054 - 文章阅读笔记:GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSRepVGG - 微信公众号 - AIWalker
本文最后更新于:3 个月前
原文链接:
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSRepVGG - 微信公众号 - AIWalker
2021-01-22 22:00
ps:本文为依据个人日常阅读习惯,在原文的基础上记录阅读进度、记录个人想法和收获所写,关于原文一切内容的著作权全部归原作者所有。
【要点记录】
- 轻量化超分方案
- 结合了GhostNet中的特征融合思想,同时考虑了图像超分任务的特殊性(不能直接移除冗余特征),提出了通过shift操作来生成这类“幽灵特征”,在降低计算量、参数量、推延迟的同时确保性能不显著下降。
- 这里所提出的GhostSR一种通用性的轻量化方案,相比剪枝等技术,该技术可以在性能几乎无损的约束下带来显著的推理速度提升、参数量降低、计算量降低。
[√] 论文信息

paper: https://arxiv.org/abs/2101.08525
注:公众号后台回复:GhostSR,即可下载该文。
- 【导读】本文是华为诺亚&北大提出的一种轻量化图像超分的方案
- 它结合了GhostNet中的特征融合思想,同时考虑了图像超分任务的特殊性(不能直接移除冗余特征),提出了通过shift操作来生成这类“幽灵特征”,在降低计算量、参数量、推延迟的同时确保性能不显著下降。
- 这里所提出的GhostSR一种通用性的轻量化方案,相比剪枝等技术,该技术可以在性能几乎无损的约束下带来显著的推理速度提升、参数量降低、计算量降低。
alec:
- ghost,鬼、幽灵
[√] Abstract
基于CNN的图像超分方案在取得显著性能提升的同时也带来了巨大的计算量需求,这就导致了现有CNN超分方案难以真正的落地。
在视觉识别任务中,GhostNet对特征冗余问题进行了研究并取得了非常好的效果;
而超分任务中的特征冗余问题则较少讨论。
基于现有超分模型中表现出来的特征相似性(也就是特征冗余),本文提出采用shift操作生成冗余特征(即Ghost Feature,本文将其称之为幽灵特征)。
不同于depthwise卷积对于GPU/NPU的不友好,shift操作可以在现有硬件下对CNN带来显著的推理加速。
我们对shift操作在SISR中的有效性进行了分析并通过
Gumbel-Softmax技巧使得shift操作变为可学习形式。对于给定的预训练模型,我们首先对每个卷积的滤波器进行聚类以确认用于生成本征特征的滤波器。幽灵特征可以通过对本征特征沿着特定方向移动进行生成。完整的输出特征通过将本征特征与幽灵特征进行concat组合得到。
最后,作者在多个基准数据及上对所提方案与其他SISR方案进行对比:所提方案可以大幅降低参数量、计算量、GPU延迟并取得同等性能。比如对于EDSRx2,通过所提方案可以减少47%的参数量、46%的计算量以及41%的GPU推理延迟,且不会造成显著性能下降。
alec:
- 采用shift操作生成冗余特征(幽灵特征)
- depthwise卷积对GPU/NPU不友好
- 什么是shift操作?
- 什么是NPU?
