060 - 文章阅读笔记:【ELAN】比SwinIR快4倍,图像超分中更高效Transformer应用探索 - AIWalker
本文最后更新于:3 个月前
原文:
ELAN | 比SwinIR快4倍,图像超分中更高效Transformer应用探索 - AIWalker
2022-04-06 22:00
ps:本文为依据个人日常阅读习惯,在原文的基础上记录阅读进度、记录个人想法和收获所写,关于原文一切内容的著作权全部归原作者所有。
- 整理
“transformer用于超分,在计算自注意力的时候,计算量巨大。同时某些计算操作对于超分来讲可能是冗余的。”
具体来说,我们首先采用移位卷积(shift convolution)提取图像的局部结构信息同时保持与1×1卷积相当的复杂度;然后提出了一种GMSA(Group-wise Multi-scale Self-Attention)模块,它在不同窗口尺寸特征上计算自注意力以探索长程依赖关系。我们通过级联两个shift-conv与GMSA(它可以通过共享注意力机制进一步加速)构建一个高效ELAB模块。实验结果表明:相比其他Transformer方案,所提ELAN可以取得更佳结果,同时具有更低的复杂度。
【本文idea】
“shift conv:移位卷积提取局部信息。”
“GMSA:通过分组,在不同的窗口尺寸特征上计算自注意力,探索长程依赖关系。”“通过级联两个shift-conv与GMSA构建一个高效ELAB模块”
[√] 文章信息

论文题目:【ELAN】Efficient Long-Range Attention Network for Image Super-resolution
中文题目:用于图像超分辨率的高效远程注意力网络
论文链接:https://arxiv.org/pdf/2203.06697.pdf
论文代码:https://github.com/xindongzhang/ELAN
论文发表:ECCV 2022
尽管Transformer已经“主宰”了各大CV领域,包含图像超分领域(如SwinIR)。
但是Transformer中的自注意力计算量代价过于昂贵,同时某些操作对于超分而言可能是冗余的,这就限制了自注意力的计算范围,进而限制了超分性能。
