本文最后更新于:3 个月前
[√] 7.4 参数初始化
alec:
神经网络的参数学习是一个非凸优化问题。
当使用梯度下降法来进行网络参数优化时,参数初始值的选取十分关键,关系到网络的优化效率和泛化能力。(神经网络的初始参数值非常重要)
此外,由于神经网络优化时出现的对称权重现象(参见第4.4.1节),神经网络的参数不能初始化为相同的值,需要有一定的差异性。(神经网络的参数初始值不能初始化为相同的值)
常用的参数初始化的方式通常有以下三种:
随机初始化:最常用的参数初始化策略,通过一个随机采样函数来生成每个参数的初始值。
预训练初始化:一种在实践中经常使用的初始化策略,如果目标任务的训练数据不足,可以使用一个已经在大规模数据上训练过的模型作为参数初始值。预训练模型在目标任务上的学习过程也称为精调Fine-Tuning。
固定值初始化:对于神经网络中的某些重要参数,可以根据先验知识来初始化。比如对于使用ReLU激活函数的全连接层,其偏置通常可以设为比较小的正数(比如0.01),从而确保这一层的神经元的梯度不为0,避免死亡ReLU现象。
虽然预训练初始化通常具有更好的收敛性和泛化性,但是灵活性不够,不能在目标任务上任意地调整网络结构。因此,好的随机初始化方法对训练神经网络模型来说依然十分重要。在本节我们主要介绍两种随机初始化方法:基于固定方差的参数初始化和基于方差缩放的参数初始化。
[√] 7.4.1 基于固定方差的参数初始化 一种最简单的随机初始化方法是从一个固定均值(通常为 0)和方差$\sigma^2$的分布中采样来生成参数的初始值。基于固定方差的参数初始化方法主要有高斯分布初始化和均匀分布初始化两种:
高斯分布初始化:使用一个高斯分布$\mathscr{N}(0, \sigma^2)$对每个参数进行随机初始化。
均匀分布初始化:在一个给定的区间$[-r, r]$内采用均匀分布来初始化。
高斯分布和均匀分布初始化的实现方式可以参考第4.4.1节参数初始化代码。
[√] 7.4.2 基于方差缩放的参数初始化
alec:
初始化一个深度网络时,为了缓解梯度消失或爆炸问题,我们尽可能保持每个神经元的输入和输出的方差一致。
根据神经元的连接数量来自适应地调整初始化分布的方差,这类方法称为方差缩放(Variance Scaling)。
Xavier初始化是参数初始化中常用的方法,根据每层的神经元数量来自动计算初始化参数方差。
在计算出参数的理想方差后,可以通过高斯分布或均匀分布来随机初始化参数。
在计算出参数的理想方差后,可以通过高斯分布或均匀分布来随机初始化参数。若神经元采用Tanh函数,并采用高斯分布来随机初始化参数,连接权重$w_i^{(l)}$可以按$\mathscr{N}(0, \frac{2}{M_{l-1} + M_l})$的高斯分布进行初始化,其中$M_{l-1}$是第$l-1$层神经元个数。
[√] 7.4.2.1 模型构建 首先定义xavier_normal_std函数,根据$l$层和$l-1$层神经元的数量计算理想标准差。值得注意的是,在paddle.normal API中,通过指定标准差的值来生成符合正态分布的张量,因此,这里需要计算标准差。代码实现如下:
1 2 3 def xavier_normal_std (input_size, output_size ):return np.sqrt(2 / (input_size + output_size))
alec:
Xavier初始化就是基于方差缩放的参数初始化,根据每层的神经元数量自动计算用于初始化参数的方差。
Xavier初始化适用于Logistic激活函数和Tanh激活函数。
对于不同激活函数,高斯分布的方差和均匀分布的$r$值计算是不同的。
xavier_normal_std定义针对Tanh激活函数的情况。
定义一个全连接前馈网络(即多层感知器)MLP算子,实例化网络时可以通过layers_size指定网络每层神经元的数量,通过init_fn_name指定网络中参数初始化方法(Xavier高斯分布初始化、Xavier均匀分布初始化或$\mathscr{N}(0, 1)$高斯分布初始化),init_fn指定计算初始化时均值或数值范围的函数,act_fn指定激活函数。