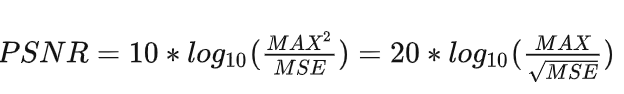本文最后更新于:3 个月前
链接:
图像超分辨率-Super Resolution(A2N) - 知乎 - 计算机视觉 - Renn(√)
项目完整代码:link here
paper:https://arxiv.org/abs/2104.09497
编辑于 2021-08-02 19:44
[√] 前言 AI世界斑斓多姿,计算机视觉给我们带来前所未有的视觉盛宴,超分辨率作为其中一个子领域亦是吸引很多研究学者,本文基于《Attention in Attention Network for Image Super-Resolution》这篇文章对单幅图像超分辨率(SISR)算法流程做一个详尽的介绍。
对于单幅图像超分算法主要分为两类:有监督方法(代表:SRCNN,ESPCN,EDSR等)和无监督方法(代表如:ZSSR),本文又主要针对有监督。
在有监督的算法中主要分为基于CNN和基于GAN的方法。
基于CNN的方法一般使用L1Loss和L2Loss损失函数,基于GAN的方法还需要感知损失和对抗损失。
就上采样来说传统为插值上采样,现在一般使用亚像素卷积和反卷积。
采样位置分为前上采样,渐进上采样和后上采样,现在更多使用后上采样。
如果想更快了解超分领域,不妨多看几篇综述类文章,这样能够对该领域有一个整体的了解。
alec:
现在主要使用后上采样
如果想更快了解超分领域,不妨多看几篇综述类文章,这样能够对该领域有一个整体的了解
[√] 效果展示
[√] 一、实验环境 [√] 1)硬件条件(可低一些)
OS: windows 10(x64)
GPU: NVIDIA GeForce RTX 3090(24G内存)
RAM:64G
CPU: Intel(R) Core(TM) i9-10900K
[√] 2)深度学习框架及相关库:
torch 1.8.1+cu111
torchvision 0.9.1+cu111
tqdm 4.61.0
visdom 0.1.8.9
h5py 3.3.0
ipdb 0.13.9
numpy 1.20.3
[√] 3)程序编写环境:
IDE: PyCharm Community Edition 2021.1.2 x64
解释器:python3.9
说明:我所实验的环境如此,只是参照,不一定要完全一样,实验环境配置这里不再赘述。
[√] 二、超分算法实现整体流程
超分算法网络结构实现。
数据集处理及增强。
超分网络训练。
PSNR及SSIM测试及效果展示。
[√] 三、详细流程 [√] 1)A2N网络结构介绍 单幅图像的超分算法很多,虽然每种算法网络结构不同,但是单幅图像超分算法整体实现流程基本一致,这里基于A2N网络来大概讲下基本结构。论文链接如下:
link: Attention in Attention Network for Image Super-Resolution
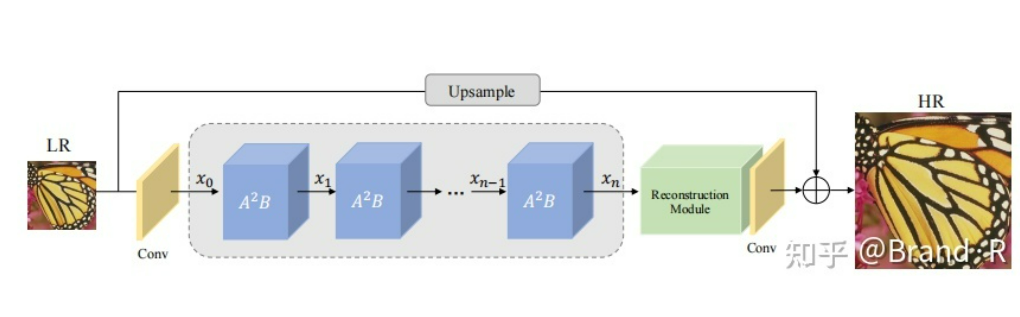
A2N网络结构图如下所示:
从上图我们可以看出,对于一张低分辨率图片(LR)输入网络时首先通过一个卷积层,然后经过n个A2B模块,之后再经过一个重建模块(里面包括上采样(插值)到指定尺寸),再经过一个卷积层,卷积之后的输出结果与最初输入的LR图的上采样(最近邻插值上采样,你也可以用其他插值算法咯)结果相加之后得到最终的效果图。没错,整个网络既没有用到亚像素卷积(Sub-pixel Convolution)也没用到反卷积(Transposed Convolution)这两种经典的上采样方式,而是使用传统的插值上采样。
alec:
整个网络没有用到亚像素卷积和反卷积,而是使用的最近点的插值上采样。
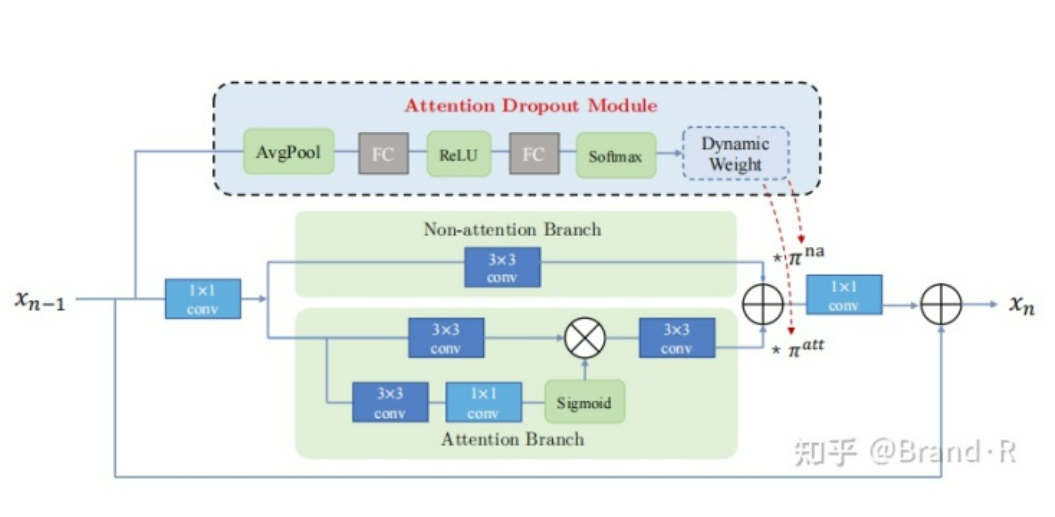
上面我们一览了整个网络结构,下面就要看下其子结构A2B模块了:
论文主要是基于注意力机制的改进,通常注意力机制有三类:通道注意力机制(channel attention),空间注意力机制(spatial attention)以及通道空间注意力机制(channel-spatial attention)。本文还是用的通道空间注意力机制,其相对于前两个效果更好些,不过作者认为注意力机制在网络中不总是有效的,所以又提出了attention dropout module方法最终形成A2B的模块。balabala…,这里就先不详细讨论注意力机制了。
alec:
注意力机制有三类:
通道注意力机制
空间注意力机制
通道-空间注意力机制
总之,通过作者的网络结构,我们给出A2B相应的实现代码(这里借鉴原作者的代码),算法整体代码文末有链接:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import functoolsimport torchimport torch.nn as nnimport torch.nn.functional as F class AAB (nn.Module):def __init__ (self, nf, reduction=4 , K=2 , t=30 ):super (AAB, self).__init__()1 , bias=False )1 , bias=False )0.2 , inplace=True )1 )False ),True ),False ),3 , padding=(3 - 1 ) // 2 , bias=False )def forward (self, x ):1 )0 ].view(a, 1 , 1 , 1 ) + non_attention * ax[:, 1 ].view(a, 1 , 1 , 1 )return out
说明 :对于网络结构介绍先说这么多,我们在实现一个算法时,必然先要了解其思想,所以就我的经验来说,当我复现一篇论文时,首先需要看懂论文中作者提出的新方法,在代码复现时,若作者提供源码可以先借鉴其源码(只是网络结构这部分代码,不是直接复制整个算法代码来跑,即使要用,先要全部看懂,这样才好改进),不然自己写网络结构有时容易出错,这会导致训练结果不理想,浪费没必要时间。在达到作者论文中的相近效果后再考虑添加自己一些想法并改进。因为超分算法整体流程基本一致,所以我们很多时候实现不同超分算法只需要更换网络结构那部分即可 ,其他地方做一些小改动即可再次训练。
alec:
我们在实现一个算法时,必然先要了解其思想。
当我复现一篇论文时,首先需要看懂论文中作者提出的新方法,在代码复现时,若作者提供源码可以先借鉴其源码。
在达到作者论文中的相近效果后再考虑添加自己一些想法并改进。
因为超分算法整体流程基本一致,所以我们很多时候实现不同超分算法只需要更换网络结构那部分即可 ,其他地方做一些小改动即可再次训练。
[√] 2)数据集处理
alec:
对于一张2K的图片,剪裁成400x400的多张图片,然后随机截取128x128大小作为标签HR,然后下采样指定倍数作为输入的LR图片。
alec:
用于超分训练和测试的数据集很多如:Set5,Set14,general-100,image91,div2k等等,网上很容易下载,一般情况我们可以在论文中了解作者使用的训练和测试数据集。