[√] Method
[√] Shift
对于基于CNN的SISR而言,它一般包含大量的卷积计算。对于常规卷积,如果输出特征为
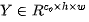 ,那么它需要
,那么它需要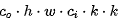 的计算量,卷积的计算消耗还包含功耗、推理耗时等。
的计算量,卷积的计算消耗还包含功耗、推理耗时等。与此同时,我们观察到SR网络中的某些特征具有相似性,也就是说:某些特征可以视作其他本征特征的
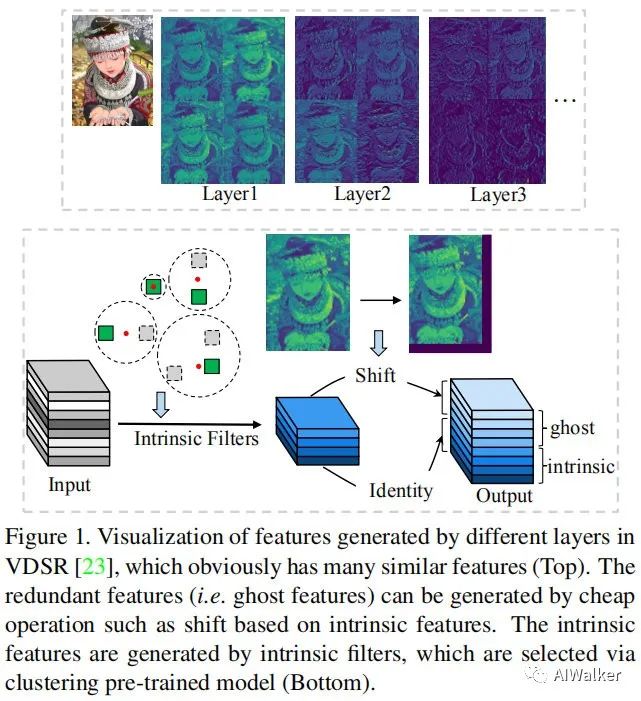
ghost,事实上,冗余特征可以提供本征特征之外的更多纹理与高频特征,而这些特征无法向GhostNet那样直接进行移除。不同于GhostNet中的消除冗余,本文提出采用更有效的操作(比如shift)生成它。以下图为例,VDSR网络中的特征存在非常强的特征相似性。
假设ghost特征的比例为λ,也就是说,我们有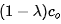 本征特征,
本征特征,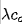 幽灵特征。我们可以采用常规卷积生成这些本征特征
幽灵特征。我们可以采用常规卷积生成这些本征特征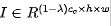 ;对于幽灵特征
;对于幽灵特征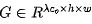 可以基于本征特征通过shift操作(shift操作优点多多,比如cheap,感受野大)生成。假设垂直核水平偏移量为
可以基于本征特征通过shift操作(shift操作优点多多,比如cheap,感受野大)生成。假设垂直核水平偏移量为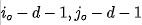 (d表示最大偏移),那么所得幽灵特征可以描述为:
(d表示最大偏移),那么所得幽灵特征可以描述为:
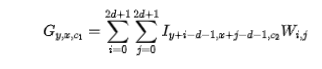
注: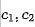 分别表示幽灵特征与本征特征的索引。而W的所有元素定义如下:
分别表示幽灵特征与本征特征的索引。而W的所有元素定义如下:
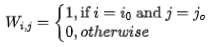
最后,我们对本征特征与幽灵特征进行concat得到完整输出 。相比原始的卷积操作,所提方法的计算量直接减少λ比例,且shift操作是无flops的。更重要的是,结合高效的CUDA实现,所提方法可以带来显著的GPU端推理加速。
。相比原始的卷积操作,所提方法的计算量直接减少λ比例,且shift操作是无flops的。更重要的是,结合高效的CUDA实现,所提方法可以带来显著的GPU端推理加速。
alec:
- 常规卷积的计算量:c_i · H · W · k · k · c_o
- SR网络中的某些特征具有相似性,也就是说:某些特征可以视作其他本征特征的
ghost- intrinsic,固有的、内在的、本质的
- intrinsic feature,本征特征
alec:
一句话概括:
- CNN的模型中提取出来的多个通道的特征,很多都是相似的、冗余的。所以对于冗余的特征图,可以直接通过本征的特征图通过shift操作得到,这样就不用再对冗余特征做CNN卷积操作了,能够节省开销。且shift操作没有计算量,shift就是对本征特征图移动几个像素。
[√] Benefits
- 前面介绍了shift操作的原理,接下来我们再看一下shift操作有哪些优点。
- 对于超分任务而言,纹理&高频信息有助于改善提升重建图像的质量。给定输入特征
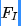 ,对其移动一个像素并进行合理的0pad得到
,对其移动一个像素并进行合理的0pad得到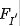 ,见下图(a)。将两者concat后送入到下一层卷积处理,此时卷积操作可以视作更复杂的包含sub的操作,同时可以一定程度上增强高频信息。
,见下图(a)。将两者concat后送入到下一层卷积处理,此时卷积操作可以视作更复杂的包含sub的操作,同时可以一定程度上增强高频信息。
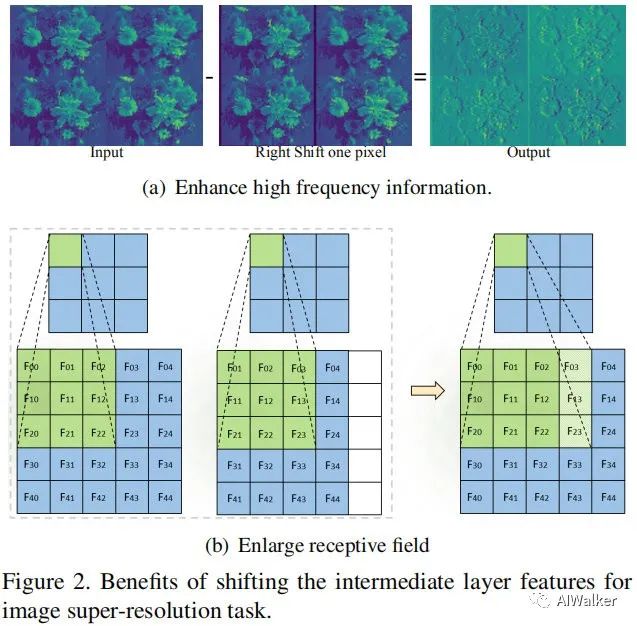
此外,两个空间扰乱特征的组合有助于提升CNN的感受野,而这对于超分任务而言非常重要。也就是说:shift操作为卷积滤波器提供了空间信息交互。感受野的提升示意图见上图(b)。
alec:
- shift操作为卷积滤波器提供了空间信息交互。感受野的提升示意图见上图(b)。
[√] Learnable shift
前面提到了shift的定义和优点,但它怎么嵌入到CNN中呢?为了在训练过程中更灵活的调整本征特征,作者提出使偏移权值W变成可学习方式。然W中的one-hot数值方式使其难以优化。