本文提出了一种用于图像超分的高效长程距离网络ELAN(Efficient Long-range Attention Network)。具体来说,我们首先采用移位卷积(shift convolution)提取图像的局部结构信息同时保持与1x1卷积相当的复杂度;然后提出了一种GMSA(Group-wise Multi-scale Self-Attention)模块,它在不同窗口尺寸特征上计算自注意力以探索长程依赖关系。我们通过级联两个shift-conv与GMSA(它可以通过共享注意力机制进一步加速)构建一个高效ELAB模块。实验结果表明:相比其他Transformer方案,所提ELAN可以取得更佳结果,同时具有更低的复杂度。
[√] 1 Method

上图为ELAN整体架构示意图,一种类似EDSR的超分架构,核心模块即为ELAB。所以我们只需要对ELAB进行详细介绍即可,见下图。
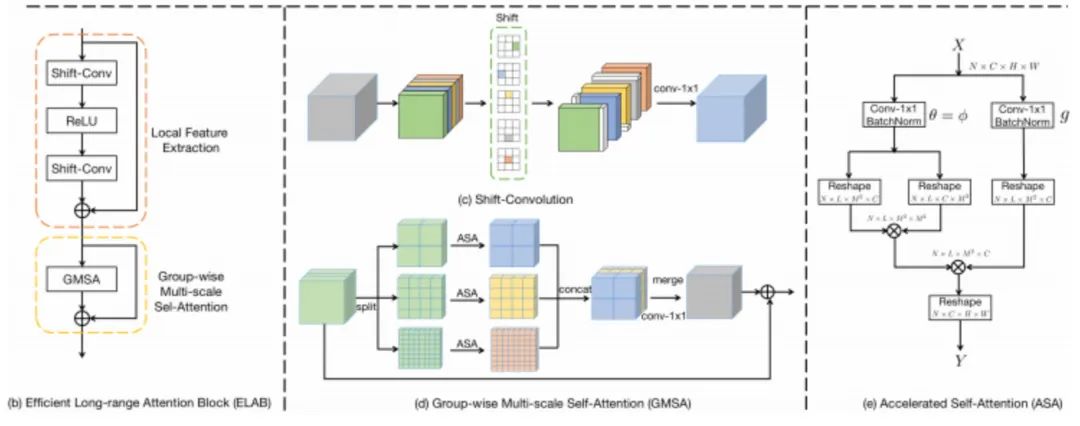
上图为ELAB的架构示意图,它包含一个局部特征提取模块与一个分组多尺度注意力GMSA模块,同时两个模块均搭载了残差学习策略。
Local Feature Extraction 在局部特征提取方面(见上图c),它采用两个shift-conv+ReLU组合进行处理。具体来说,shift-conv由四个shift操作与$1\times1$卷积组成,shift操作则旨在对输入特征进行上下左右移位,然后将所得五组特征送入后接$1\times1$卷积进行降维与信息聚合。无需引入额外可学习参数与计算量,shift-conv可以取得更大感受野($3\times3$)同时保持与$1\times1$卷积相当的计算量。
GMSA(Group-wise Multi-scale Self-Attention) 不同于常规自注意力,为更有效计算长程自注意力,我们提出了GMSA(见上图d)。它首先将输入特征分成K组,然后对不同组在不同窗口尺寸上执行自注意力,最后采用$1\times1$卷积对不同组所得特征进行信息聚合。
ASA(Accelerated Self-Attention) 相比常规自注意力,我们对其进行了一下几个改进:(1) 将LN替换为BN,这是因为LN对于推理并不友好,相反BN不仅可以稳定训练同时在推理阶段可以合并进卷积产生加速效果;(2)SwinIR中的自注意力是在嵌入高斯空间中进行计算,它包含三个独立1x1卷积,即
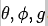 。而我们令
