047 - 文章阅读笔记:学习盲图像超分辨率的退化分布 - CSDN - geriezmann
本文最后更新于:3 个月前
原文链接:
学习盲图像超分辨率的退化分布 - CSDN - geriezmann
于 2022-04-08 17:16:52
版权声明:本文为CSDN博主「geriezmann」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/adhkcnbk/article/details/124046231
学习盲图像超分辨率的退化分布
[√] 摘要
合成的高分辨率(HR)和低分辨率(LR)被广泛应用于现有的分辨率方法中,为了避免合成图像和测试图像之间的域差距,以往的大多数方法都试图通过确定性模型自适应地学习合成(退化)过程。然而,在真实场景中的一些退化是随机的,不能由图像的内容来决定,这些确定性模型可能无法建模退化的随机因素和内容无关的部分,这将限制以下SR模型的性能。
在本文中,我们提出了一个概率退化模型(PDM),研究退化D作为一个随机变量,并通过对从先验随机变量z到D的映射进行建模学习其分布。与以往的确定性退化模型相比,PDM可以随机建模更多样化的退化,生成的HR-LR对可以更好的覆盖测试图像的各种退化,从而防止SR模型对特定图像的过拟合。大量的实验表明,我们的退化模型可以帮助SR模型在不同的数据集上获得更好的性能。
alec:
- PDM = 概率退化模型。
- 本文提出了一个概率退化模型PDM,PDM可以随机建模多样化的退化。
[√] 前言
超分辨旨在从低分辨率图像(LR)中重建出高分辨率图像(HR), 近年来,基于学习的SR方法取得了显著的效果,这些方法经常需要HR-LR图像对作为训练集。然而,在真实场景下获取成对的图像时非常困难的,作为一种替代,合成的HR-LR图像对被广泛应用于现存的超分辨方法,他们通过使用预定义的设计降解HR图像,如双边缘降采样, 模糊核卷积,或者添加一定范围的噪声,但是在盲超分辨中,测试图像的退化是未知的, 预定义的退化设置可能与测试图像不同,这个差距将在很大程度上破坏这些方法在实际场景中的性能。
为了避免域上的差距,一些工作尝试自适应的学习退化设置,如图一所示,退化模型通过对抗进行监督,并鼓励产生与测试图像相同领域的LR图像, 在KernelGAN中,退化模型被设计为线性卷积层,在CycleSR中,在CycleGAN框架中学习了一个非线性退化模型,这些学习到的退化模型可以产生与测试用例有较小差距的HR-LR对,因此可以用于测试一个更好的SR模型。
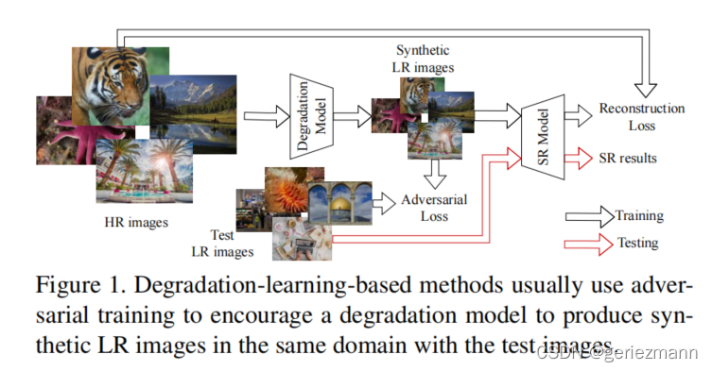
然而,大部分之前退化学习的方法有一个共同的缺点:它们的退化模型是确定性的,每个HR图像只能退化为一个特定的LR图像,它暗示了一个假设:退化完全依赖于图像的内容,然而,这在大多数情况下可能并不成立。一些退化是内容独立和随机的,如随机抖动引起的随机噪声或模糊,这些随机的因素和退化的内容独立不能通过这些确定的模型进行模拟,一个更好的假设是,退化受到一个分布的影响,这可以用一个概率模型更好地建模。
alec:
- 之前退化学习方法的缺点:退化模型是确定的,每个HR图像只能退化为一个特定的LR图像。但是某些情况下,退化可能和图像的内容是独立的。
- 因此我们可以将图像的退化假设为是一个分布,用概率模型建模或许更好。
在此基础上,我们提出了一种概率退化模型(PDM),该模型可以学习盲图像超分辨的退化分布,具体地说,我们用两个随机变量参数化退化,即模糊核k和随机噪声n, 通过将退化过程表述为一个线性函数:
alec:(点子,来自于PDM)
- 本文假设的模型的退化过程公式是:
- 这个顺序是确定的,先卷积退化核、然后下采样,然后添加噪声。
- 但是这个顺序也是预定义的。先卷积退化核K,然后下采样;和先下采样,然后卷积退化核K,效果不一定是一样的。因为B过程是建立在A过程的结果的像素图像上的。
- 采用哪个顺序,我们是未知的。这个公式中的降质因素:退化核、下采样、噪声。顺序的话一共有3x2x1种,一共6种。因此可以把这6种都加到模型中,比如放到一层中,作为同一层的卷积核。然后通过通道注意力机制,让模型在训练的过程中自适应的调整权重的强弱。
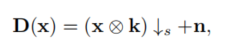
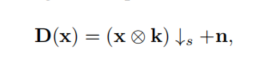
x表示HR图像,* 表示卷积操作,s _ss表示下采样和尺度因子,因此,D的分布可以表示为k和n的联合分布,这可以通过学习先验随机变量z到k和n的映射来建模。然后在对抗框架中训练PDM,在训练过程中自动学习D的分布,这样,PDM就可以对退化过程中的随机因素进行建模,更好地将退化与图像内容解耦,这在实际场景中可能是一种更实际的近似方法,因此,PDM可能更容易覆盖所有的测试图像的不同退化,并防止SR模型过拟合特定的图像,PDM可以作为一个数据生成器,并可以很容易地与现有的SR模型集成,以帮助它们提高应用程序中的性能。