然而…….很多论文并不会详细说明如何处理数据集及训练。下面我结合自己经验来详细说下。在超分任务中,我们从网上下载的数据集一般不能直接用于训练(浪费,效果很差),需要先进行处理,方法如下(我们这里以div2k数据集来说明,其它类似),div2k数据集有1000张高清图(2K分辨率),其中800张作为训练,100张作为验证,100张作为测试。当我们需要训练网络时,并不是直接读入整张图片,需要先做处理。
1、对于800张训练图片,首先对其裁剪,设定你认为合适的尺寸和步长,你可以直接把每张图片裁剪成128x128的大小(一般使用的训练图片大小),然后每隔128个像素裁剪一次,这样裁剪的话一共可以得到120765张128x128的小图,en…..这样的话貌似训练集有点多呀,主要是训练起来太慢了,所以呢我们可以换个思路,把图片裁剪成480x480的大小,其他尺寸也行咯,看你高兴。步长看你设置,太小的话图片太多,我设的好像200吧,最后得到32096张图片,对于这个训练集还是可以的,但是这个图片还是比较大,我们训练时HR图片(作为标签使用)一般尺寸为128x128或者192x192,相应的LR输入图片是在HR的基础上插值下采样(2倍,3倍,4倍等)得到的。所以在实际训练时,虽然我们使用的是480x480大小,但是我们每次在480X480的图片上随机截取128x128或者192X192的大小作为训练所需尺寸。这样处理的训练集用来训练还是很不错滴。下面是一段裁剪图片的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import cv2import osdef clip_image (root ):for name in img_names]1 for path in img_paths:for i in range (0 , row, 200 ):for j in range (0 , col, 200 ):if i+480 >= row or j+480 >= col: continue 480 , j:j+480 ]'F:/dataset/SuperResolutionDataset/480x480DIV2K_train_HR' str (count)+'.png' )1
2、当我们得到480x480大小的训练集后,我们可以直接用来训练,读入图片然后随机截取128x128大小作为标签HR,然后下采样指定倍数作为输入的LR图片。我们也可以先做一些处理,比如把训练集转为h5文件(挺方便的),通过读入h5文件来训练。h5文件只是相当于对训练集换了个存储方式,读入后还是一样的处理(随机裁剪,下采样等)。h5文件转换代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import h5pyimport osdef create_h5_file (root, scale ):'D:/AProgram/data/4x_div2k_file.h5' , 'w' )'lr' )'hr' )for name in img_names]0 for img_path in img_paths:open (img_path).convert('RGB' )str (index), data=lr)str (index), data=hr)1
说明:当然啦,不想转也可不用转。至于h5文件怎么使用可以网上查查,很好理解。这里还需要说明的是,超分论文中下采样基本使用matlab的imresize方法,我这里使用的PIL.Image.BICUBIC来下采样,至于差异我目前的结果来看没啥差别,所以暂且不讨论两种不同下采样方法对结果的影响。
alec:
超分论文中下采样基本使用matlab的imresize方法,我这里使用的PIL.Image.BICUBIC来下采样,至于差异我目前的结果来看没啥差别,所以暂且不讨论两种不同下采样方法对结果的影响。
3、在上面处理好数据集后,我们实际训练时还会对数据进行增强,如水平翻转,垂直翻转,旋转90度等,具体咋做的看代码:
alec:
处理好数据集后,我们实际训练时还会对数据进行增强,如水平翻转,垂直翻转,旋转90度等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 import torchimport h5pyimport randomfrom torch.utils import dataclass DataSet (data.Dataset):def __init__ (self, h5_file_root, patch_size=48 , scale=4 ):super (DataSet, self).__init__() @staticmethod def random_crop (lr, hr, size, upscale ):0 , lr.shape[2 ]-size)0 , lr.shape[1 ]-size)return lr, hr @staticmethod def random_horizontal_flip (lr, hr ):if random.random() < 0.5 :2 ])2 ])return lr, hr @staticmethod def random_vertical_flip (lr, hr ):if random.random() < 0.5 :1 ])1 ])return lr, hr @staticmethod def random_rotation (lr, hr ):if random.random() < 0.5 :2 , 1 ))2 , 1 ))return lr, hrdef __getitem__ (self, index ):with h5py.File(self.h5_file, 'r' ) as f:'hr' ][str (index)][::])'lr' ][str (index)][::])return lr, hrdef __len__ (self ):with h5py.File(self.h5_file, 'r' ) as f:return len (f['hr' ])
说明:上面是数据集(h5格式)载入及增强处理,然后就可以直接训练了。训练过程的验证集取div2k中100张验证图片几张裁剪即可,我使用的5张。这儿不知道大家是否有疑问?上面的数据增强处理是否每个epoch都变化?答案是的,这个你需要了解torch的DataLoader这个东西。
[√] 3)超分网络训练 对于网络训练部分只说要点,代码就直接去看我的GitHub。
1、训练一般使用adam优化器,真的好用,至于为什么可以看我的这篇文章:
link:SGD、Adam等深度学习优化算法综述
alec:
adam优化器,在梯度下降的时候,即自适应的调整学习率,同时结合了动量法来调整梯度。
adam算法,既是自适应学习率,也是考虑动量的方法。ada + m。
所以通常来讲,可以考虑默认使用adam作为优化算法,优化学习率和梯度这两个点
2、学习率很多设置1e-4或者5e-4,这个不一定,需要根据实际来看,batch_size一般为16或者32,不过batch_size太大,内存可能顶不住,看自己情况。(可以这样batchsize=16对应lr=1e-4,batchsize=32对应lr=5e-4),一般情况batch_size加倍,学习率也加倍,至于为什么自己寻找答案吧,实在说不完了。
