本文最后更新于:3 个月前
[√] 5.5 - 实践:基于ResNet18网络完成图像分类任务
alec:
很多任务可以看做是图像分类任务,比如人脸检测可以看做检测是否是人脸的二分类任务
本节使用的优化器是adam优化器。
在本实践中,我们实践一个更通用的图像分类任务。
图像分类 (Image Classification)是计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。很多任务也可以转换为图像分类任务。比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
这里,我们使用的计算机视觉领域的经典数据集:CIFAR-10数据集,网络为ResNet18模型,损失函数为交叉熵损失,优化器为Adam优化器,评价指标为准确率。
Adam优化器的介绍参考《神经网络与深度学习》第7.2.4.3节。
[√] 5.5.1 - 数据处理 [√] 5.5.1.1 - 数据集介绍 CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为$32\times32$像素。CIFAR-10数据集的示例如 图5.15 所示。
将数据集文件进行解压:
1 2 3 4 5 10 -python.tar.gz -C /home/aistudio/datasets/
1 2 3 4 5 6 7 8 9 cifar-10 -batches-py/10 -batches-py/data_batch_410 -batches-py/readme.html10 -batches-py/test_batch10 -batches-py/data_batch_310 -batches-py/batches.meta10 -batches-py/data_batch_210 -batches-py/data_batch_510 -batches-py/data_batch_1
[√] 5.5.1.2 - 数据读取 在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。
训练集:40 000条样本。
验证集:10 000条样本。
测试集:10 000条样本。
读取一个batch数据的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osimport pickleimport numpy as npdef load_cifar10_batch (folder_path, batch_id=1 , mode='train' ):if mode == 'test' :'test_batch' )else :'data_batch_' +str (batch_id))with open (file_path, 'rb' ) as batch_file:'latin1' )'data' ].reshape((len (batch['data' ]),3 ,32 ,32 )) / 255. 'labels' ]return np.array(imgs, dtype='float32' ), np.array(labels)'datasets/cifar-10-batches-py' , 1 , mode='train' )
查看数据的维度:
1 2 print ("batch of imgs shape: " ,imgs_batch.shape, "batch of labels shape: " , labels_batch.shape)
1 batch of imgs shape: (10000 , 3 , 32 , 32 ) batch of labels shape: (10000 ,)
1万张图像,1万个分类标签,每张图像3个通道,像素为32*32
可视化观察其中的一张样本图像和对应的标签,代码如下所示:
1 2 3 4 5 6 7 8 %matplotlib inlineimport matplotlib.pyplot as plt1 ], labels_batch[1 ]print ("The label in the picture is {}" .format (label))2 , 2 ))1 ,2 ,0 ))'cnn-car.pdf' )
类别9是卡车
[√] 5.5.1.3 - 构造Dataset类 构造一个CIFAR10Dataset类,其将继承自paddle.io.Dataset类,可以逐个数据进行处理。代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import paddleimport paddle.io as iofrom paddle.vision.transforms import Normalizeclass CIFAR10Dataset (io.Dataset):def __init__ (self, folder_path='/home/aistudio/cifar-10-batches-py' , mode='train' ):if mode == 'train' :1 , mode='train' )for i in range (2 , 5 ):'train' )elif mode == 'dev' :5 , mode='dev' )elif mode == 'test' :'test' )0.4914 , 0.4822 , 0.4465 ], std=[0.2023 , 0.1994 , 0.2010 ], data_format='CHW' )def __getitem__ (self, idx ):return img, labeldef __len__ (self ):return len (self.imgs)100 )'/home/aistudio/datasets/cifar-10-batches-py' , mode='train' )'/home/aistudio/datasets/cifar-10-batches-py' , mode='dev' )'/home/aistudio/datasets/cifar-10-batches-py' , mode='test' )
[√] 5.5.2 - 模型构建 对于Reset18这种比较经典的图像分类网络,飞桨高层API中都为大家提供了实现好的版本,大家可以不再从头开始实现。这里首先使用飞桨高层API中的Resnet18进行图像分类实验。
1 2 3 from paddle.vision.models import resnet18
飞桨高层 API是对飞桨API的进一步封装与升级,提供了更加简洁易用的API,进一步提升了飞桨的易学易用性。其中,飞桨高层API封装了以下模块:
Model类,支持仅用几行代码完成模型的训练;
图像预处理模块,包含数十种数据处理函数,基本涵盖了常用的数据处理、数据增强方法;
计算机视觉领域和自然语言处理领域的常用模型,包括但不限于mobilenet、resnet、yolov3、cyclegan、bert、transformer、seq2seq等等,同时发布了对应模型的预训练模型,可以直接使用这些模型或者在此基础上完成二次开发。
飞桨高层 API主要包含在paddle.vision和paddle.text目录中。
[√] 5.5.3 - 模型训练 复用RunnerV3类,实例化RunnerV3类,并传入训练配置。 使用训练集和验证集进行模型训练,共训练30个epoch。 在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
alec:
什么是Adam优化器?
什么是L2正则化策略
什么是批量归一化?
评价指标函数中的is_logist=True参数是什么意思
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import paddle.nn.functional as Fimport paddle.optimizer as optfrom nndl import RunnerV3, metricTrue if paddle.get_device().startswith("gpu" ) else False if use_gpu:'gpu:0' )print ('------------------------------\n' )print (use_gpu)print ('------------------------------\n' )0.001 64 True )0.005 )True )3000 3000 30 , log_steps=log_steps, "best_model.pdparams" )
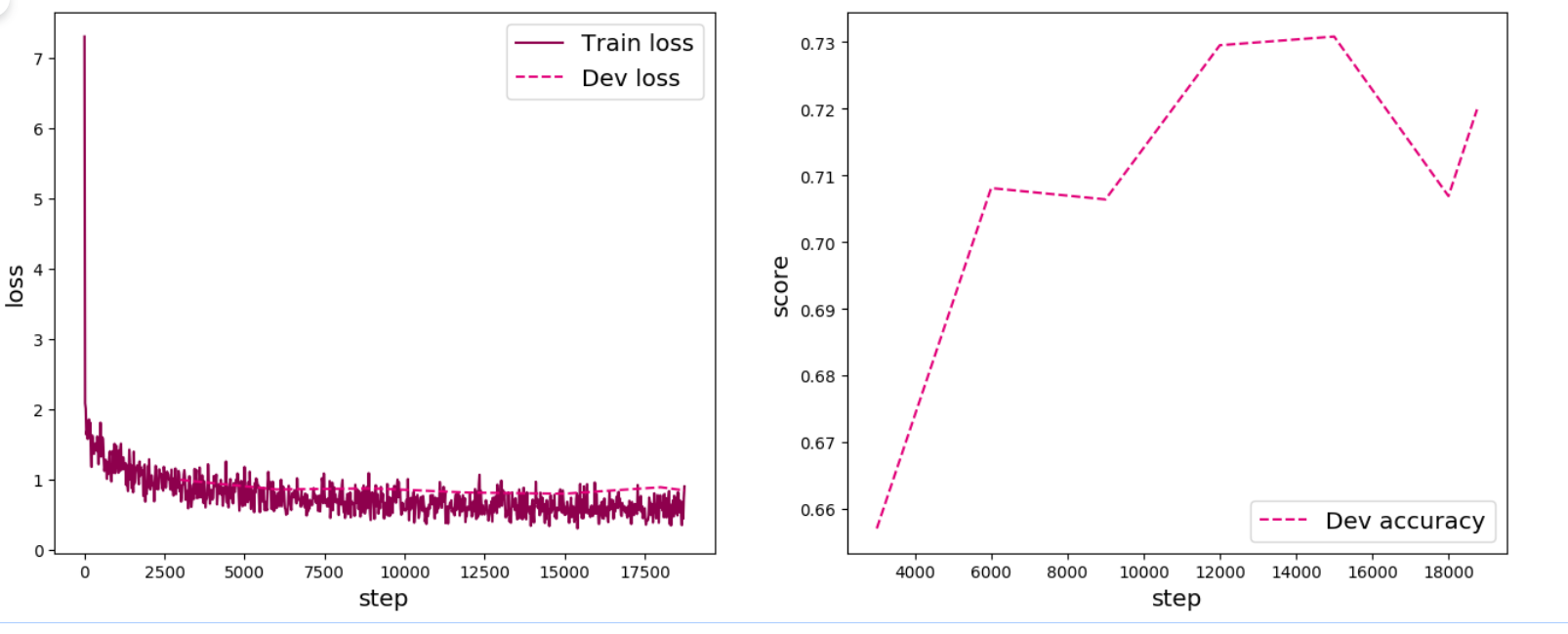
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 运行时长: 7 分钟8 秒92 毫秒2022 -12 -18 18 :59 :13 True 0 /30 , step: 0 /18750 , loss: 7.30469 .7 /site-packages/paddle/nn/layer/norm.py:653 : UserWarning: When training, we now always track global mean and variance."When training, we now always track global mean and variance." )4 /30 , step: 3000 /18750 , loss: 0.92417 0.65710 , dev loss: 0.99306 0.00000 --> 0.65710 9 /30 , step: 6000 /18750 , loss: 0.59166 0.70810 , dev loss: 0.85658 0.65710 --> 0.70810 14 /30 , step: 9000 /18750 , loss: 0.75011 0.70640 , dev loss: 0.87181 19 /30 , step: 12000 /18750 , loss: 0.57231 0.72950 , dev loss: 0.81165 0.70810 --> 0.72950 24 /30 , step: 15000 /18750 , loss: 0.49599 0.73080 , dev loss: 0.79610 0.72950 --> 0.73080 28 /30 , step: 18000 /18750 , loss: 0.60004 0.70690 , dev loss: 0.88804 0.71990 , dev loss: 0.84240
可视化观察训练集与验证集的准确率及损失变化情况。
1 2 3 from nndl import plot_training_loss_acc'cnn-loss4.pdf' )
在本实验中,使用了第7章中介绍的Adam优化器进行网络优化,如果使用SGD优化器,会造成过拟合的现象,在验证集上无法得到很好的收敛效果。可以尝试使用第7章中其他优化策略调整训练配置,达到更高的模型精度。
alec:
此处的优化器使用了Adam优化器,没有使用SGD这个随机梯度下降优化器,因此使用SGD会造成过拟合的现象,过拟合会导致在验证集上无法收敛,效果差。过拟合即过度拟合了训练数据集,泛化性查。
[√] 5.5.4 - 模型评价 使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失情况。代码实现如下:
1 2 3 4 5 'best_model.pdparams' )print ("[Test] accuracy/loss: {:.4f}/{:.4f}" .format (score, loss))
1 [Test] accuracy/loss: 0.7257 /0.8251
[√] 5.5.5 - 模型预测 同样地,也可以使用保存好的模型,对测试集中的数据进行模型预测,观察模型效果,具体代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 id2label = {0 :'airplane' , 1 :'automobile' , 2 :'bird' , 3 :'cat' , 4 :'deer' , 5 :'dog' , 6 :'frog' , 7 :'horse' , 8 :'ship' , 9 :'truck' }next (test_loader())2 ]).numpy()2 ][0 ].numpy()0 ]]0 ]]print ("The true category is {} and the predicted category is {}" .format (label, pred_class))2 , 2 ))'/home/aistudio/datasets/cifar-10-batches-py' , mode='test' )2 ].transpose(1 ,2 ,0 ))'cnn-test-vis.pdf' )
[√] 5.5.7 - 基于自定义的ResNet18网络进行图像分类实验 这里使用自定义的 Model_ResNet18 模型进行图像分类实验,观察两者结果是否一致。
[√] 5.5.7.1 - 模型训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import paddle.nn.functional as Fimport paddle.optimizer as optfrom nndl import RunnerV3, metric, opTrue if paddle.get_device().startswith("gpu" ) else False if use_gpu:'gpu:0' )0.001 64 True )3 , num_classes=10 , use_residual=True )0.005 )True )3000 3000 30 , log_steps=log_steps, "best_model.pdparams" )
[√] 5.5.7.2 - 模型评价 1 2 3 4 5 'best_model.pdparams' )print ("[Test] accuracy/loss: {:.4f}/{:.4f}" .format (score, loss))
可以看到,使用自定义的Resnet18模型与高层API中的Resnet18模型训练效果可以基本一致。
[√] 5.6 - 实验拓展