我们的贡献可以总结如下:
1、 据我们所知,我们是第一个研究盲SR作为一个随机变量的退化,并试图通过一个概率模型来学习其分布,它允许我们建模更多样化的退化,并合成更接近测试图像领域的训练样本。
2、我们提出了一种概率退化模型(PDM),该模型可以对退化过程中的随机因素进行建模,更好地将退化与图像内容解耦,从而使盲SR的退化分布更容易学习。
3、我们仔细地重新实现和研究了不同的基于退化学习的SR方法,并提供了全面的比较
4、 在概率退化模型的基础上,我们进一步提出了一个统一的盲SR框架,它在主流基准数据集上实现了最先进的性能。
[√] 2、相关工作
[√] 基于预定义的退化
早期的SR方法通常是合成具有预定义退化的HR-LR样本,最广泛的设置是双边降采样,然而,一些研究然就人员开始意识到,这种合成数据与真实的测试图像存在域差距,当这些方法应用于实际应用时,这一差距将导致性能的显著下降。
因此,研究人员开始合成更复杂设置的样本,包括不同水平的多个模糊核(各向同性和各向异性)和随机噪声(加性的高斯白噪声),更大的退化空间使这些模型具有更好的泛化能力,但与实际场景中巨大的退化空间相比,预定义退化的多样性仍然有限,这些方法在大多数应用中仍然失败。
alec:
- 预定义的退化方式,多样性仍然有限,因此性能受限。
最近,进一步增加了预定义设置的重复退化,这在很大程度上扩大了它们的应用场景,然而,为了牺牲更好的泛化能力,它们也可能倾向于产生过于平滑的结果,我们将在实验部分(第4.2节)中进一步讨论它。
[√] 基于学习的退化
alec:
- 图像的退化方式,分为基于预定义的退化和基于学习的退化
[√] 确定性退化模型
为了生成更接近真实测试图像域的LR图像,一些方法选择了自适应的学习退化, 使用了一个具有线性卷积层的神经网络来建模模糊过程,该网络通过对抗性损失进行训练,这鼓励其输出图像更像测试图像,这样,该网络就可以学习到测试图像的模糊核;为了在退化图像中更好的保存内容,在CycleGAN框架中进一步训练非线性神经网络模型。
由于它们的退化是自适应学习的,这些方法可以为不同的测试图像定制一个SR模型,并且在真实场景中通常比基于预定义的基于退化方法性能更好,然而, 它们的退化模型是确定性的,而且它们可能无法模拟退化过程中的随机因素,这可能会限制它们的SR模型的性能。
alec:
- 基于确定性退化的模型,效果比基于预定义的退化方式好。
- 但是因为退化模型是确定的,无法模拟退化过程中的级因素,因此可能会限制SR模型的性能。
[√] 退化池
JI等人将退化模型建模为一个包含从测试图像中学习到模糊核和噪声的池, 然后利用退化池合成训练样本来训练SR模型,该方法与我们的PDM有相似的想法,并在NTIRE2020中取得了巨大的性能,然而,我们分别学习了模糊核和噪声,这涉及到 两个不同的任务,构建这样一个退化池是很困难和耗时的,而在我们的PDM中,模糊核和噪声是通经对抗性训练自动学习的,这要容易得多。
[√] 概率退化模型
为了模拟退化过程中的随机因子,在之前,HR图像在被神经网络退化之前与随机向量连接起来,虽然他们的模型考虑了随机因素,但它们不能很好地将退化与图像内容解耦,也没有提供退化的明确公式。
alec:
- 通过将随机向量和模型结合起来,来模拟退化过程中的随机因子。
随机向量和退化之间的关系尚不清楚,我们也不知道模型会学习到什么样的退化。因此,很难根据不同的场景来调整模型的设置,相反,在我们的PDM中,我们用模拟核k和随机噪声n来参数化退化,显式公式使我们能够灵活地调整模型,还将在第3.3节中进一步讨论。
[√ 3、学习退化过程的分布
公式1中的退化过程实际上包含两个线性步骤:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(D:\坚果云\Alec - backup files\typora pictures\43593a83402b4ab4b787f7f90b807506.png)(C:\Users\Administrator\Desktop\学习盲图像超分辨率的退化分布\image-20220407151802904.png)]](https://img-blog.csdnimg.cn/43593a83402b4ab4b787f7f90b807506.png)
从直观上看,这两步是相互独立的,因为模糊核主要依赖于相机镜头的特性,而噪声主要与传感器的特性有关,因此,退化分布可以建模为:
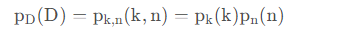
这样,k和n的分布就可以独立地建模来表示D的分布。
alec:
- 模糊核和噪声对图像的影响是独立的,因此可以独立的建模来表示退化过程。
[√] 3.1 核模型

[√] 3.2 噪声模型

[√] 3.3 概率退化模型
上面讨论的核模块和噪声模块共同形成了我们的概率退化模型(PDM), 如图2 所示,PDM用于合成HR-LR图像对。
alec:
- 核模块+噪声模块,共同组成了本文的概率退化模型。
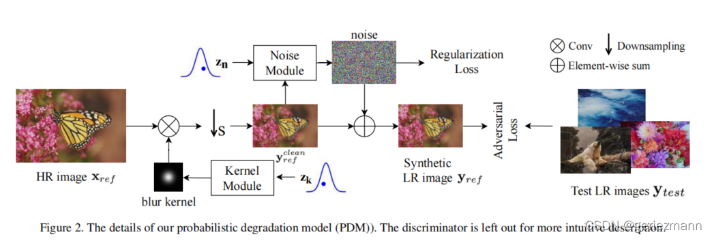
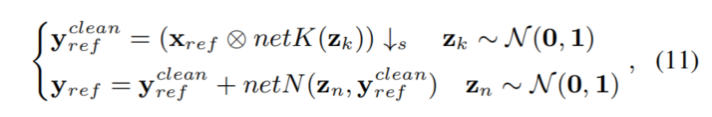
alec:
- To learn image superresolution, use a gan to learn how to do image degradation first,这个论文的模型简称为Degradation GAN
- 本文的思想和降质GAN类似,但是加入了自己定义的退化公式
- 对抗性训练,鼓励输出的LR图像与测试图像数据集的分布相似

首先,PDM能够模拟更多样化的退化,它允许一个HR图像退化为多个LR图像,因此,在相同数量的HR图像中,PDM可以生成更多样化的LR图像,为SR模型提供更多的训练样本,这可以更好地覆盖测试图像的退化,因此,PDM可以弥合训练数据集和测试数据集之间的差距,并帮助SR模型在测试图像上表现得更好

[√] 3.4 盲SR统一的框架
在之前,退化模型个SR模型的训练时分开的, 即它们首先训练一个退化模型,然后使用训练后的退化模型来帮助训练SR模型,这种两步训练方法很耗时,但对于其方法来说是必要的,因为它们的高度非线性退化模型会在训练开始时产生不良的结果,这可能会误导SR模型的优化,然而,在我们的方法中,由于PDM具有更好的约束性和更容易的训练性,因此它可以很好地同时训练PDM和SR模型,这样,PDM可以与任何SR模型集成,形成一个统一的盲SR框架,称为PDM-SR(如果SR模型的训练中也采用对抗性损失和感知损失,则称为PDM-SRGAN)。
alec:
- 之前提出的退化模型,退化过程和SR过程是分开的,因为刚开始的时候,退化过程对SR会造成不良的影响。由于本文提出的模型具有良好的约束性,本文的降质模型和退化模型是合到一起的,端到端的。
[√] 4、实验
[√] 4、1 实验设置
alec:
- track,踪迹、小道
[√] 数据集
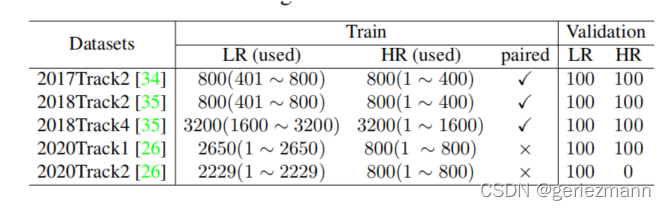
在本文中,我们主要研究没有配对的样本的情况,因此,对于每个数据集,我们只使用HR图像的前半部分和LR图像的后半部分进行训练,对于2020Track1和Track2,由于它们提供的训练样本是未配对的,所以直接使用所有图像进行训练
alec:
- 本文是进行的未配对的训练方式,即无监督训练。
[√] 实验细节

[√] 训练

[√] 4.2 与其他方法比较
- Bulat
- CinGAN
- DSGAN-SR
- CycleGAN
- Maeda

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(D:\坚果云\Alec - backup files\typora pictures\4799d32812914bde89e5dfa8493891bb.png)(C:\Users\Administrator\Desktop\学习盲图像超分辨率的退化分布\image-20220408170128200.png)]](https://img-blog.csdnimg.cn/4799d32812914bde89e5dfa8493891bb.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAZ2VyaWV6bWFubg==,size_20,color_FFFFFF,t_70,g_se,x_16)