alec:
学习率很多设置1e-4或者5e-4,这个不一定,需要根据实际来看,batch_size一般为16或者32,不过batch_size太大,内存可能顶不住,看自己情况。
batchsize=16对应lr=1e-4,batchsize=32对应lr=5e-4
3、损失函数一般为L1Loss,L2Loss,L1_Charbonnier_loss等,现在基本用L1Loss,我的实验很多时候L1_Charbonnier_loss效果好些,L1,L2会带来结果有些失真,这是没办法,解决的话可以使用GAN来训练,加上感知损失和对抗损失。
4、一般需要训练多久呢?基于上面得到的数据集和batchsize=32和lr=5e-4,我训练了500个epoch(先训练了300epoch,觉得还可以涨,又训练了200epoch),花了25小时左右吧。PSNR率高于论文中的结果(2倍超分)。
alec:
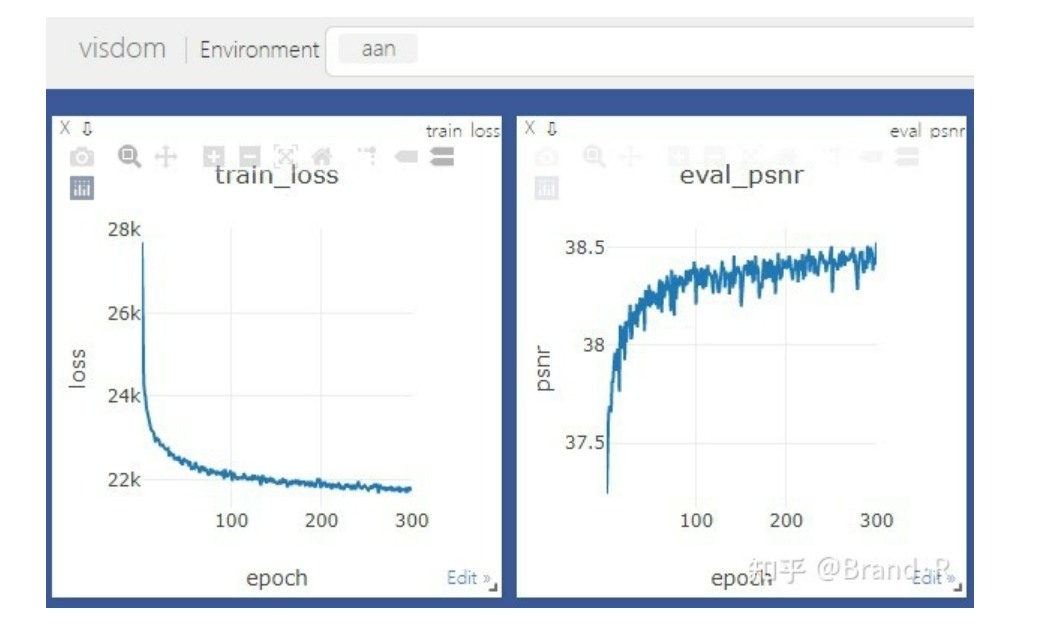
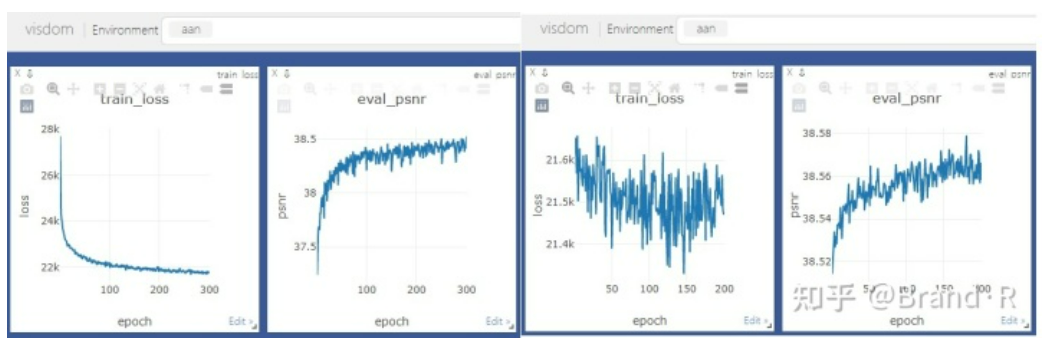
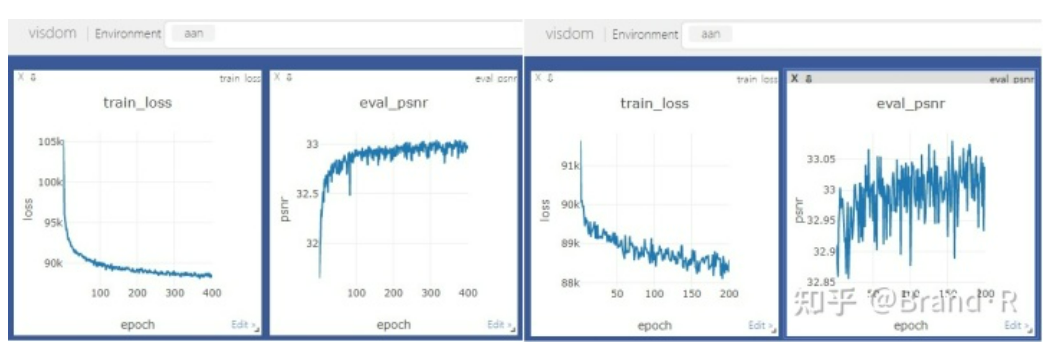
5、训练最好加上验证和可视化,可视化使用visdom,visdom使用比较简单,可快速了解使用。效果如下:
6、有时我们需要载入之前训练好的模型来训练当前网络,但之前模型和现在网络结构又存在一些不同(相同就更简单了,直接载入就行),可使用如下代码来迁移模型参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def transfer_model (pretrain_file, model ):return modeldef transfer_state_dict (pretrain_dict, model_dict ):0 for k, v in pretrain_dict.items():if k in model_dict.keys():1 if count == 0 :print ('no parameters update!!!' )else :print ('update successfully!!!' )return state_dict
使用的话就两行代码,如下示例:
1 2 net = AAN()'best_2xAAN_weight.pth' , net)
[√] 4)PSNR及SSIM测试及效果展示 1、PSNR(峰值信噪比)公式:
说明:MSE(均方误差)容易计算,MAX表示图片最大像素值,如果像素值为【0,255】则MAX=255,如果像素值为【0,1】则MAX=1。实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import torchimport osdef denormalize (img ):return img.mul(255.0 ).clamp(0.0 , 255.0 )def convert_rgb_to_y (img ):return 16.0 + (65.738 * img[0 ] + 129.057 * img[1 ] + 25.046 * img[2 ])/256.0 def calculate_psnr (sr, hr, max_val=255.0 ):return 10.0 *torch.log10((max_val**2 )/((sr-hr)**2 ).mean())def PSNRRGB (root, scale ):for name in img_names]'D:/AProgram/SR/AAN/best_4xAAN_weight.pth' )0 for path in img_paths:open (path).convert('RGB' )0 )if opt.cuda:with torch.no_grad():0 )print ('PSNR:{:.3f}' .format (res/len (img_paths)))