。而我们令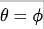 ,即自注意力在对称嵌入高斯空间中计算,这种处理可以节省一个1x1卷积,进一步缓解的自注意力的计算量与内存负载且不会牺牲超分性(见上图e)。
,即自注意力在对称嵌入高斯空间中计算,这种处理可以节省一个1x1卷积,进一步缓解的自注意力的计算量与内存负载且不会牺牲超分性(见上图e)。Shared Attention 为进一步加速自注意力计算,我们提出相邻自注意力模块共享注意力得分图,见下图。也就是说,第i个自注意力模块的注意力图直接被同尺度后接n个自注意力模块复用。通过这种方式,我们可以避免2n个reshape与n个1x1卷积。我们发现:所提共享注意力机制仅导致轻微性能下降,但它可以在推理阶段节省大量的计算资源。(alec:第i个自注意力模块计算出来的注意力权重,可以被同尺度的后面N个自注意力复用,后面的N个直接将这一批的注意力权重乘上V就可以了。)
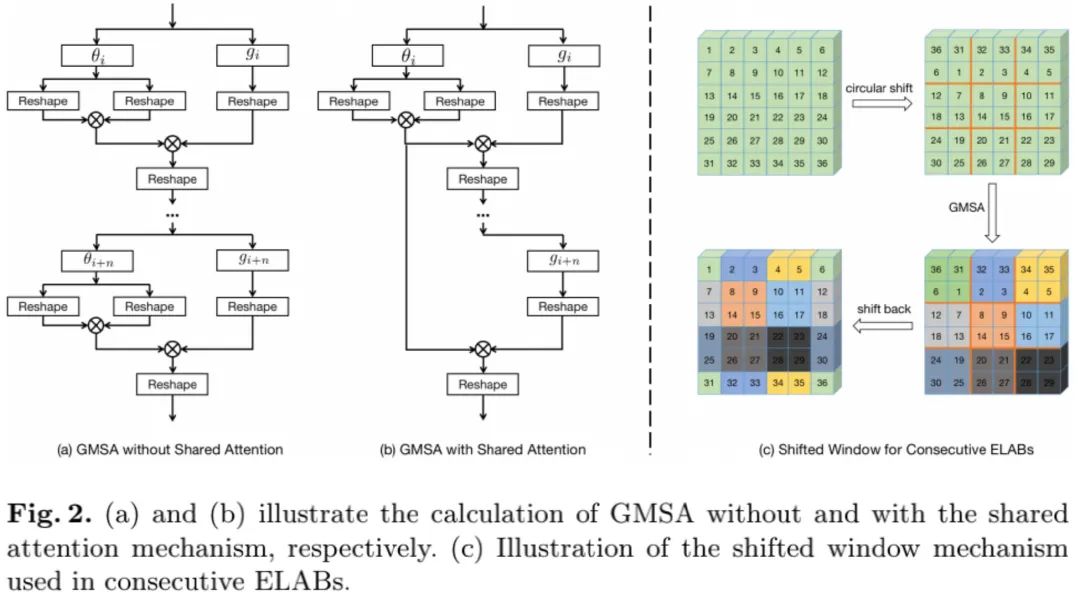
- Shifted Window 上述自注意力的计算机制缺乏窗口间的信息通讯,我们对SwinIR中的移位窗口机制进行了改进以达成适用于超分的简单且有效移位机制,见上图c。我们首先对特征进行对角线循环移位,然后在移位特征上计算GMSA,最后对GMSA的结果进行逆循环移位。受益于循环移位机制,我们移除了SwinIR中的掩码策略与相对位置编码,使得该网络更简洁高效。
[√] 2 Experiments
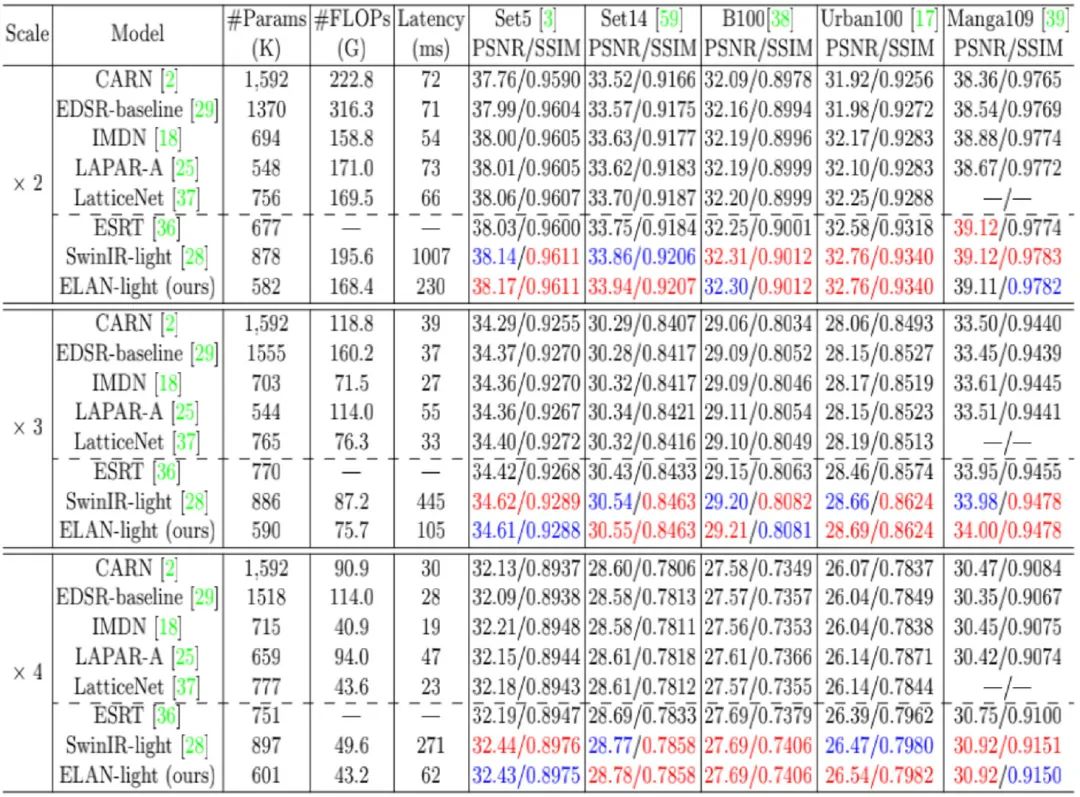

上表与图对比了不同轻量型超分方案的性能对比,从中可以看到:
- 在相似参数量与FLOPs下,Transformer方案具有比CNN方案更佳的指标,然而SwinIR-light的推理速度要比CNN方案慢10倍以上,这是因为SwinIR中的自注意力带来了严重的推理负载。
- 受益于所提高效长程注意力设计,ELAN-light不仅取得了最/次佳性能,同时具有比SwinIR-light快4.5倍的推理速度,同时参数量与FLOPs均少于SwinIR-light。
- 在重建视觉效果方面,CNN方案重建结果更为模块且存在边缘扭曲,而Transformer方案在结构重建效果更佳,ELAN是仅有可以重建主体结构的方案,证实了长程自注意力的有效性。
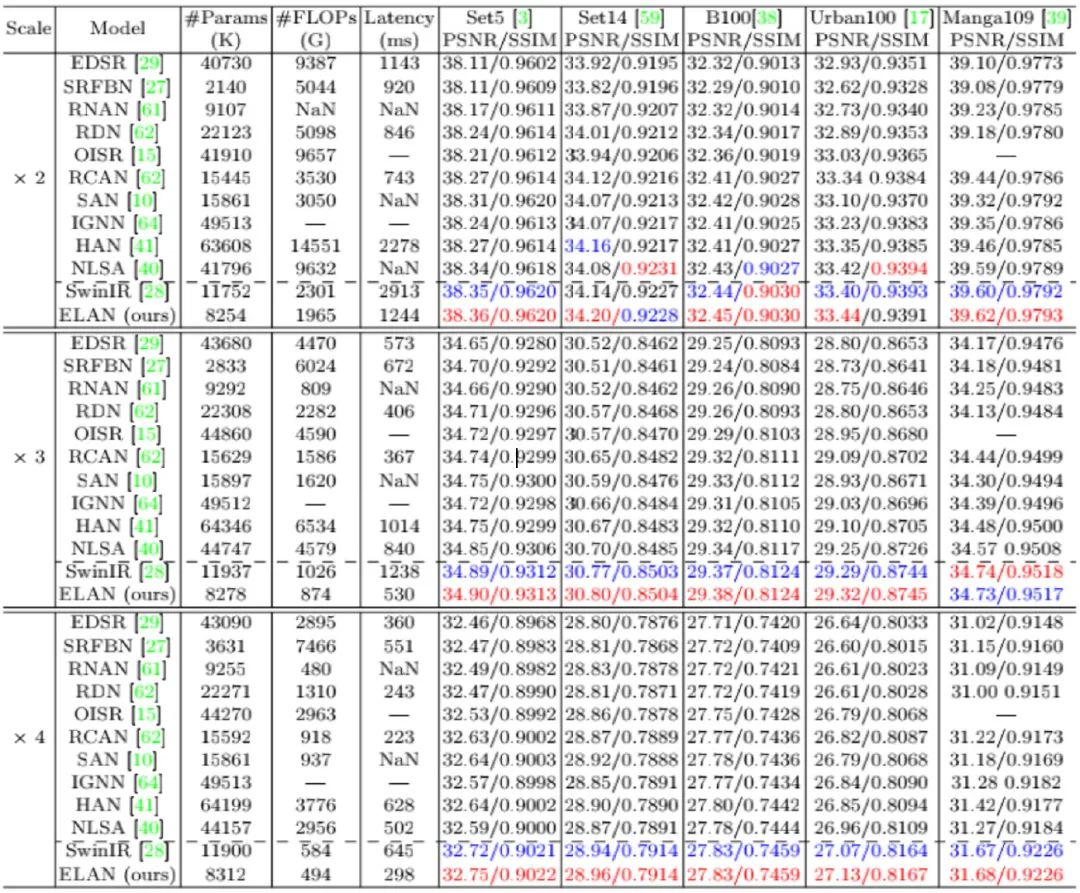

上图与表在更多超分方案进行了对比,从中可以看到:
- 在所有尺度与基准数据集上,ELAN均取得了最佳性能。
- 相比SwinIR,ELAN取得了最佳PSNR与SSIM,同时具有更少参数量与计算量、更快推理速度;
- 相比CNN方案,ELAN在重建性能方面局具有显著优势,这得益于大感受野与长程特征相关性建模。
- 尽管HAN与NLSA通过探索注意力机制与更深网络课要取得相当性能,但其计算量与内存负载非常昂贵。比如NLSA甚至无法在NVIDIA 2080Ti GPU上执行x2超分任务,而ELAN则可以凭借更少计算量取得比这些复杂方案更高的性能。
[√] 3 后记
看完ELAN后,关于GMSA的attention共享机制与shift-window深感疑惑:ELAB相邻模块之间可以公用attention map,但是相邻ELAB还要进行shift-windows操作,这个时候的attention还能直接用吗?直观上来看不能直接用了。百思不得其解之后小窗@新栋进行了请教并得到了如下方案:
ELAB这里有一个不同于SwinIR的实现小细节: shared的blocks是不做shift的,到下一个blocks进行shift。即,如果有8个block的话,我们的实现是12(non-shift),34(shift),56(non-shift),78(shift)。
[√] 4 推荐阅读
- CVPR2021|超分性能不变,计算量降低50%,董超等人提出用于low-level加速的ClassSR
- 让Dropout在图像超分领域重焕光彩!
- 图像增强领域大突破!以1.66ms的速度处理4K图像,港理工提出图像自适应的3DLUT
- ETH开源业内首个广义盲图像超分退化模型,性能效果绝佳
- ICCV2021 FBCNN: 超灵活且强度可控的盲压缩伪影移除新思路
- 超越SwinIR,Transformer再一次占领low-level三大任务
- 让Dropout在图像超分领域重焕光彩!
- 图像增强领域大突破!以1.66ms的速度处理4K图像,港理工提出图像自适应的3DLUT
- ETH开源业内首个广义盲图像超分退化模型,性能效果绝佳
- ICCV2021 FBCNN: 超灵活且强度可控的盲压缩伪影移除新思路