062 - 文章阅读笔记:NTIRE 2022 冠军方案:用于轻量级图像超分辨率的蓝图可分离残差网络(CVPR workshop) - 知乎 - 极市平台 - Ziyang Li
本文最后更新于:3 个月前
原文链接:
NTIRE 2022 冠军方案:用于轻量级图像超分辨率的蓝图可分离残差网络(CVPR workshop) - 知乎 - 极市平台 - Ziyang Li
发布于 2022-06-02 10:31
ps:本文为依据个人日常阅读习惯,在原文的基础上记录阅读进度、记录个人想法和收获所写,关于原文一切内容的著作权全部归原作者所有。
- 整理文章
【引言】
本文要解决的问题是:超分模型因为资源受限问题,难以在移动端部署。
本文提出了蓝图可分离残差网络,引入更有效注意力操作的同时摒弃传统冗余卷积操作
【痛点】
模型容量大、计算复杂
大量冗余的卷积
本文提出的BSRN,主要针对优化卷积操作和引入有效的注意力模块两个方面来展开
【本文思想】
文章中使用的BSConv蓝图卷积,是CVPR 2020中论文《Rethinking Depthwise Separable Convolutions: How Intra-Kernel Correlations Lead to Improved MobileNets》所提出的
[===蓝图卷积的简析===]
作者等人对卷积核可视化后发现,同一层的卷积核是类似的,能够通过简单的线性变换得到。
蓝图 = 模板 = 样本 = 例子
对于普通卷积来讲,每个卷积核是三维的,一个卷积核的C个通道的卷积核都是独立学习的。但是可视化发现这C个卷积核是类似的,能够通过线性变化得到。因此这里为了轻量化,提出了蓝图卷积。即不是学习C个二维卷积核,而是学习一个二维卷积核蓝图,然后剩下的C-1个卷积核通过一个可学习的C维的权重向量与蓝图组合来表示。
无限制的蓝图卷积可视为深度可分离卷积的逆过程。
- 深度可分离卷积:先卷积,然后再对深度方向上加权组合
- 无限制蓝图卷积:先对卷积核在深度方向上加权组合,然后再卷积
[===RSDB,高效可分离蒸馏块===]
- 相加多为残差连接方式,相乘多为注意力机制。
- 在ESDB中,conv-1用于特征蒸馏,BSRB用于特征浓缩,注意力模块CCA和ESA用于特征增强
-CCA负责通道注意力,计算注意力的方式为均值加标准差的和的对比信息来作为注意力
-ESA负责计算空间注意力
[√] 文章信息
本文首发于极市平台,作者: @Ziyang Li ,转载须经授权并注明来源
为解决单幅图像超分辨率(SISR)领域普遍存在的难部署于资源受限设备的问题,本文提出蓝图可分离残差网络,引入更有效注意力操作的同时摒弃传统冗余卷积操作,性能达到目前高效SR方法中的SOTA。代码即将开源~

论文题目:Blueprint Separable Residual Network for Efficient Image Super-Resolution
中文题目:能够有效超分的蓝图可分离残差卷积
论文链接:https://arxiv.org/abs/2205.05996
论文代码:https://github.com/xiaom233/BSRN
论文发表:CVPR 2022
[√] 一、单幅图像超分辨率领域的一大痛点
单幅图像超分辨率(SISR,以下简称SR)旨在由低分辨率输入重建并输出高分辨率图像,然而现有方法普遍存在模型容量大、计算复杂(密集层连接策略)等特点。
对于更看重实际推理速度的现实场景而言,能做到轻量且有效的方法更被青睐。
而在现有流行的SOTA模型之一——RFDN中,一个明显的问题便是其存在大量冗余的卷积操作,这些冗余不可避免的为模型带来计算负担。
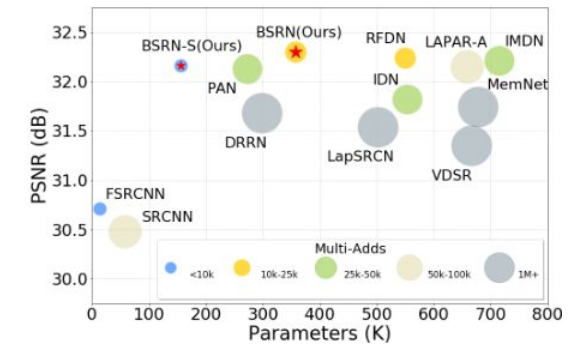
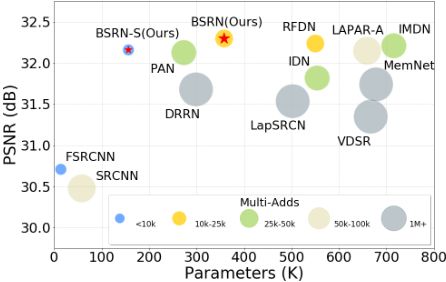
因此本文设计轻量级的蓝图可分离残差网络(BSRN)来解决上述问题,主要针对优化卷积操作和引入有效注意力模块两个方面展开。其简单性能对比如下所示:
[√] 二、如何解决?——BSRN深度剖析

图2:BSNR整体架构示意图。 如图2所示,BSNR由四个部分所构成:浅层特征提取、深层特征提取、多层特征融合以及图像重建。
在第一个BSConv(蓝图卷积)之前,输入图片被简单复制并沿通道维度连接至一起。此处BSConv的作用是扩展通道至更高维度并进行浅层特征提取。
其中BSConv为CVPR 2020中论文《Rethinking Depthwise Separable Convolutions: How Intra-Kernel Correlations Lead to Improved MobileNets》所提出,这里仅做简要介绍:
alec:
- BSConv = 蓝图可分离卷积方式
[√] 简析蓝图卷积(BSConv)
蓝图卷积与GhostNet有异曲同工之妙,作者等人对卷积核进行可视化后,发现很多卷积核呈现类似的分布(即类似于一个模子/蓝图,经过不同线性变换得到),如下图:

因此可将蓝图卷积表示如下(卷积核由蓝图内核(即一个K×K的卷积核)和一个M×1的权重向量组成):
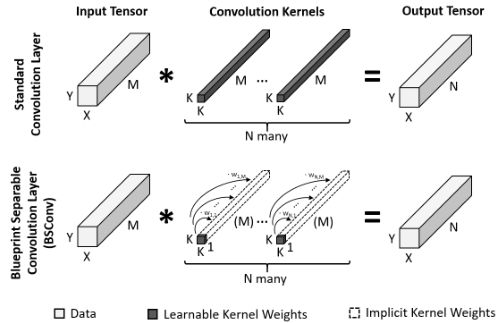
图4:蓝图卷积(BSConv)示意图。BSConv 使用一个 2d 蓝图内核来表示每个过滤器内核,该 2d 蓝图内核使用权重向量沿深度轴分布。
那么具体如何实现这样的卷积呢?对于BSConv-U(无限制蓝图卷积)来说,可视为深度可分离卷积的逆过程,即先对深度方向上加权组合再卷积,如下图所示:
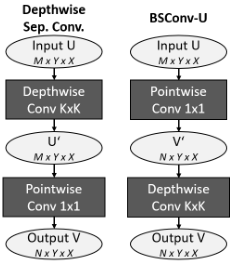
图5:BSConv-U实现过程示意图。
即与深度可分离卷积(DSC)相比,DSC相当于隐式地假设一个用于所有内核的3D蓝图,而BSConv则是依赖于每个内核的单独2D蓝图。
回到图2,深层特征提取部分中顺序堆叠的若干个ESDB被用于提取并细化深度特征。同时不同阶段/深度的特征输出在多层特征融合部分被连接至一起,并通过1×1卷积和GELU函数进行进一步融合和映射。
图像重建之前,再次使用BSConv来细化融合并映射后的特征,同时一个横跨多个ESDB的残差连接被应用于重建前的特征。
最终的图像重建过程由一个标准3×3卷积层和pixel-shuffle操作组成,同时用如下损失函数进行优化(其中$I_{SR}$表示模型输出):
$$
L_1 = ||I_{SR} - I_{HR}||_1
$$
alec:
- 蓝图 = 模板 = 样本 = 例子
- 对于普通卷积来讲,每个卷积核是三维的,一个卷积核的C个通道的卷积核都是独立学习的。但是可视化发现这C个卷积核是类似的,能够通过线性变化得到。因此这里为了轻量化,提出了蓝图卷积。即不是学习C个二维卷积核,而是学习一个二维卷积核蓝图,然后剩下的C-1个卷积核通过一个可学习的C维的权重向量与蓝图组合来表示。
- 无限制的蓝图卷积可视为深度可分离卷积的逆过程。
- 深度可分离卷积:先卷积,然后再对深度方向上加权组合
- 无限制蓝图卷积:先对卷积核在深度方向上加权组合,然后再卷积
- DSC = 深度可分离卷积
- BSConv = 蓝图可分离卷积
[√] 模型核心组件——高效可分离蒸馏块(ESDB)剖析
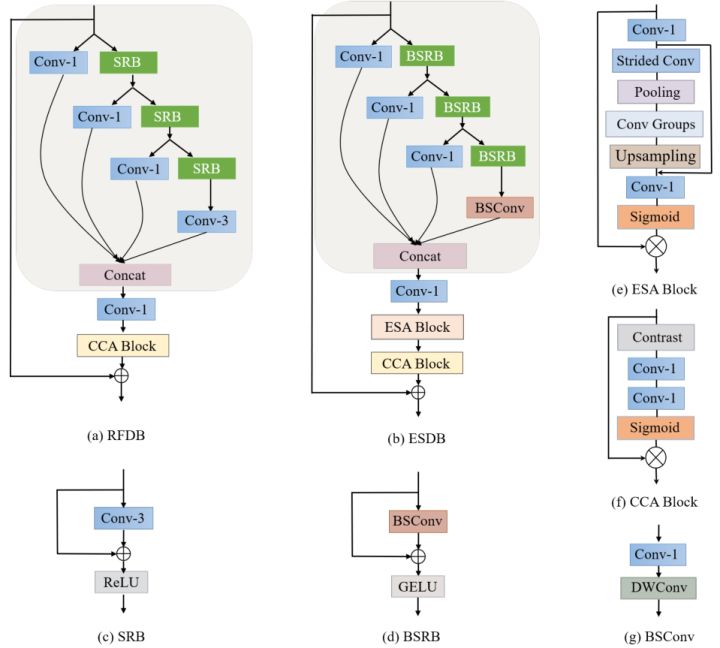
图6:ESDB及部分细节示意图。
如图6 (b),ESDB由三个部分所构成:特征蒸馏(Conv-1)、特征浓缩/细化(BSRB)及特征增强(注意力模块)。
各级特征依次通过并行的蒸馏、浓缩操作,并在最后沿通道维度拼接起来,辅以1×1卷积进一步浓缩特征。
其中BSRB代表蓝图浅残差块,它以上述所介绍的无限制蓝图卷积为基础,辅以残差连接与GELU激活函数所组成。
为什么要使用蓝图卷积而不是其他的轻量级卷积操作呢?是因为作者等人考虑到,此前有大量研究证明在多数情况下蓝图卷积对标准卷积表现出更好的分离表现,因此使用蓝图卷积在轻量化的同时保持模型性能。其简单对比结果如下表所示:

表1:基于RFDN的不同卷积分解方式性能对比。
在模块的尾部,添加了两个不同的注意力模块来进一步提高模型表现能力。ESA代表增强空间注意模块(详见论文),其实现如图6 (e)所示。CCA则代表对比度感知通道注意模块(详见论文),其实现如图6 (f)所示,CCA不同于以往利用全局平均池化后的特征计算出的通道注意力,而是利用平均值与标准差之和的对比信息来计算通道注意力。
需要注意的是,论文中将ESA中的卷积替换为蓝图卷积,旨在减轻注意力计算带来的额外负担。
本文将两种不同的注意力方法设计为串联形式,先空间后通道。笔者思考CBAM中先通道后空间的方式,CBAM中作者等人对先空间后通道、先通道后空间、通道与空间并行这三种不同的注意力顺序进行了一些对比实验,最终先通道后空间的形式性能权衡最好。因此尚不清楚本文中两种不同的注意力模块交换次序后是否会带来更好的效果。
alec:
- ESDB = efficient separable distill block
- 相加多为残差连接方式,相乘多为注意力机制。
- 在ESDB中,conv-1用于特征蒸馏,BSRB用于特征浓缩,注意力模块CCA和ESA用于特征增强。
- DSConv = 深度可分离卷积
- BSConv = 蓝图可分离卷积
- ESA和CCA都是注意力模块,这两个模块串联
- CCA不同于以往使用全局平均池化后的数据作为注意力加权到通道上,而是通过使用均值和标准差的和的对比信息来计算通道注意力。
[√] 三、性能对比
论文进行了大量详细的性能对比实验,其与各种流行的SOTA方法比较结果如下:
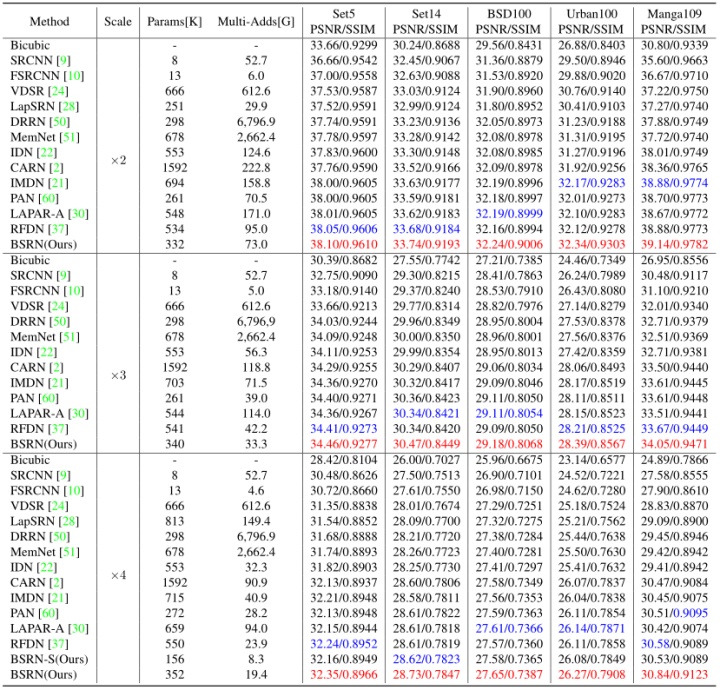
表2:BSNR与各流行SOTA方法性能对比结果。
其可视化结果如下:

图7:BSNR与各流行SOTA方法可视化结果。
其实际推理速度对比如下:
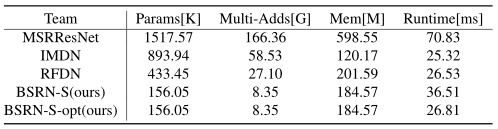
表3:BSNR与其他方法计算成本对比。
[√] 四、思考与总结
本文以轻量且有效为目标,提出针对优化卷积与引入注意力两方面的BSNR方法,性能得到有效提升。
然而本文针对参数量展开对比,在在现实场景中实际推理速度更被看重,而作为理论分析的参数量仅仅是物理设备上推理时间的一种表示。
在表3中本文方法与RFDN进行对比,尽管参数量大幅度减少,实现了理论级别的“轻量化”,然而Runtime指标却出现意料之外的上升。
显然,本文的方法更为耗时。满足理论意义上的“轻量化”似乎并不能很好实现本文最初的目标,即解决难部署于资源受限设备上的问题。
但蓝图卷积的成功引入,注意力方法的成功应用,都给了我们一定启发,即使注意力会带来额外的计算负担,也可以用蓝图卷积在保持性能的同时去减轻一定负担。
期待未来能看到更多看重实际应用的工作出现~
[√] 往期精选
数据集汇总:
- 人脸识别常用数据集大全
- 行人检测数据集汇总
- 10个开源工业检测数据集汇总
- 21个深度学习开源数据集分类汇总(持续更新)
- 小目标检测、图像分类、图像识别等开源数据集汇总
- 人体姿态估计相关开源数据集介绍及汇总
- 小目标检测相关开源数据集介绍及汇总
顶会资源:
- CVPR 2022 全面盘点:最新250篇论文分方向汇总 / 代码 / 解读 / 直播 / 项目(更新中)
- CVPR’22 最新106篇论文分方向整理|包含目标检测、动作识别、图像处理等32个方向
- 一文看尽 CVPR2022 最新 22 篇论文(附打包下载)
- 17 篇 CVPR 2022 论文速递|涵盖 3D 目标检测、医学影像、车道线检测等方向CVPR 2021 结果出炉!最新500篇CVPR’21论文分方向汇总(更新中)
- CVPR 2020 Oral 汇总:论文/代码/解读(更新中)
- CVPR 2019 最全整理:全部论文下载,Github源码汇总、直播视频、论文解读等
- CVPR 2018 论文解读集锦(9月27日更新)
- CVPR 2018 目标检测(object detection)算法总览
- ECCV 2018 目标检测(object detection)算法总览(部分含代码)
- CVPR 2017 论文解读集锦(12-13更新)
- 2000 ~2020 年历届 CVPR 最佳论文汇总
技术综述:
- 综述:图像处理中的注意力机制
- 搞懂Transformer结构,看这篇PyTorch实现就够了
- YOLO算法最全综述:从YOLOv1到YOLOv5
- 图像匹配大领域综述!涵盖 8 个子领域,近 20年经典方法汇总
- 一文读懂深度学习中的各种卷积
- 万字综述|核心开发者全面解读Pytorch内部机制
- 19个损失函数汇总,以Pytorch为例
理论深挖:
论文盘点:
实践/面经/求学:
- 如何配置一台深度学习工作站?
- 国内外优秀的计算机视觉团队汇总
- 50种Matplotlib科研论文绘图合集,含代码实现
- 图像处理知多少?准大厂算法工程师30+场秋招后总结的面经问题详解
- 深度学习三十问!一位算法工程师经历30+场CV面试后总结的常见问题合集(含答案)
- 深度学习六十问!一位算法工程师经历30+场CV面试后总结的常见问题合集下篇(含答案)
- 一位算法工程师从30+场秋招面试中总结出的目标检测算法面经(含答案)
- 一位算法工程师从30+场秋招面试中总结出的语义分割超强面经(含答案)
Github优质资源:
发布于 2022-06-02 10:31