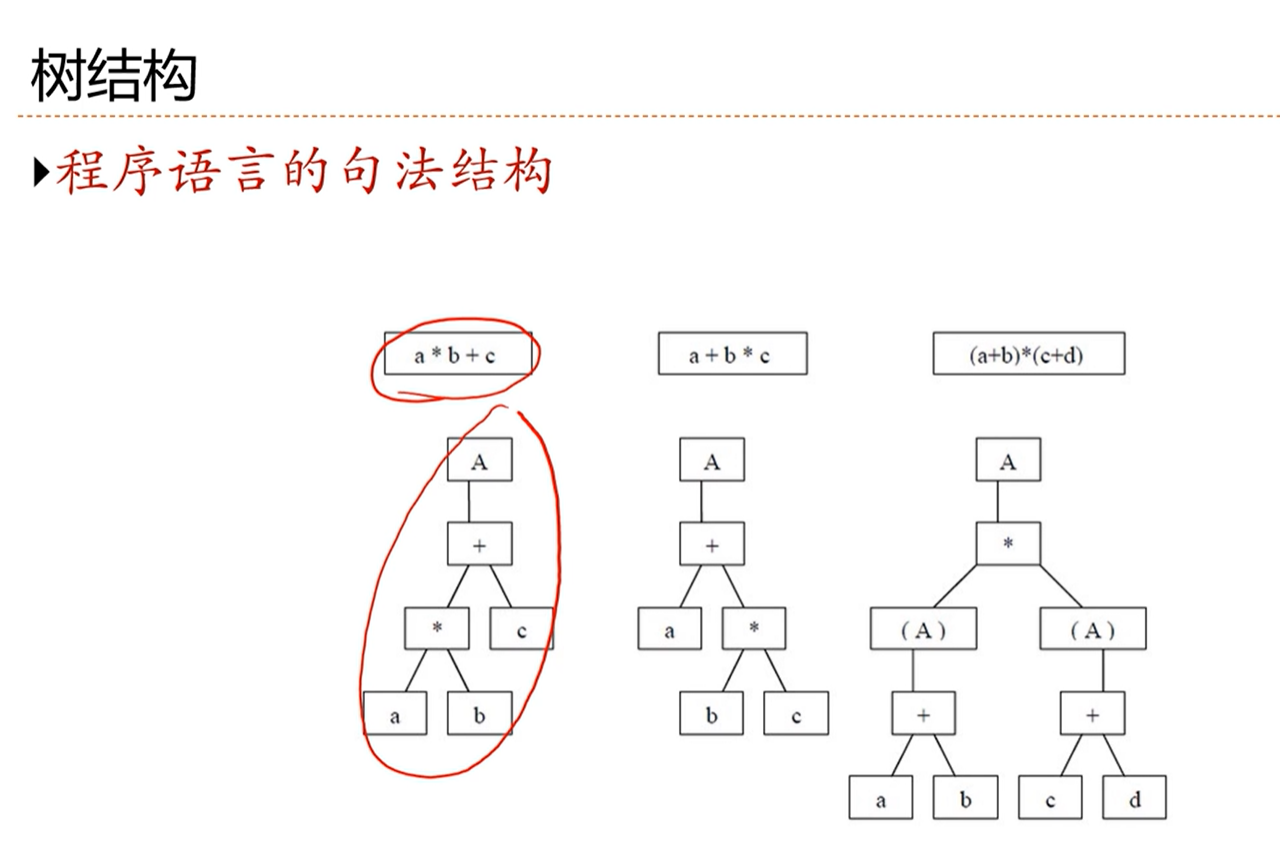
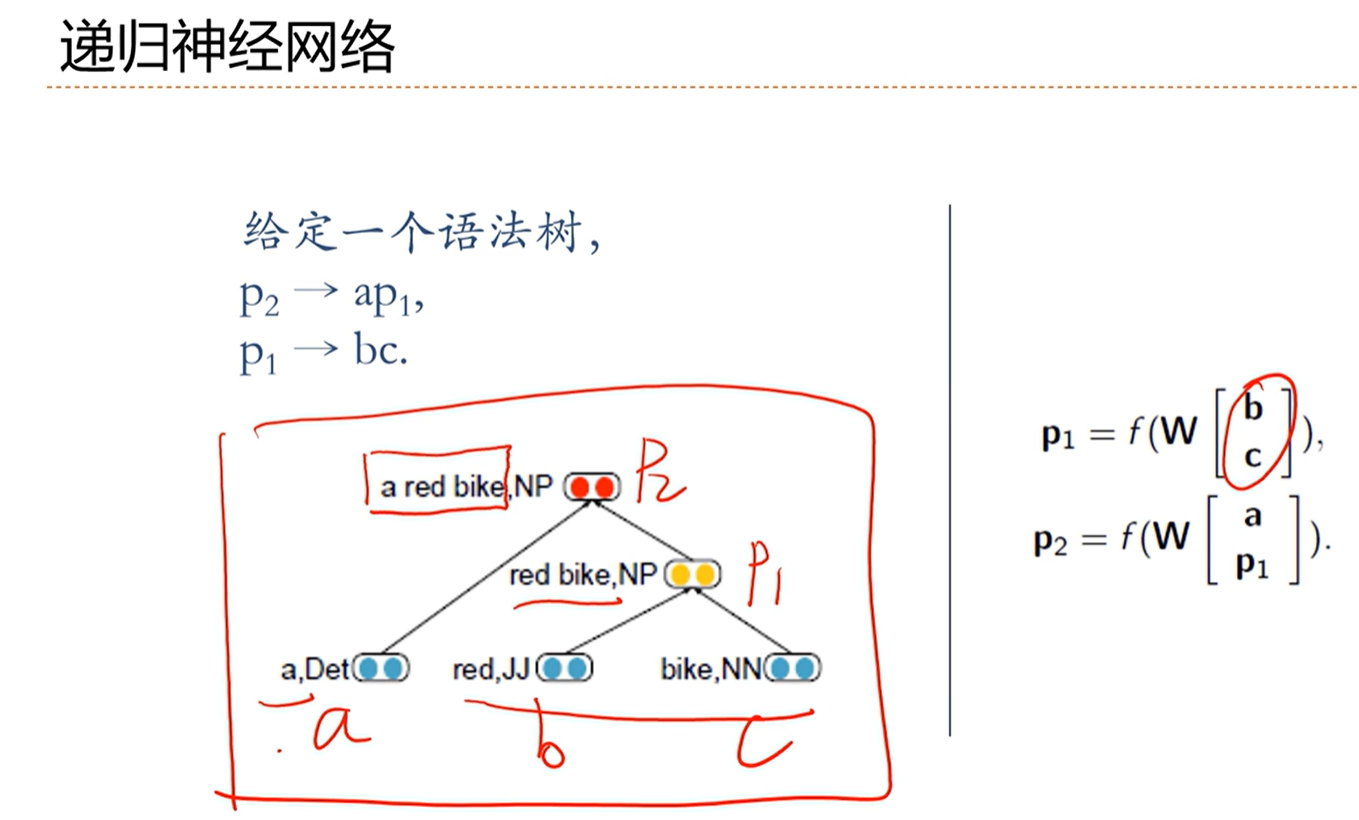
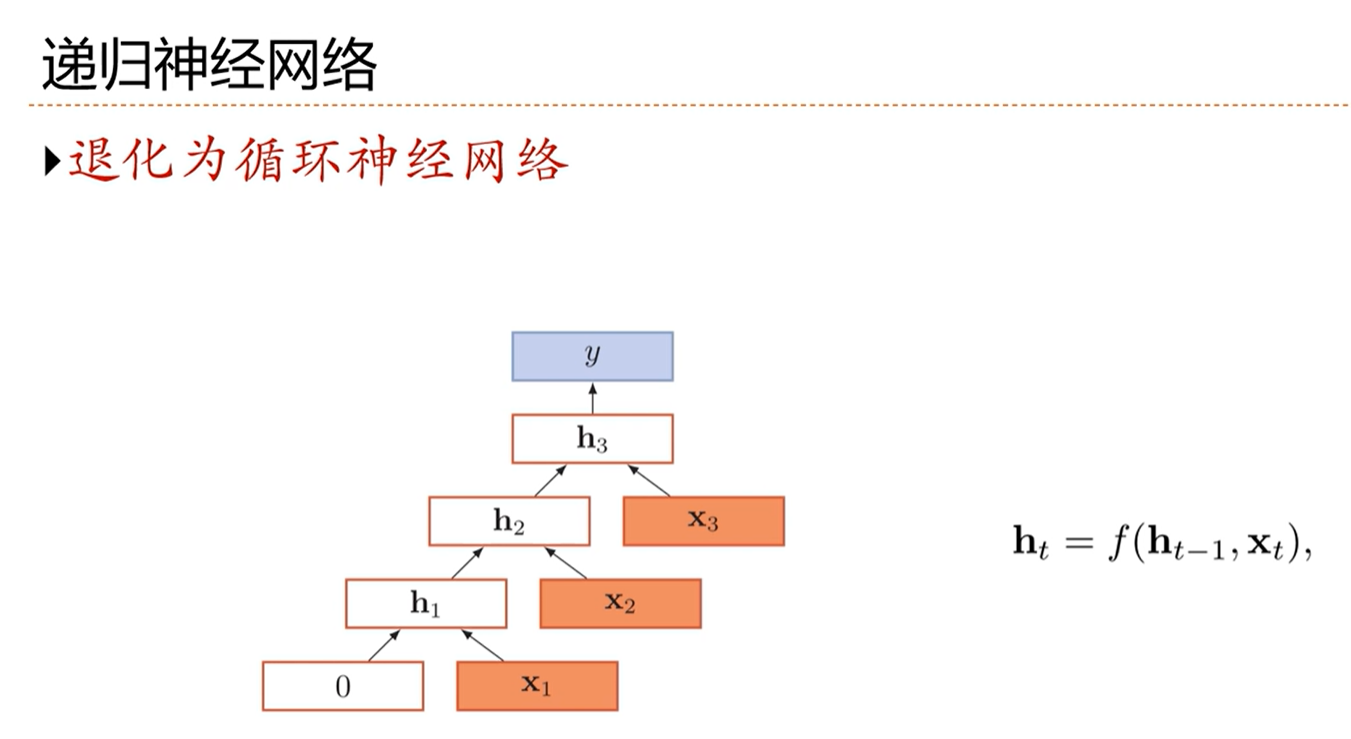
[√] 树结构


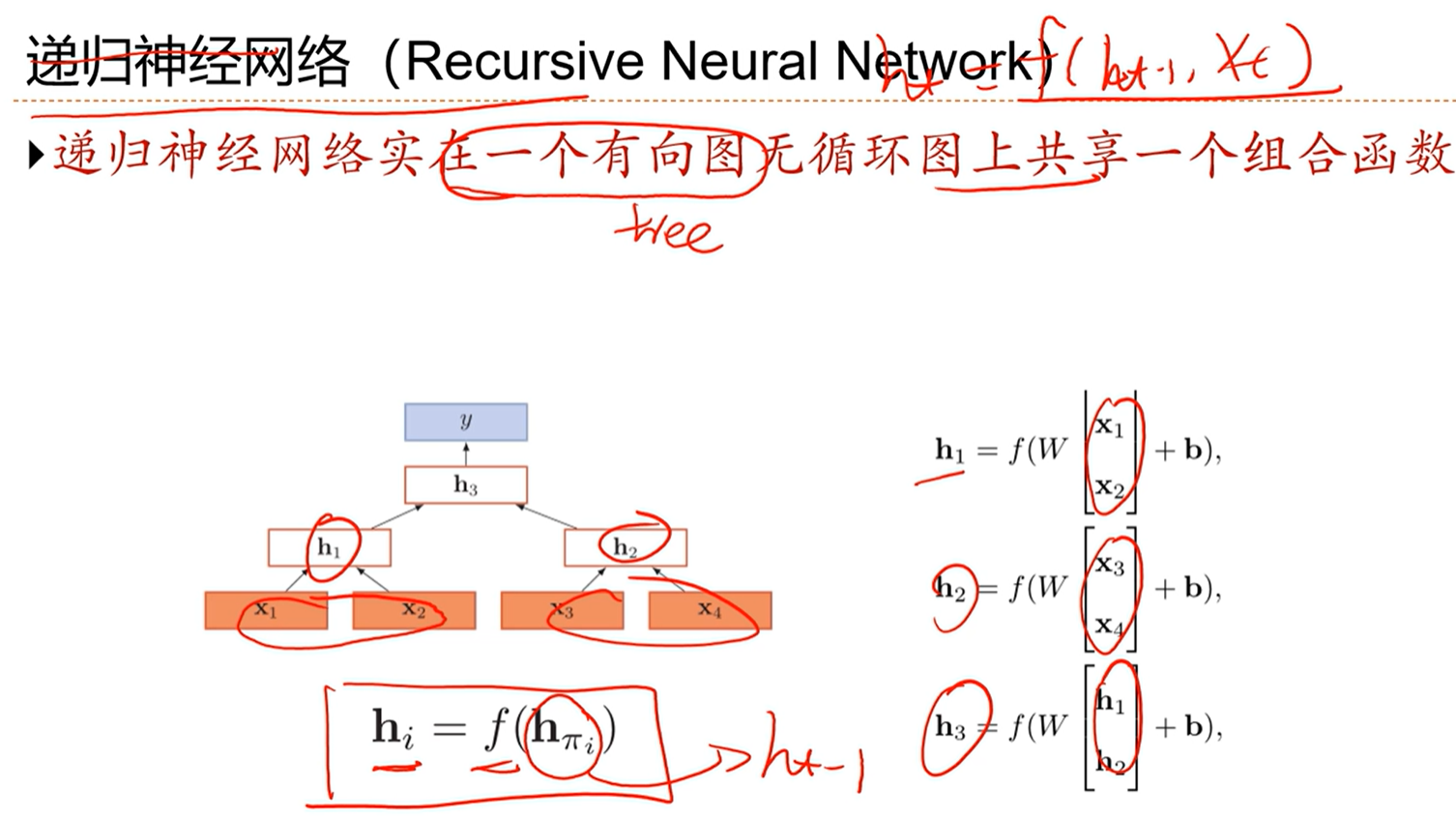
[√] 递归循环网络

[√] 图网络