042 - 文章阅读笔记:ECCV2020 Workshop-PAN-270k参数量SISR网络 | Efficient Image Super-Resolution Using Pixel Attention - CSDN - chenzy_hust
本文最后更新于:3 个月前
原文链接:
于 2020-10-08 12:21:53
[√] 论文信息
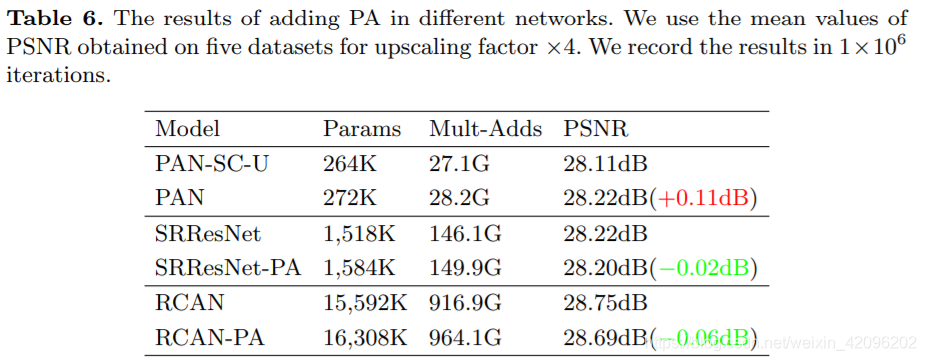
只说了参数量却没有比较速度,此外PA应用在大的网络中会降低性能!
论文地址:https://arxiv.org/pdf/2010.01073.pdf
Github地址:https://github.com/zhaohengyuan1/PAN

[√] 摘要
这项工作旨在设计一种用于图像超分辨率(SR)的轻量级卷积神经网络。在不考虑简单性的情况下,我们使用新提出的像素注意力方案构建了一个非常简洁有效的网络。
像素注意力(PA)类似于公式中的通道注意力和空间注意力。不同之处在于,PA生成3D注意力图而不是1D注意力矢量或2D图。该注意力策略引入了较少的附加参数,但生成了更好的SR结果。
在PA的基础上,我们分别为主分支和重建分支提出了两个构造块。第一个-SC-PA块的结构与自校准卷积相同,但具有我们的PA层。由于其双分支架构和注意力方案,该模块块比常规的残差/密集块效率更高。
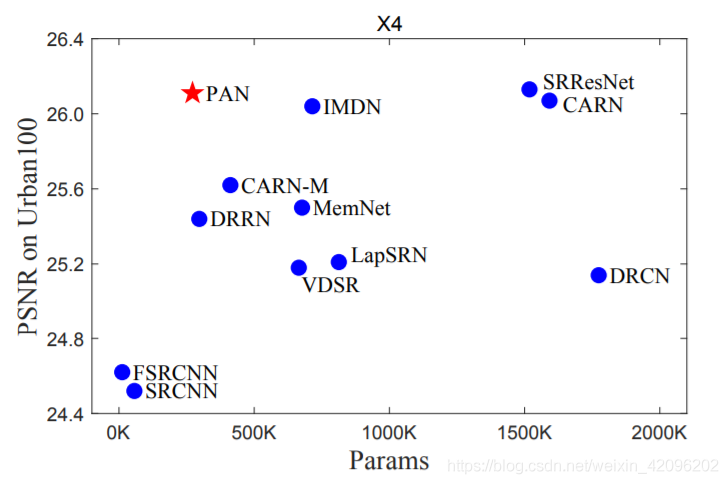
而第二个-UPA块结合了最近邻上采样,卷积和PA层。它以很少的参数成本提升了最终的重建质量。我们的最终模型PAN可以达到与轻量级网络SRResNet和CARN相似的性能,但是参数只有272K(SRResNet的17.92%和CARN的17.09%)。每个提出组件的有效性也通过消融研究得到验证。
alec:
- PA = 像素注意力
- 自校准卷积
- 上采样模块将最近邻上采样、卷积、PA层结合,其实就是一个串联(最近邻 + 卷积 + PA + 卷积)
[√] PAN
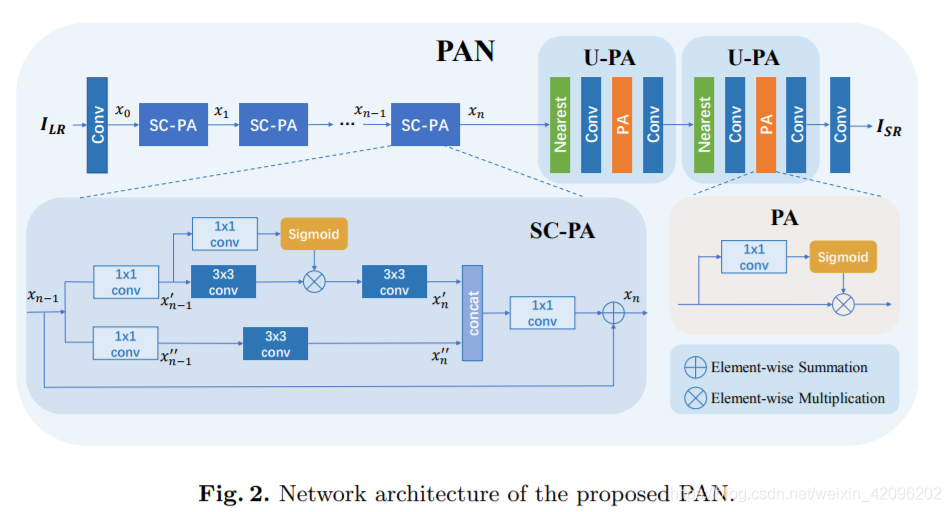
主要在main分支提出了SC-PA模块(SC+PA)和重建分支的U-PA块。SC是SCNet中的自校准卷积https://blog.csdn.net/weixin_42096202/article/details/105876498,PA就是H X W X C维度的注意力权重,其他网络早已经提出并使用了。
alec:
- PA是H x W x C维度的注意力权重,所以叫像素卷积,注意力落到每个像素上。
- SC是SCNet中的自校准卷积。
[√] Pixel Attention Scheme(PA)
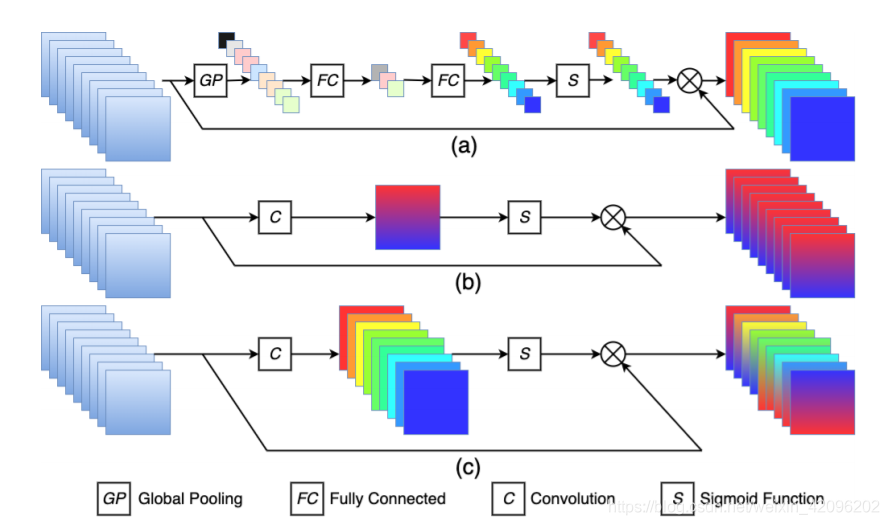
alec:
- 如上图所示,
- 图a是通道注意力,先通过全局池化,然后通过全连接,最后通过s型激活函数,得到维度为1x1xc的注意力权重,权重落到每个通道上,所以叫通道注意力。
- 图b是空间注意力,先通过卷积,然后通过s型激活函数,得到一个hxwx1维度的注意力权重,权重对于每个通道中的相同位置对应的像素都是一样的,所以叫空间注意力。
- 图c是像素注意力,通过卷积,然后通过s型激活函数,得到一个hxwxc的注意力权重,然后逐像素的乘以原图层,因为注意力是落到每个像素上,所以叫像素注意力。
与通道/空间注意力机制的区别就是:
1.通道注意力生成1x1xC维度的注意力权重
2.空间注意力生成hxwx1维度的注意力权重
3.像素注意力生成hxwxc维度的注意力权重
网络结构也非常简单,就是1x1卷积+sigmoid激活函数。
alec:
- 计算像素注意力的分支中,使用的卷积函数为1x1卷积。
[√] SC-PA Block
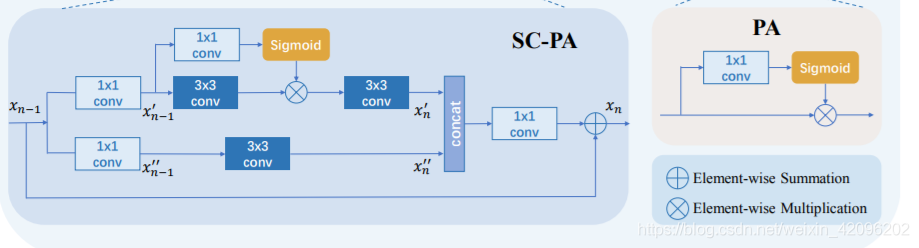
与SCNet中的SCConv有区别,对输入xn-1先使用两个1x1卷积进行分离,然后经过两个分支进行特征提取拼接。其中上分支使用带PA的网络结构。
[√] U-PA Block
结构比较简单,采用NN+Conv+PA+Conv结构,其中NN是最近邻上采样。
在以前的SR网络中,重构模块基本上由上采样和卷积层组成。 而且,很少有研究者调查过上采样阶段的注意力机制。 因此,在这项工作中,作者在重建模块中采用了PA层。 实验表明,引入PA可以显着提高最终性能,而参数成本却很少。 此外,本文还使用最近邻插值层作为上采样层以进一步节省参数。
alec:
- 本文创新的在上采样部分加入了注意力机制(上采样注意力)
[√] 实验
[√] 1.消融实验
[√] A. CA/SA/PA比较
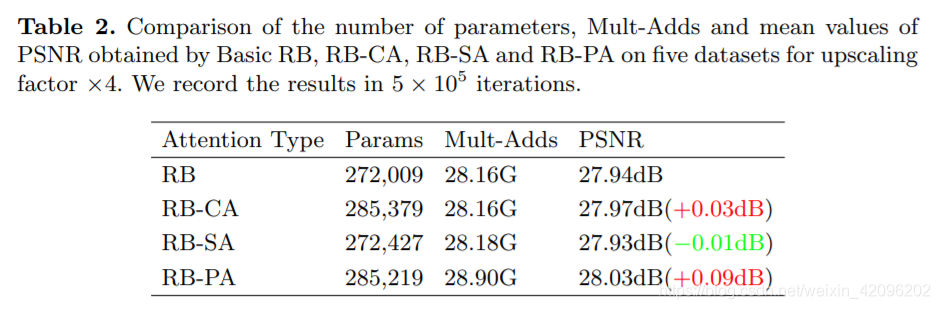
[√] B. RB-PA/SC-PA比较
alec:
- SC = self correct。自校准。
- 该实验对比RB-PA和SC-PA,证明自校准卷积的有效性。
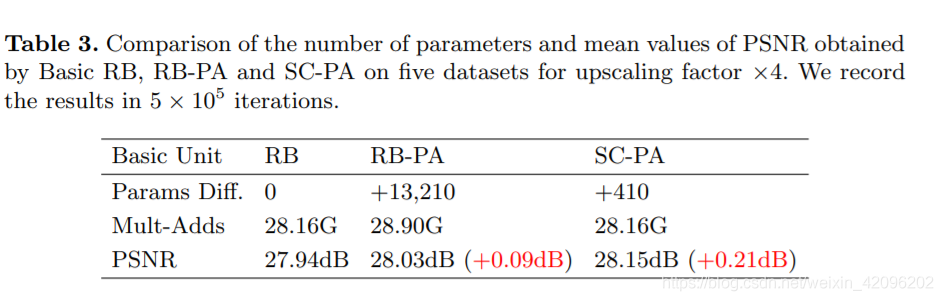
alec:
- 该实验表明,自校准卷积,在性能提升的同时。能够大大地节省参数量。
[√] C. PA带来增益
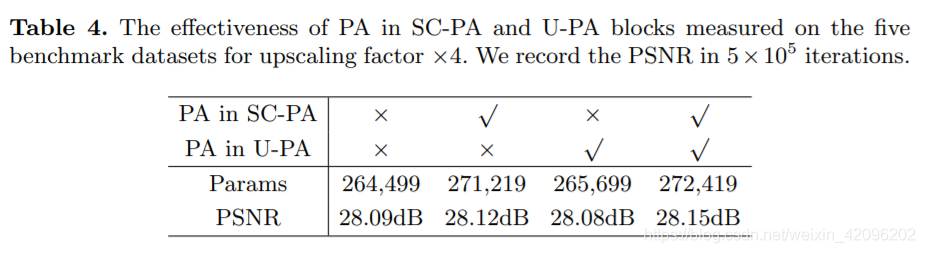
alec:
- 消融实验证明了PA的有效性
[√] 2.对比实验

alec:
- 对比实验表明,本文提出的PA和SC模块,能够在大大减少参数量的前提下,提高性能。
[√] 3.应用于大网络,效果会降低