代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class MLP (nn.Layer):def __init__ (self, layers_size, init_fn_name, init_fn, act_fn ):""" 多层网络初始化 输入: - layers_size: 每层神经元的数量 - init_fn_name: 网络中参数初始化方法,可以为 'normal'或'uniform' - init_fn: 函数,用来计算高斯分布标准差或均匀分布r值 - act_fn: 激活函数 """ super (MLP, self).__init__()len (layers_size) - 1 for i in range (self.num_layers):1 ]if init_fn_name == 'normal' :str (i), nn.Linear(input_size, output_size,0 , std=init_fn(input_size, output_size))))elif init_fn_name == 'uniform' :str (i), nn.Linear(input_size, output_size, weight_attr=nn.initializer.Uniform(low=-r, high=r)))else :str (i), nn.Linear(input_size, output_size, weight_attr=nn.initializer.Normal()))def __call__ (self, X ):return self.forward(X)def forward (self, X ):""" 前向计算 """ for num_layer in range (self.num_layers):if num_layer != self.num_layers - 1 :return y
[√] 7.4.2.2 观察模型神经元的方差变化 [√] 高斯分布初始化 定义网络每层神经元的数量,指定激活函数和参数初始化方式,通过Xavier高斯分布初始化网络。代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 paddle.seed(0 )100 , 200 , 400 , 300 , 200 , 100 ]'normal' 1 , 100 ], std=0.1 )
1 2 运行时长: 11 毫秒2022 -12 -24 16 :17 :09
打印每层神经元输出的方差,观察每层的方差值。
1 2 for i in range (len (model.z) - 1 ):print ('layer %d: , %f' %(i, model.z[i].numpy().var()))
1 2 3 4 layer 0 : , 0.005416 1 : , 0.003292 2 : , 0.003820 3 : , 0.004489
从输出结果看,Xavier初始化可以尽量保持每个神经元的输入和输出方差一致。
[√] 均匀分布初始化 若采用区间为$[-r, r]$的均匀分布来初始化$w_i^{(l)}$,则$r$的取值为$\sqrt{\frac{6}{M_{l-1} + M_l}}$。定义xavier_uniform_r,计算均匀分布$r$的值。代码实现如下:
1 2 def xavier_uniform_r (input_size, output_size ):return np.sqrt(6 / (input_size + output_size))
1 2 运行时长: 4 毫秒2022 -12 -24 16 :19 :38
定义网络每层神经元的数量,通过Xavier均匀分布初始化网络。代码实现如下:
1 2 3 4 5 6 7 8 9 10 paddle.seed(0 )'uniform' 1 , 100 ], std=0.1 )
1 2 运行时长: 11 毫秒2022 -12 -24 16 :20 :26
打印每层神经元输出的方差,观察每层的方差值。
1 2 for i in range (len (model.z) - 1 ):print ('layer %d: , %f' %(i, model.z[i].numpy().var()))
1 2 3 4 layer 0 : , 0.005596 1 : , 0.003397 2 : , 0.004084 3 : , 0.005171
[√] 7.4.2.3 观察模型训练收敛性 为了进一步验证Xavier初始化的效果,我们在一个简单的二分类任务上来训练MLP模型,并观察模型收敛情况。