alec:
pytorch网络输出为tensor类型,值在0-1,所以有时需要转到0-255。
RGB转Y通道,因为一般测试PSNR在YCbCr颜色空间的Y通道(亮度通道)。
裁剪边缘部分,很多论文测试结果都加了边界裁剪
preds = preds[scale:-scale, scale:-scale]
labels = labels[scale:-scale, scale:-scale]
2、SSIM(结构相似比)代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 def SSIM (root, scale ):for name in img_names]'D:/AProgram/SR/AAN/best_4xAAN_weight.pth' )0 for path in img_paths:open (path).convert('RGB' )input = to_tensor(lr).unsqueeze(0 )if opt.cuda:input = input .cuda()with torch.no_grad():input ).squeeze(0 )print ('SSIM:{:.4f}' .format (res / len (img_paths)))def calculate_ssim (img1, img2 ):0.01 * 255 )**2 0.03 * 255 )**2 11 , 1.5 )1 , window)[5 :-5 , 5 :-5 ]1 , window)[5 :-5 , 5 :-5 ]2 2 2 , -1 , window)[5 :-5 , 5 :-5 ] - mu1_sq2 , -1 , window)[5 :-5 , 5 :-5 ] - mu2_sq1 , window)[5 :-5 , 5 :-5 ] - mu1_mu22 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2))return ssim_map.mean()
说明:上述代码未加导入库,不能直接使用,完整代码中查看。
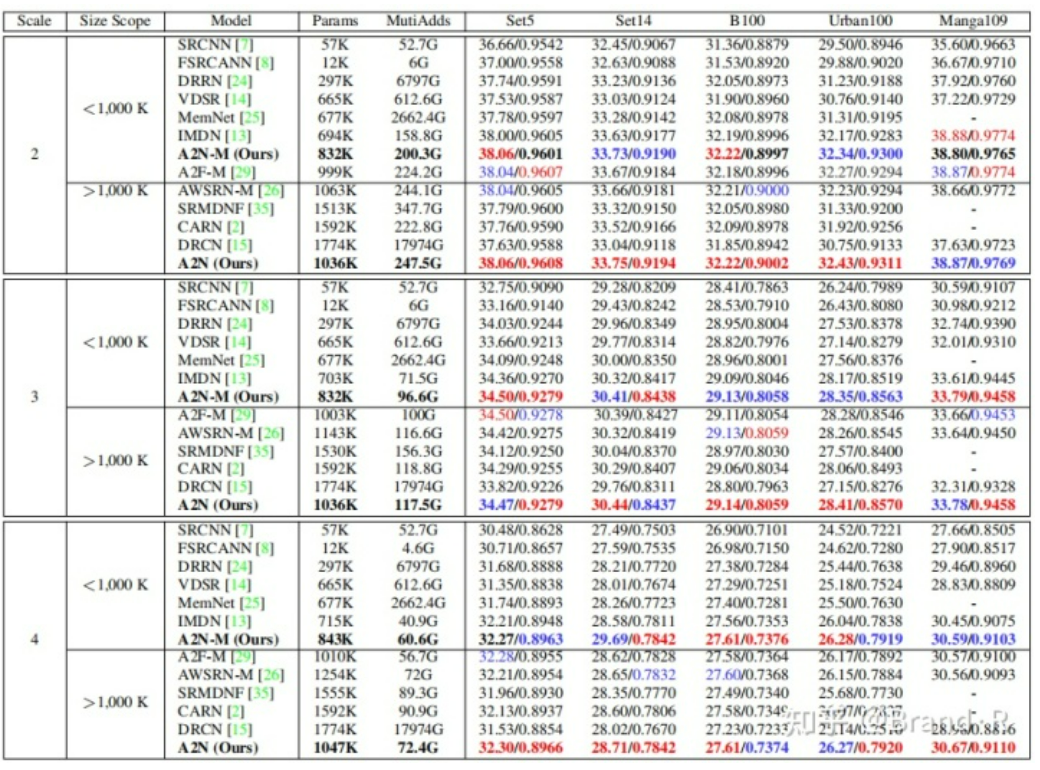
3、实验结果展示:
这里我说下我训练时超参的设置:
对于2倍超分:我使用裁剪的480x480div2k数据集,然后转了h5文件。数据增强主要是水平翻转,垂直翻转和顺时针旋转90度。batch_size=32,lr=5e-4,epoch=500。优化器为adam,损失为L1_Charbonnierloss,numworkers=10。
对于4倍超分:我使用裁剪的480x480div2k数据集,然后转了h5文件。数据增强主要是水平翻转,垂直翻转和顺时针旋转90度。batch_size=32,lr=5e-4,epoch=200。优化器为adam,损失为L1_Charbonnierloss,numworkers=10。这次是利用了2倍模型参数。
说明:可以看到,基于2x模型训练的4x结果要好些。不知道这里大家是否有个疑问?为啥损失这么大?因为用了L1_Charbonnierloss损失,为啥呢?嘿嘿,自己看看这个损失函数就知道啦。同时说下,这里的波动是正常的。