作者提出采用Gumbel-Softmax技巧解决上述问题,它在前向过程中传递one-hot信号,在反向传播时传递soft信号,这就解决了前述不可微问题。

通过上述方式的转换,偏置权值W就可以纳入到CNN的训练过程中了。在训练完成后,我们再构建one-hot形式的W即可得到最后的GhostSR。
[√] Ghost Features in Pre-Trained Model
接下来,我们再来看一下如何利用上述机制训练一个GhostSR,见下图。

alec:
- 输入:成对的训练数据、预训练的常规卷积模型、指定要被压缩的层
- 输出:一个完美训练的GhostSR网络
- 在预训练的网络上进行Ghost微调,效果才好。因为预训练的网络,相邻的特征图已经呈现出幽灵的效果。
- 通过“逐层滤波器聚类”的方式,确定哪些是本征特征图,哪些是幽灵特征图。
作者提到:如果从头开始训练GhostSR,那么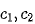 会简单的按顺序排列,这与期望不符。如果在预训练SISR基础上进行微调,我们就可以充分利用本征特征与幽灵特征的相关性并获得更好的性能。
会简单的按顺序排列,这与期望不符。如果在预训练SISR基础上进行微调,我们就可以充分利用本征特征与幽灵特征的相关性并获得更好的性能。
对于给定预训练SISR模型,我们旨在通过shift操作替换卷积滤波器已生成融合特征。然而,对于网络的特定层,哪些特征是本征特征,哪些是幽灵特征是不明确的。我们通过对预训练模型逐层滤波器聚类的方式解决上述问题。
我们先对卷积滤波器向量化,即从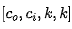 转换为
转换为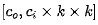 形式得到向量
形式得到向量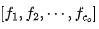 。我们需要将上述权值核划分到
。我们需要将上述权值核划分到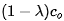 个类
个类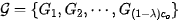 ,采用kmeans的优化方式:
,采用kmeans的优化方式:
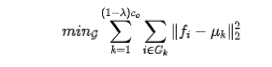
通过上述方式优化到合适的聚类中心,每个聚类中心视作本征滤波器,对应的特征为本征特征。本征滤波器的索引生成方式如下:
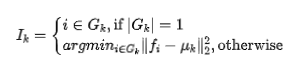
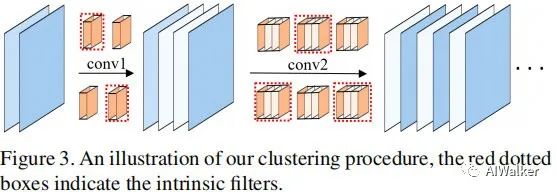
为保持聚类通道的邻层一致性,我们采用前一层的本征索引生成下一层的特征,见上图。再找到每一层的所有本征特征后,我们把预训练的权值赋予这些本征滤波器,这样可以最大化的利用预训练模型的信息并获得更好性能。
[√] Experiments
训练数据:DIV2K;测试数据:Set5、Set14、B100、Urban100。度量指标为PSNR/SSIM@YCbCr。对比模型包含EDSR、RDN、CARN。
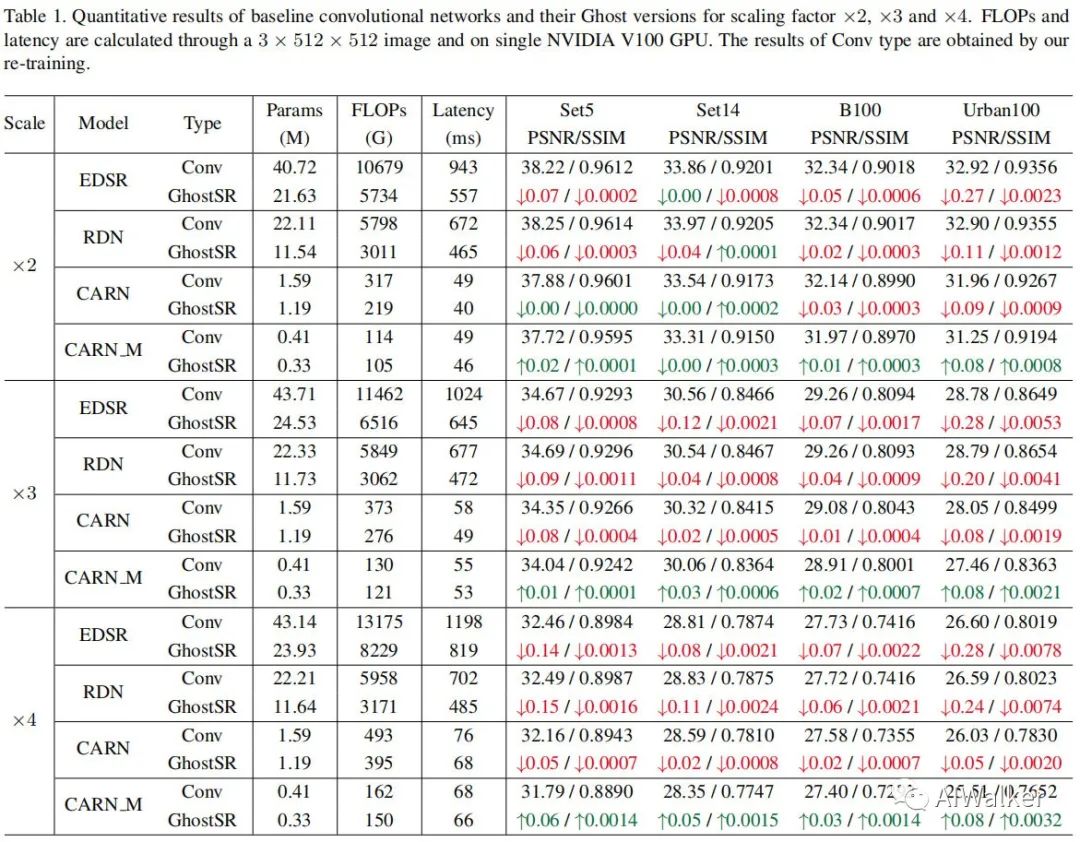
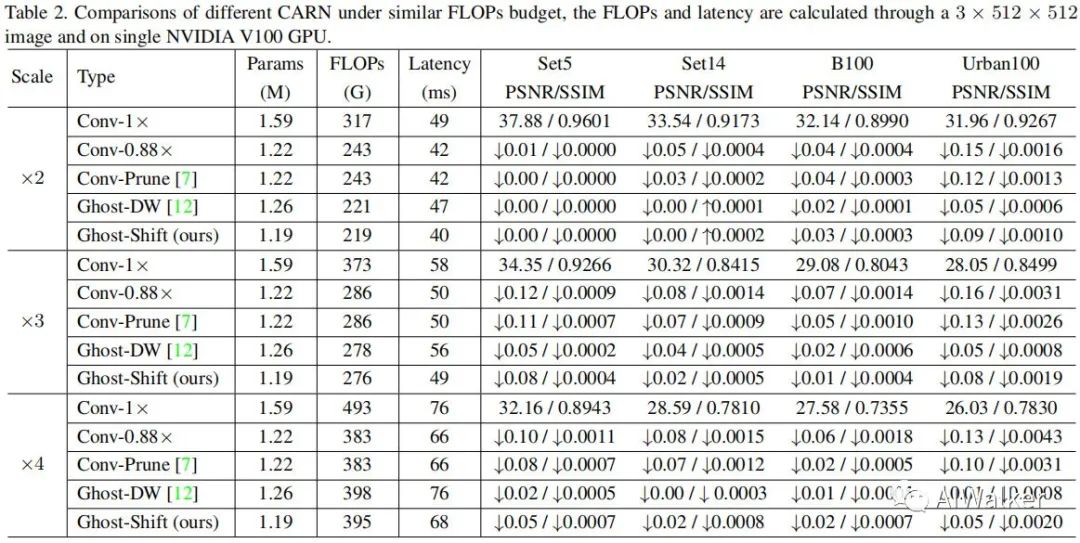
上表给出了不同倍率、不同模型的优化前后的性能对比。从中可以看到:
对于非轻量型模型EDSR与RDN而言,当常规卷积通过shift进行替换后,参数量与计算量几乎减少一半且性能无显著下降;更重要的是:结合高效CUDA实现,**GhostSR可以带来显著的GPU推理速度,高达41%**。
对于轻量型模型CARN与CARN_M而言,参数量、计算量与GPU延迟同样带来不同程度的减少。甚至对于CARN_M,GhostSR还带来一定程度的性能提升,同时参数量、计算量还有所降低。

上图给出了在x4任务上的视觉效果对比,可以看到:GhostSR效果与原始方案相当。与此同时,作者还对比了所提方法与剪枝、Depthwise等的性能与效果对比,见下图。
alec:
- 剪枝、Depthwise和shift操作一样,也是轻量化的操作。

全文到此结束,更多消融实验建议各位同学查看原文。
alec:
- RDN = 密集残差网络
- CARN = 级联残差网络
- latency = 延迟 = 推理速度
[√] 推荐阅读
- 图像超分中的那些知识蒸馏
- ICLR2021 | 显著提升小模型性能,亚利桑那州立大学&微软联合提出SEED
- RepVGG|让你的ConVNet一卷到底,plain网络首次超过80%top1精度
- AAAI2021 | 长尾识别中的trick大礼包
- Transformer再下一城!low-level多个任务榜首被占领
- 通道注意力新突破!从频域角度出发,浙大提出FcaNet
- 何恺明团队最新力作SimSiam:消除表征学习“崩溃解”,探寻对比表达学习成功之根源
- 无需额外数据、Tricks、架构调整,CMU开源首个将ResNet50精度提升至80%+新方法
- 自监督黑马SimCLRv2来了!提出蒸馏新思路,可迁移至小模型,性能精度超越有监督