构建数据集 这里使用在第3.1.1中定义的make_moons函数构建一个简单的二分类数据集。代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from nndl import make_moonsclass MoonsDataset (io.Dataset):def __init__ (self, mode='train' , num_samples=300 , num_train=200 ):super (MoonsDataset, self).__init__()True , noise=0.5 )if mode == 'train' :else :def __getitem__ (self, idx ):return self.X[idx], self.y[idx]def __len__ (self ):return len (self.y)
1 2 运行时长: 6 毫秒2022 -12 -24 16 :22 :13
创建训练和验证集,构建DataLoader。代码实现如下:
1 2 3 4 5 paddle.seed(0 )'train' )'dev' )10 , shuffle=True )10 , shuffle=True )
1 2 运行时长: 890 毫秒2022 -12 -24 16 :22 :59
定义五层MLP,分别以Xavier初始化和标准高斯分布初始化方式对网络进行初始化,训练100回合,对比两个模型的训练损失变化情况。代码实现如下:
alec:
Xavier高斯分布初始化 和 标准高斯分布初始化 的参数分布都是高斯分布的,但是Xavier高斯分布初始化的方差是由网络结构中的神经元的数量决定的,标准高斯分布初始化是固定的自定义均值和方差。一个和网络结构耦合,一个和网络结构无关。
SGD优化器的参数,只有一个学习率,是最基本的优化器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import nndl0 )0 )2 , 300 , 500 , 700 , 400 , 1 ]'normal' 0.005 , parameters=model1.parameters())True )100 , eval_steps=400 , log_steps=0 )'basic' None , act_fn=activate_fn)0.005 , parameters=model2.parameters())100 , eval_steps=400 , log_steps=0 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [Evaluate] dev score: 0.81000 , dev loss: 0.42877 0.00000 --> 0.81000 0.83000 , dev loss: 0.42839 0.81000 --> 0.83000 0.83000 , dev loss: 0.42997 0.83000 , dev loss: 0.42962 0.83000 , dev loss: 0.42941 0.75000 , dev loss: 3.23409 0.00000 --> 0.75000 0.72000 , dev loss: 3.07022 0.70000 , dev loss: 3.35328 0.75000 , dev loss: 2.08153 0.73000 , dev loss: 2.73204
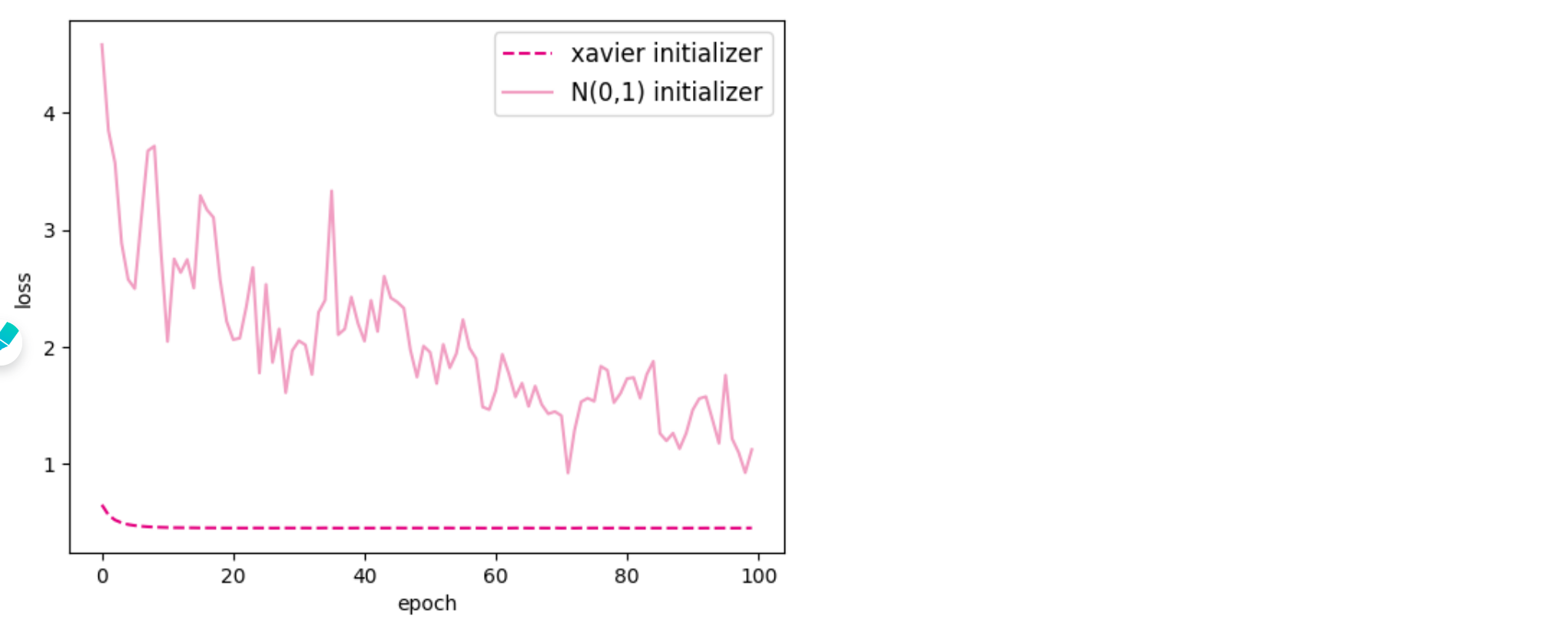
1 2 3 4 5 6 7 8 fig, ax = plt.subplots()'xavier initializer' , c='#e4007f' , linestyle='--' )'N(0,1) initializer' , c='#f19ec2' )'epoch' )'loss' )'large' )'opti-xavier.pdf' )
alec:
从输出结果看,使用基于网络结构数量进行方差缩放的Xavier初始化,模型的损失相对较小,模型效果更好。
[√] 7.5 逐层规范化
alec:
逐层规范化(Layer-wise Normalization)是将传统机器学习中的数据规范化方法应用到深度神经网络中
对神经网络中隐藏层的输入进行规范化,从而使得网络更容易训练。
(规范化是将隐藏层的输入和输出进行规范化,从而使得网络训练更加容易)
在DNN中,如果一个神经层的输入数据的分布状况发生了变化,从机器学习的角度来看,这个网络的之前学习的参数无效,需要重新学习。这叫内部协变量偏移。为了解决这个问题,那么就在训练之前,就设置一定的方法,让神经网络中每层的输入都是符合某种稳定分布的规划数据。这个动作叫做规范化。需要对每一层都进行输入数据的规范化,这个动作加逐层规范化。
逐层规范化(Layer-wise Normalization)是将传统机器学习中的数据规范化方法应用到深度神经网络中,对神经网络中隐藏层的输入进行规范化,从而使得网络更容易训练。
在深度神经网络中,一个神经层的输入是之前神经层的输出。给定一个神经层$l$,它之前的神经层$(1, \cdots, l-1$)的参数变化会导致其输入的分布发生较大的改变。从机器学习角度来看,如果一个神经层的输入分布发生了改变,那么其参数需要重新学习,这种现象叫作内部协变量偏移(Internal Covariate Shift)。 为了缓解这个问题,我们可以对每一个神经层的输入进行规范化操作,使其分布保持稳定。
[√] 7.5.1 批量规范化
alec:
对于一个深度神经网络,为了提高优化效率,要使第$l$层的净输入$z^{(l)}$的分布一致,比如都规范化到标准正态分布。
实际中,一般在线性层和激活函数之间使用规范化操作。
只有分布统一的数据,才能训练处有效的网络参数,因此需要对每一层的数据先规范化,然后再训练。
而为了提高规范化效率,一般使用标准化将净输入$z^{(l)}$的每一维都规范化到标准正态分布。
$$
使用小批量样本的均值和方差来规范化数据,使得数据符合标准正态分布。
对净输入$ z^{(l)}$的标准规范化会使得其取值集中到0附近,如果使用Sigmoid型激活函数时,这个取值区间刚好是接近线性变换的区间,减弱了神经网络的非线性性质。这样就导致激活函数的非线性作用微弱了,导致网络的表示能力减弱。
因此,为了使得规范化不对网络的表示能力造成负面影响,可以通过一个附加的缩放和平移变换改变取值区间。则有:
$$
右边的γ和β是用来进行缩放和平移的,让规范化之后的数据远离0附近。
上面的这种规划化操作,叫做批量规范化,即BatchNorm,BN层,通常在线性层和激活层之间,目的是统一每层输入数据的分布,从而使得网络训练出来的参数有效。
其中,指定的γ和β是数据最终规划化之后的均值和方差。
[√] 7.5.1.1 BatchNorm算子 下面定义BatchNorm算子,实现批量规范化。
alec:
在实现批量规范化时,在训练过程中的均值和方差可以动态计算,但在测试时需要保存固定,否则模型输出就会受到同一批次中其他样本的影响。
因此,在训练时需要将每一批次样本的均值和方差以移动平均值的方式记录下来,预测时使用整个训练集上的均值和方差(也就是保存的移动平均值)进行规范化。代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class BatchNorm (nn.Layer):def __init__ (self, num_features, eps=1e-7 , momentum=0.9 , gamma=1.0 , beta=0.0 ):""" 批量规范化初始化 输入: - num_features: 输入特征数 - eps: 保持数值稳定性而设置的常数 - momentum: 用于计算移动平均值 - gamma: 缩放的参数 - beta: 平移的参数 """ super (BatchNorm, self).__init__()1 , num_features)'float32' )'float32' )def __call__ (self, X, train_mode=True ):return self.forward(X, train_mode)def forward (self, X, train_mode=True ):if not train_mode:else :assert len (X.shape) in (2 , 4 )if len (X.shape) == 2 :0 )2 ).mean(axis=0 )else :0 , 2 , 3 ], keepdim=True )2 ).mean(axis=[0 , 2 , 3 ], keepdim=True )1. - self.momentum) * mean1. - self.momentum) * varreturn y
1 2 运行时长: 10 毫秒2022 -12 -24 17 :30 :55
alec:
BN的过程,就是计算当前批次数据的均值和方差,然后进行规范化操作,同时记录均值和方差的移动平均值,并进行缩放和移动来防止规范化后的数据落在0周围导致激活函数的非线性作用减弱进而导致网络的表示能力减弱
[√] 7.5.1.2 支持逐层规范化的MLP算子 重新定义MLP算子,加入逐层规范化功能。初始化网络时新增三个参数:norm_name指定使用哪一种逐层规范化(默认为None)、gamma和beta为缩放和平移变换的参数。代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 class MLP (nn.Layer):def __init__ (self, layers_size, init_fn_name, init_fn, act_fn, norm_name=None , gamma=None , beta=None ):""" 多层网络初始化 输入: - layers_size: 每层神经元的数量 - init_fn_name: 网络中参数初始化方法 - init_fn: 计算高斯分布标准差或均匀分布r值 - act_fn: 激活函数 - norm_name: 使用哪一种逐层规范化 - gamma、beta: 缩放和平移变换的参数 """ super (MLP, self).__init__()len (layers_size) - 1 for i in range (self.num_layers):1 ]if init_fn_name == 'normal' :str (i), nn.Linear(input_size, output_size,0 , std=init_fn(input_size, output_size))))elif init_fn_name == 'uniform' :str (i), nn.Linear(input_size, output_size, weight_attr=nn.initializer.Uniform(low=-r, high=r)))else :str (i), nn.Linear(input_size, output_size, weight_attr=nn.initializer.Normal()))if norm_name == 'bn' :elif norm_name == 'ln' :def __call__ (self, X, train_mode=True ):return self.forward(X, train_mode)def forward (self, X, train_mode=True ):for num_layer in range (self.num_layers):if num_layer != self.num_layers - 1 :if self.norm_name == 'bn' :elif self.norm_name == 'ln' :return y
1 2 运行时长: 13 毫秒2022 -12 -24 17 :41 :15
alec:
为批量规范化是对一个中间层的单个神经元进行规范化操作
批量规范化的时候,小批量样本的数量不能太小,否则难以计算单个神经元的统计信息
因为批量规范化是对一个中间层的单个神经元进行规范化操作,所以要求小批量样本的数量不能太小,否则难以计算单个神经元的统计信息。所以我们使用paddle.randn随机生成一组形状为(200, 100)的数据, 打印数据送入网络前的均值与标准差。再分别定义使用批量规范化和不使用批量规范化的五层线性网络,分别打印网络第四层的均值与标准差,对比结果。
[√] 7.5.1.3 内部协变量偏移实验
alec:
内部协变量偏移实验,其实就是指的数据进行批量规范化和没有进行批量规范化的区别和影响。
下面我们构建两个模型:model1不使用批量规范化,model2使用批量规范化,观察批量规范化是否可以缓解内部协变量偏移问题。代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 paddle.seed(0 )100 , 200 , 400 , 300 , 2 , 2 ]200 , 100 ])print ('data mean: ' , data.numpy().mean())print ('data std: ' , data.numpy().std())'basic' , None , act_fn=activate_fn)print ('no batch normalization: ' )print ('model output mean: ' , model1.z[3 ].numpy().mean(axis=0 ))print ('model output std:' , model1.z[3 ].numpy().std(axis=0 ))1 , 1 , 1 , 1 , 1 ]0 , 0 , 0 , 0 , 0 ]'basic' , None , act_fn=activate_fn, norm_name='bn' , gamma=gamma, beta=beta)print ('with batch normalization: ' )print ('model output mean: ' , model2.z[3 ].numpy().mean(axis=0 ))print ('model output std:' , model2.z[3 ].numpy().std(axis=0 ))
1 2 3 4 5 6 7 8 data mean: 0.001138683 1.0084993 0.6876077 -0.8056189 ]18.348772 15.487542 ]with batch normalization: 4.9173834e-09 -8.0466274e-09 ]1.0000002 1. ]
alec:
从输出结果看,在经过多层网络后,网络输出的均值和标准差已经发生偏移。而当我们指定批量规范化的均值和标准差为0,1时,网络输出的均值和标准差就会变为0,1。
当我们指定$\gamma$和$ \beta$时,网络输出的标准差和均值就变为$ \gamma$和$ \beta$的值。
1 2 3 4 5 6 7 8 9 10 11 paddle.seed(0 )1 , 2 , 3 , 5 , 4 ]3 , 2 , 1 , 2 , 2 ]'basic' , None , act_fn=activate_fn, norm_name='bn' , gamma=gamma, beta=beta)print ('batch normalization with different gamma and beta for different layer: ' )print ('output means with bn 0: ' , model3.z[0 ].numpy().mean())print ('output stds with bn 0: ' , model3.z[0 ].numpy().std())print ('output means with bn 3: ' , model3.z[3 ].numpy().mean())print ('output stds with bn 3: ' , model3.z[3 ].numpy().std())
alec:
gamma = [1, 2, 3, 5, 4]、beta = [3, 2, 1, 2, 2],这两个list是用来指定神经网络5层中每一层的均值和方差
1 2 3 4 5 batch normalization with different gamma and beta for different layer: with bn 0 : 3.0 with bn 0 : 1.0 with bn 3 : 2.0 with bn 3 : 5.0
alec:
该实验说明,没有进行BN的话,那么数据的分布就会改变;进行了BN,那么每层数据的分布都会按照指定的均值和方差来分布,也就是按照缩放和偏移量进行分布。
因此BN对于数据的分布控制是有效的,从而能够网络高效的进行参数计算。
[√] 7.5.1.4 均值和方差的移动平均计算实验 下面测试批量规范化中训练样本均值和方差的移动平均值计算。使网络前向迭代50个回合,这个前向计算并不涉及网络训练与梯度更新,只是模拟网络训练时批量规范化中训练样本的均值和方差用移动平均计算的过程。代码实现如下:
1 2 3 4 5 6 7 8 9 10 paddle.seed(0 )50 for epoch in range (epochs):200 , 100 ])print ('batch norm 3 moving mean: ' , model3.normalization[3 ].moving_mean.numpy())print ('batch norm 3 moving variance: ' , model3.normalization[3 ].moving_variance.numpy())
1 2 batch norm 3 moving mean: [[-0.63306284 0.17639302 ]]3 moving variance: [[149.98349 267.1632 ]]
开启测试模式,使用训练集的移动平均值作为测试集批量规范化的均值和标准差。代码实现如下:
1 2 3 4 paddle.seed(0 )5 , 100 ])False )
[√] 7.5.1.5 在MNIST数据集上使用带批量规范化的卷积网络
alec:
批量规范化的提出是为了解决内部协方差偏移问题,但后来发现其主要优点是更平滑的优化地形,以及使梯度变得更加稳定,从而提高收敛速度。
为验证批量规范化的有效性,本节使用飞桨API快速搭建一个多层卷积神经网络。在MNIST数据集上,观察使用批量规范化的网络是否相对于没有使用批量规范化的网络收敛速度更快。代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from paddle.nn import Conv2D, MaxPool2D, Linear, BatchNorm2Dclass MultiConvLayerNet (nn.Layer):def __init__ (self, use_bn=False ):super (MultiConvLayerNet, self).__init__()1 , out_channels=20 , kernel_size=5 , stride=1 , padding=2 )2 , stride=2 )20 , out_channels=20 , kernel_size=5 , stride=1 , padding=2 )2 , stride=2 )980 , 10 )if use_bn:20 )20 )def forward (self, inputs ):if self.use_bn:if self.use_bn:0 ], 980 ])return x
1 2 运行时长: 8 毫秒2022 -12 -24 21 :12 :17
实例化网络并进行训练。model1不使用批量规范化,model2使用批量规范化。代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from nndl import Accuracy0 )'cv2' )'train' , transform=transform)64 , shuffle=True )'test' , transform=transform)64 )False )0.01 , parameters=model1.parameters())print ('train network without batch normalization' )5 , log_steps=0 , eval_steps=300 )True )0.01 , parameters=model2.parameters())print ('train network with batch normalization' )5 , log_steps=0 , eval_steps=300 )
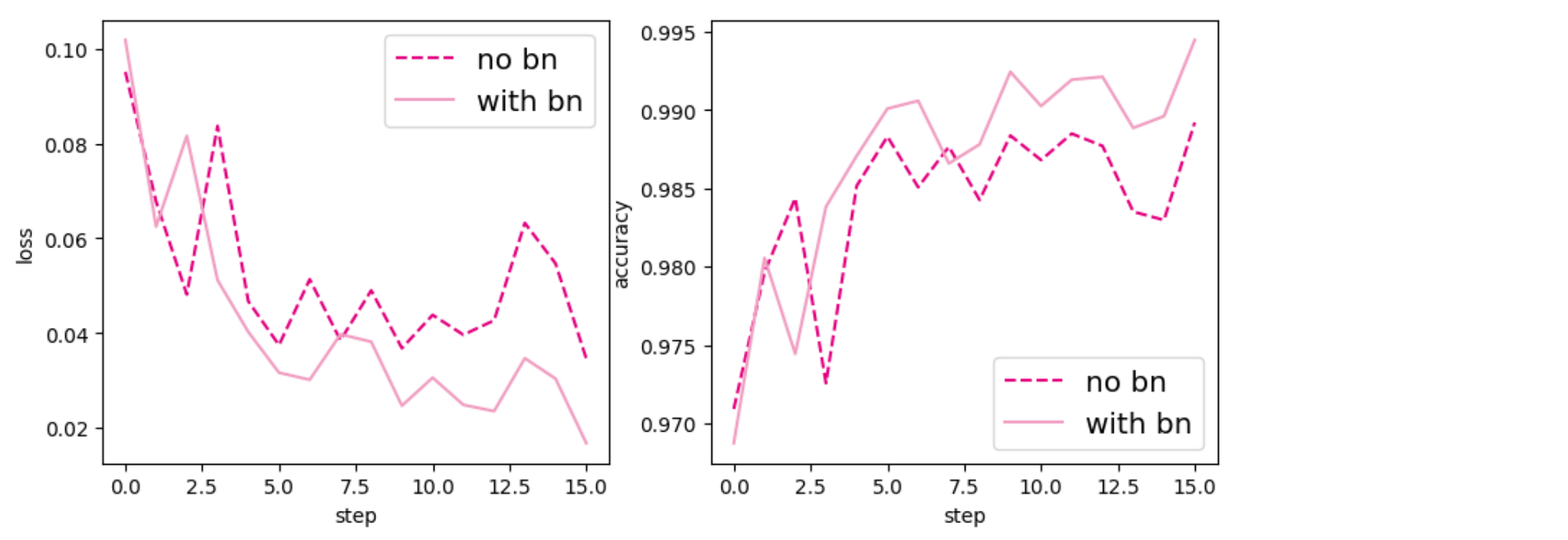
对比model1和model2在验证集上损失和准确率的变化情况。从输出结果看,使用批量规范化的网络收敛速度会更好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 plt.figure(figsize=(10 , 4 ))121 )1 ], label='no bn' , c='#e4007f' , linestyle='--' )1 ], label='with bn' , c='#f19ec2' )'step' )'loss' )'x-large' )122 )'no bn' , c='#e4007f' , linestyle='--' )'with bn' , c='#f19ec2' )'step' )'accuracy' )'x-large' )'opti-acc.pdf' )
alec:
可以看出,使用批量规范化的模型收敛速度和效果会更好
[√] 7.5.2 层规范化
alec:
层规范化(Layer Normalization)和批量规范化是非常类似的方法
它们的区别在于批量规范化对中间层的单个神经元进行规范化操作,而层规范化对一个中间层的所有神经元进行规范化
层规范化定义为
其中$ z^{(l)}$为第$l$层神经元的净输入, $ \gamma$和$ \beta$分别代表缩放和平移的参数向量,和$ z^{(l)}$维数相同。$\mu^{(l)}$和$\sigma^{(l)^2}$分别为$ z^{(l)}$的均值和方差。
根据上面的公式可以看出,对于$K$个样本的一个小批量合集$z^{(l)} = [ z^{(1, l)}; …; z^{(K, l)}]$,层规范化是对矩阵$ z^{(l)}$的每一列进行规范化,而批量规范化是对每一行进行规范化。一般而言,批量规范化是一种更好的选择。当小批量样本数量比较小时,可以选择层规范化。
一般而言,批量规范化是一种更好的选择
[√] 7.5.2.1 LayerNorm算子 定义LayerNorm实现层规范化算子。与批量规范化不同,层规范化对每个样本的所有特征进行规范化。代码实现如下:
alec:
批规范化对一个batch的样本,对相同的一个特征进行规范化
层规范化,对单个样本,所有的通道特征进行规范化
1 2 3 4 5 6 7 8 9 1 , 2 , 3 ], keepdim=True )2 ).mean(axis=[1 , 2 , 3 ], keepdim=True )0 , 2 , 3 ], keepdim=True )2 ).mean(axis=[0 , 2 , 3 ], keepdim=True )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class LayerNorm (nn.Layer):def __init__ (self, eps=1e-7 , gamma=1.0 , beta=0.0 ):""" 层规范化初始化 输入: - eps: 保持数值稳定性而设置的常数 - gamma: 缩放的参数 - beta: 平移的参数 """ super ().__init__(self.__class__.__name__)'float32' )'float32' )def forward (self, X ):assert len (X.shape) in (2 , 3 , 4 )if len (X.shape) == 4 :1 , 2 , 3 ], keepdim=True )2 ).mean(axis=[1 , 2 , 3 ], keepdim=True )else :1 , keepdim=True )2 ).mean(axis=-1 , keepdim=True )return y
[√] 7.5.2.2 层规范化的验证实验 随机初始化一组形状为(10,100)的数据,输入带有层规范化的前馈神经网络中,得到网络输出并打印输出的标准差和均值。指定$ \gamma$和$ \beta$,从输出结果看,网络输出的标准差和均值变为$ \gamma$和$ \beta$的值。代码实现如下:
alec:
bn是批量规范化、ln是层规范化,bn是在单个特征图、一批图像上规范化、ln是在单个图像、一层的特征图上做规范化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 paddle.seed(0 )100 , 200 , 400 , 300 , 2 , 2 ]10 , 100 ])1 , 2 , 3 , 5 , 4 ]3 , 2 , 1 , 2 , 2 ]'basic' , None , act_fn=activate_fn, norm_name='ln' , gamma=gamma, beta=beta)print ('layer normalization with different gamma and beta for different layer: ' )print ('output means with ln 0: ' , model.z[0 ].numpy().mean(axis=-1 ))print ('output stds with ln 0: ' , model.z[0 ].numpy().std(axis=-1 ))print ('output means with ln 1: ' , model.z[3 ].numpy().mean(axis=-1 ))print ('output stds with ln 1: ' , model.z[3 ].numpy().std(axis=-1 ))
因为层规范化是对每个样本的每个通道做规范化,不需要存储训练数据的均值和方差的移动平均值,所以这里不需要多轮迭代累计移动平均值再做测试。而随机生成测试数据经过带层规范化的神经网络和上述代码实现方式相同,这里不再重复展示。