Set5(PSNR/SSIM)
Set14(PSNR/SSIM)
2x
38.088/0.9610
33.837/0.9197
4x
32.269/0.8959
28.750/0.7868
说明:上面表格是我的初步结果,还在优化中,当然啦,结果略高于论文结果,下面是作者论文中的结果,可以参考下,因为这里的对比都是基于同量级的模型,自然比不上那些大模型的效果。现在最好的结果大家可以去paperwithcode这个网站查看,也顺便推荐下这个网站,很不错。
alec:
“这里的对比都是基于同量级的模型,自然比不上那些大模型的效果。” 模型的对比应该是在相同的参数量的前提下,用大模型来对比小模型的效果,是不公平的。
说明:其实上面很多结果都是基于双三次插值退化模型,训练也是基于此,所以结果还不错,当运用到真是场景效果就不一定了。
由于篇幅过长,不能面面俱到,以下问题大家可以自行查阅,一起交流,不再赘述:
1、如今单幅图像超分基本不使用Batch Normalization为何呢?
alec:
EDSR的作者认为,批量归一化会丢失图像的规模信息,并降低激活的范围灵活性。删除批量归一化层不仅可以提高超分辨率性能,还可以将 GPU 内存减少多达 40%,以便可以训练更大的模型。
2、L1Loss,L2Loss,L1_Charbonnier_loss不同之处,各自特点?
3、亚像素卷积和反卷积具体咋实现,各自特点?
alec:
sub-pixel请参考: Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network 可以减少计算时间和轻量化网络模型。
4、前上采样和后上采样有何不同,各自有何特点?
5、如何更好训练GAN,如何实现感知损失和对抗损失?
alec:
如何实现感知损失? 使用预训练的VGG-net提取图片特征。具体参考李飞飞2016年论文。Perceptual Losses for Real-Time Style Transfer and Super-Resolution
6、LapSRN可实现同时多个尺寸超分,Meta-SR可实现任意尺寸超分。
7、PSNR及SSIM评价指标是否合理?
alec:
目前有其他指标,比如MS-SSIM,LPIPS, ZNCC等等,从图像结构吗,感知质量等等不同角度对图像进行评价。不过最基本的指标是PSNR和SSIM。
8、现在超分基本都是基于双三次插值退化模型的超分,用于真实环境效果不是很理想。
alec:
现在超分基本都是基于双三次插值退化模型的超分,用于真实环境效果不是很理想:有些超分针对特定的退化核,比如移动模糊,成像的马赛克化。最近两年这类论文尤其多。
9、如何部署网络模型到移动端?
10、训练中net.train()和net.eval()有何作用?
alec:
net.train()用在反向传播和更新梯度之前,代表接下来的操作计算网络梯度。net.eval()不计算网络梯度。
alec:
如今SISR基本不使用BN了。
现在基本都使用后端上采样。
LapSRN可实现同时多个尺寸超分,Meta-SR可实现任意尺寸超分。
基于双三次插值退化模型的超分,在真实场景下不是很理想。
[√] 参考 [1] Attention in Attention Network for Image Super-Resolution
[2] https://github.com/xinntao/BasicSR
[3] Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks